The Weekly Edge: Graph Analytics on DuckDB, Context Graphs, the Power of Librarians, & More [16 January 2026]
![The Weekly Edge: Graph Analytics on DuckDB, Context Graphs, the Power of Librarians, & More [16 January 2026]](https://gdotv.com/wp-content/uploads/2026/01/context-graph-analytics-duckdb-weekly-edge-16-january-2026.png "The Weekly Edge: Graph Analytics on DuckDB, Context Graphs, the Power of Librarians, & More [16 January 2026]")
The turning of the year is like the turning of an age (in January, at least): You don’t notice it when you zoom in close, but turn your back and it’s somehow been a week. That means it’s time for another edition of the Weekly Edge!
This regular blog series is like your personal digest of all things graph tech from the last week summarized in a single post and curated by the team here at G.V().
This week’s headlines have a bit of everything:
- A last holiday gift: TuringDB drops a new Community Edition from its sleigh
- A year in the rearview: How the ArcadeDB team shifted into high gear in 2025
- The Librarian’s Tale: We’ve over-indexed on data storage
- Onager catapults onto the scene: A new graph analytics extension for DuckDB
- It’s those Context Graphs, they’re so hot right now: Will Lyon shows you how and why
- First years, this way: If you’re new to graph databases, do I have the book for you
Let’s dive in.
[Release:] TuringDB Community Edition Has Arrived
Over the past few months, the TuringDB team has been quietly building something new in the background, but now it’s ready for prime time. Earlier this week, they officially released TuringDB Community Version, the open source edition of their high-performance, versioned graph database.
The brand-new Community Version is designed for data and engineering teams to:
- Benchmark traversal speed on real datasets
- Stress test real-time graph workloads
- Experiment with first-of-its-kind graph versioning for auditability and time-travel analytics
Find the new release here on GitHub or dive into the docs to learn more about graph versioning.
According to the announcement on LinkedIn, the TuringDB team has a strong feature pipeline ahead, and 2026 will be a pivotal year as they continue redefining high-performance graph infrastructure. We’re looking forward to it.
[Read:] An ArcadeDB Year in Review: Performance, Connectivity, & Modernization

2025 was the year ArcadeDB shifted into high gear, and this week’s first read tells you the story of how they locked in and made it happen.
The ArcadeDB team started the year by modernizing their database foundation and ended it by pushing the boundaries of vector search and remote connectivity. A few of their major milestones included:
- Next-Gen Vector Search
- Python Embedded Bindings
- Advanced SQL & Schema Capabilities
- RID Recycling, allowing the full reuse of deleted space and recycling of Record IDs (RIDs)
They credited the big boost in feature development to their growing community who welcomed numerous new contributors in the past year. Teamwork makes the dream work!
[Watch:] Graph Chat with Jessica Talisman on Semantic Systems & the Power of Librarians
Why is modern AI so unruly? According to information architect and Librarian of All Knowledge Jessica Talisman, it’s because we’ve over-indexed on data storage and ignored the art of description.
In this Graph Chat video interview for GraphGeeks, I spoke with Jessica (Founder of the Ontology Pipeline) to discuss the bridge between Labeled Property Graphs (LPG) and RDF, the rise of neuro-symbolic AI, and why every tech company needs the perspective of a “Chief Librarian.”
Check out Jessica’s Substack Intentional Arrangement for more perspectives on the importance of ontologies, knowledge graphs, taxonomies, and more. Also, big thanks to Amy Hodler for arranging the interview series and to Michelle Yi for helping with the camera work! 🎥
[Release:] Onager: A DuckDB Extension for Graph Analytics
Here’s a wild-ass idea: Graph analytics on DuckDB. Not so wild-ass, actually, thanks to Hassan Abedi.
Onager is a DuckDB extension that adds a large number of graph analytics functions to DuckDB, including centrality measures, community detection algorithms, pathfinding algorithms, graph metrics, and graph generators. Onager is written in Rust and uses the Graphina graph library under the hood.
Compared to DuckPGQ, Onager is focused on graph analytics instead of graph querying. While DuckPGQ implements SQL/PGQ (a.k.a. the SQL:2023 standard) for graph pattern-matching and path-finding queries with a property graph model, Onager provides a collection of ready-to-use graph algorithms (like PageRank, Louvain community detection, Dijkstra’s shortest path, etc.) as simple table functions.
I sorta already called it, but I’m definitely calling it now: DuckDB will become the DuckDB of graph databases.
