Hey! I'm Arthur Bigeard, the founder of gdotv Ltd.
I'm a former Identity & Access Management developer with a heavy background in cyber security.
I've developed a passion for Graph Databases and the Apache TinkerPop ecosystem in particular over the last few years which I've channeled into the making of our flagship product, G.V().
G.V() 3.6.26 is out and brings massive changes to our software. For the first time since we’ve released G.V(), we are now expanding our support to new graph database query languages, starting with openCypher for Amazon Neptune & PuppyGraph. This new version is the first of a series of releases that will expand the reach of our graph database client beyond the Apache TinkerPop ecosystem.
We’ll also cover some recent 3.x release improvements that were not covered in previous announcements.
A quick recap of the 3.x releases
G.V() is changing rapidly – to support that evolution, we’ve undertaken substantial behind the scene work which was released over the Summer as part of our 3.0 update. You currently know our software to be a desktop-only executable. We will maintain this deployment model, but also introduce a new Docker version in the near future. Such has been the purpose of the 3.0 release.
That’s not all that’s changed however, so here’s a quick fire round of improvements we’ve added:
Improved application performance and reduced memory footprint
Improved query editor look and feel, and autocomplete engine accuracy
Updated JSON output format to be more inline with various database provider output formats
The Azure Cosmos DB JSON Output now matches the output returned by the database itself for better consistency
Cypher support for Amazon Neptune & PuppyGraph
Cypher is one of the most popular graph query languages out there. It’s a declarative query language initially developed by Neo4j that shares strong similarities with SQL, arguably the best known database query language of all. Cypher has branched off to an open-source implementation called openCypher which many graph database providers have adopted either as their primary language or to complement their main language.
We’ve set out to bring openCypher support to G.V(), giving users more flexibility in how they can query their database. Today, we offer this support for Amazon Neptune & PuppyGraph which both offer an openCypher API concurrent to their Gremlin API.
Simply put, you can now write and run Cypher queries on G.V() just the same way we’ve supported it so far for the Gremlin query language, without any additional configuration required. Download the latest version of G.V() and you’re good to go!
Our query editor now offers the option to choose between Cypher and Gremlin for databases that support it. You can seamlessly switch between both languages, access the same advanced auto completion features we offer for Gremlin, and visualize your query results the same way you’ve been able to so far for Gremlin.
Running a Cypher query on Amazon Neptune using G.V(), with autocomplete and advanced results visualization
Graph view improvements
We’ve added some quality of life features and improvements to our graph view, to provide a better, more versatile experience to users.
Centering of the camera to the layout applied on the graph is now more accurate, and ensures that the optimal zoom level is applied no matter the size of the graph. The animations applied to reposition nodes after layout are smoother, and the graph can be rotated 90 degrees in any direction to give you more flexibility on how you want it displayed. We’ve also introduced a new horizontal tree layout which is best suited to hierarchical data structures.
Running layouts and positioning the graph now runs much smoother
Query Editor changes
Aside from the ability to switch between Cypher and Gremlin query languages whilst writing queries, you can now also specify a query timeout to ensure that your query does not exceed a threshold of your choice.
We’ve also updated the look and feel of the UI to provide the same useful information in a more compact format, creating more space on screen to write complex queries.
What’s next for G.V()?
With G.V() 3.x, we’re embarking on the next stage of growth for our software. We will continue to expand support further to new graph database providers, starting with Neo4j’s AuraDB, Desktop and self-hosted editions. Once that support is released, we will be turning our attention to ISO GQL (Graph Query Language) with the aim to provide the first fully featured graph database client for GQL.
Other Cypher-enabled graph database providers will be progressively added to the roster of available technologies in G.V(), such as Memgraph. If there’s a graph database provider you’re specifically interested in seeing in G.V() (or if you work on a database you’d like to see us support!) give us a holler at support@gdotv.com. Our ultimate goal is for G.V() to be the only graph database client you’ll ever need.
We’re not just looking to expand compatibility to other databases – a crucial goal as part of the 3.x release was to make G.V() deployable not just as a desktop executable, but also as a fully fledged web application using Docker. We will initially launch the web version of our software on AWS Marketplace in the coming months so that you and your team can collaborate directly on a single deployment of our software. Stay tuned for more news early next year.
In this article we’ll showcase a first of its kind Graph analytics engine that transform and unify your relational data stores into a highly scalable and low-latency graph. I present to you: PuppyGraph!
Introduction
This is going to be a part-tutorial, part technical deep dive into this unique technology. By the end of this article you will have your own PuppyGraph Docker container running with a sample set of data loaded for you to explore and interact with using G.V(), or PuppyGraph’s own querying tools. Best part is, this is all free to use and will only take a few minutes to setup. Let’s go!
What is PuppyGraph?