[Read:] Hands On with Context Graphs & Neo4j
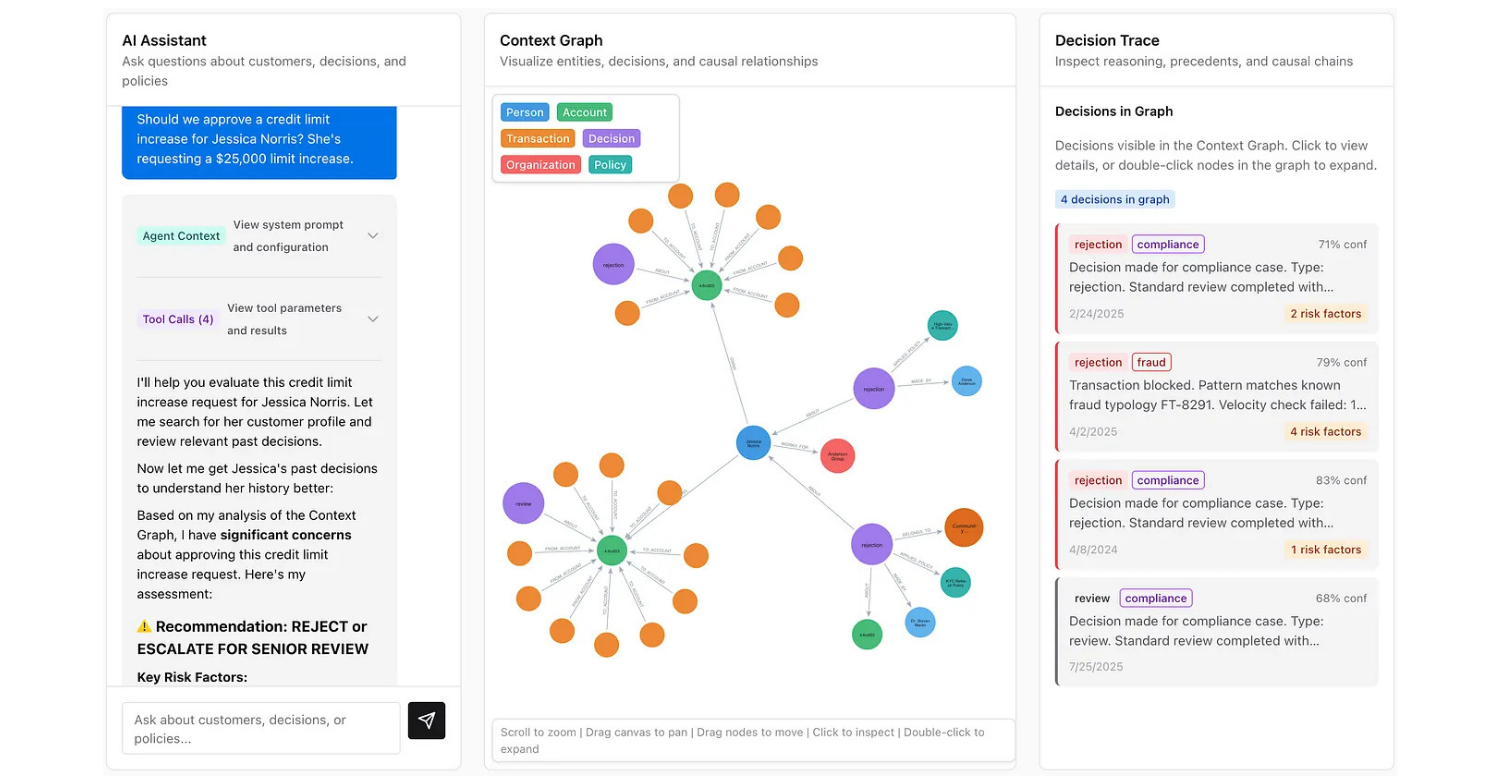
If you’ve been around graph databases for a while, then context graphs aren’t a particularly new concept. But if you’re tuning in from the AI bubble, then context graphs are all the rage right now – and deservedly so.
My former Neo4j colleague William Lyon breaks it down: Traditional databases are designed around a fundamental assumption that what matters is what’s true right now. This is what is known as the State Clock – a snapshot of current reality. For decades, it was enough.
But AI agents are changing everything. They need a different kind of data structure, one that captures the Event Clock – what happened, when it happened, and why. Enter, context graphs.
[Book/ICYMI:] Graph Databases for Beginners

This one’s an oldie but a goldie. Back in the twenty-teens when I was working for Neo4j, my intern at the time, Joy Chao, and I wrote a book: Graph Databases for Beginners.
What better way to kick off your new year than by mastering the basics of graph tech with a retro book that covers the fundamentals and gets you up to speed? It was a rhetorical question. There is no better way.
Here’s a little excerpt from book to get you intrigued:
Whether you’re a business executive or a seasoned developer, something – maybe a business challenge or a task your current database can’t handle – has led you on the quest to learn more about graph technology and what it can do.
In Graph Databases For Beginners, we’ll take you through the basics of graph database technology assuming you have little (or no) background in the space. We’ll also include some useful tips that will help you if you decide to make the switch to Neo4j.
Before we dive in, what is it that makes graphs not only relevant, but necessary in today’s world? The first is their focus on relationships. Collectively we are gathering more data than ever before, but more and more frequently it’s how that data is related that is truly important.
Grab your free copy and let me know what you think!
P.S. Did you miss my interview with LadybugDB founder Arun Sharma? Well, here’s your chance to catch up with our Graph Chat on embedded graph databases.
Got something you want to nominate for inclusion in a future edition of the Weekly Edge? Ping us on on X | Bluesky | LinkedIn or email weeklyedge@gdotv.com.