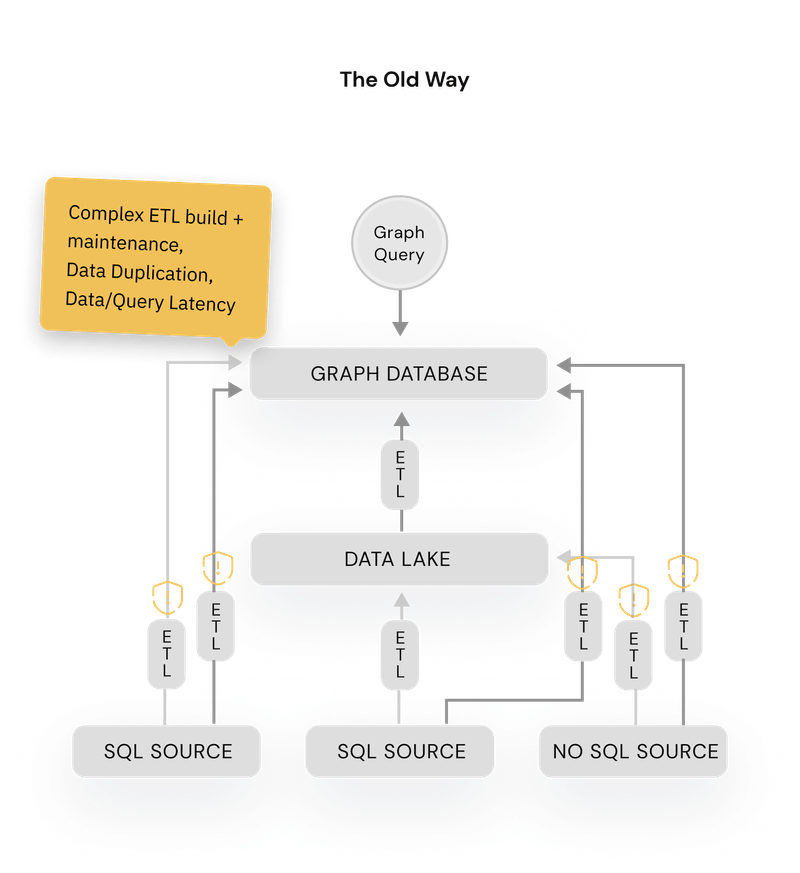
PuppyGraph is a deployable Graph Analytic Engine that aggregates disparate relational data stores into a queryable graph, with zero ETL (Extract, Transform, Load) requirements. It’s plug and play by nature, requiring very little setup or learning: deploy it as a Docker container or AWS AMI, configure your data source and data schema, and you’ve got yourself a fully functional Graph Analytics Engine.
The list of supported data sources is long and growing. At time of writing PuppyGraph supports all of the below sources:
PuppyGraph’s unique selling point is to deliver all the benefits of a traditional graph database deployments without any of the challenges:
Complex ETL: Graph databases require building time-consuming ETL pipelines with specialized knowledge, delaying data readiness and posing failure risks.
Scaling challenges: Increasing nodes and edges complicate scaling due to higher computational demands and challenges in horizontal scaling. The interconnected nature of graph data means that adding more hardware does not always translate to linear performance improvements. In fact, it often necessitates a rethinking of the graph model or using more sophisticated scaling techniques.
Performance difficulties: Traditional graph databases can take hours to run multi-hop queries and struggle beyond 100GB of data.
Specialized graph-modeling knowledge requirements: Using graph databases demands a foundational understanding of mapping graph theory and logical modeling to an optimal physical data layouts or index. Given that graph databases are less commonly encountered for many engineers compared to relational databases, this lower exposure can act as a considerable barrier to implementing an optimal solution with a traditional graph database.
Interoperability issues: Tool compatibility between graph databases and SQL is largely lacking. Existing tools for an organization’s databases may not work well with graph databases, leading to the need for new investments in tools and training for integration and usage.
Because a picture speaks a thousand words, PuppyGraph illustrates these pain-points and how they’re with a simple side-by-side comparison of how you would aggregate your relational data without PuppyGraph versus using PuppyGraph, and it says it all:
Why does PuppyGraph exist and why is it more performant than a traditional graph database?
So PuppyGraph suggests that more than 90% of Graph use cases involve analytics, rather than transactional workloads. And the data leveraged in these analytical use cases tend to already exist in an organisation in some form of column-based storage, typically SQL. This is simply due to the fact that SQL systems are ubiquitous, thanks to their long history in the database and data warehouse markets.
With that data already in place and accessible, leveraging it directly at the source with no ETL means that you’re no longer copying the data into a graph, instead merely wrapping your data sources with a graph query engine.
Aside from the obvious zero ETL factor, there is another considerable performance optimisation being leveraged directly as part of your graph analytics. In graph, accessing a single node or edge requires loading all of their attributes in memory due to their placement on the same disk page, which leads to a higher memory consumption. By leveraging column-based storage, graph queries run by PuppyGraph can restrict their access to just the necessary attributes, which optimizes in turn the disk-access and memory storage required to evaluate a query. And therein lies the secret sauce.
Under the hood
So how does it work? You may think that PuppyGraph is merely translating your graph queries into SQL queries for the underline data sources – but it doesn’t. Instead, PuppyGraph performs all optimisations directly within its own query engine, restricting its SQL footprint to simple SELECT queries, e.g. SELECT name, age FROM person WHERE filter1 AND filter2.
You do of course need to tell PuppyGraph how to access your data sources, what tables you’re interested in accessing and what relationships between those tables are going to become the edges of your graph. This is done via a Schema configuration file, in which you’ll need to configure 3 sections:
catalogs: This is going to be your list of data sources. A data source consists of a name, credentials, database driver class and jdbc URI
vertices: this is the translation layer between your database tables and your vertices. Each vertex is mapped from a catalog, a schema and a table. Simply put, a table should map to a vertex, and its columns to vertex properties, with a name and a type. In other words, your columns ARE your vertex properties, and you can pick which ones to include as part of your vertex.
edges: this is translation layer that leverages the relationships of your relational data, and maps them into edges. Think simple: its (mostly) going to be foreign keys. You can even map attributes to your edges from columns of your related tables.
To illustrate this, see below a simple schema mapping two PostgreSQL tables into two vertices and an edge:
And there you have it! The schema file below would result in the following Graph data schema:
Now that we’ve covered the theory, let’s jump to practice with a step by step guide to create, configure and query your first Graph Analytics Engine using PuppyGraph and G.V().
Setting up your first PuppyGraph container
For simplicity, we’ll run a local instance of PuppyGraph together with a PostgreSQL database using Docker Compose. If you haven’t already, install Docker. Once installed, create a docker-compose.yaml file with the following contents (or download it here):
You’ll also need to create a couple folders with sample data and a Postgres Schema file to create your Postgres table. These files will be mounted to your Postgres Docker container.
Create a new postgres-schema.sql file in the same folder as your docker-compose-puppygraph.yaml file with the following contents (or download it here):
create schema supply;
create table supply.customers (id bigint, customername text, city text, state text, location_id bigint);
COPY supply.customers FROM '/tmp/csv_data/customers.csv' delimiter ',' CSV HEADER;
create table supply.distance (id bigint, from_loc_id bigint, to_loc_id bigint, distance double precision);
COPY supply.distances FROM '/tmp/csv_data/distance.csv' delimiter ',' CSV HEADER;
create table supply.factory (id bigint, factoryname text, locationid bigint);
COPY supply.factory FROM '/tmp/csv_data/factory.csv' delimiter ',' CSV HEADER;
create table supply.inventory (id bigint, productid bigint, locationid bigint, quantity bigint, lastupdated timestamp);
COPY supply.inventory FROM '/tmp/csv_data/inventory.csv' delimiter ',' CSV HEADER;
create table supply.locations (id bigint, address text, city text, country text, lat double precision, lng double precision);
COPY supply.locations FROM '/tmp/csv_data/locations.csv' delimiter ',' CSV HEADER;
create table supply.materialfactory (id bigint, material_id bigint, factory_id bigint);
COPY supply.materialfactory FROM '/tmp/csv_data/materialfactory.csv' delimiter ',' CSV HEADER;
create table supply.materialinventory (id bigint, materialid bigint, locationid bigint, quantity bigint, lastupdated timestamp);
COPY supply.materialinventory FROM '/tmp/csv_data/materialinventory.csv' delimiter ',' CSV HEADER;
create table supply.materialorders (id bigint, materialid bigint, factoryid bigint, quantity bigint, orderdate timestamp,
expectedarrivaldate timestamp, status text);
COPY supply.materialorders FROM '/tmp/csv_data/materialorders.csv' delimiter ',' CSV HEADER;
create table supply.materials (id bigint, materialname text);
COPY supply.materials FROM '/tmp/csv_data/materials.csv' delimiter ',' CSV HEADER;
create table supply.productcomposition (id bigint, productid bigint, materialid bigint, quantity bigint);
COPY supply.productcomposition FROM '/tmp/csv_data/productcomposition.csv' delimiter ',' CSV HEADER;
create table supply.products (id bigint, productname text, price double precision);
COPY supply.products FROM '/tmp/csv_data/products.csv' delimiter ',' CSV HEADER;
create table supply.productsales (id bigint, productid bigint, customerid bigint, quantity bigint,
We’re now ready to start the engine! On your command line prompt, at the folder location of your docker-compose-puppygraph.yaml file, run the following command:
docker compose -f puppygraph/docker-compose-puppygraph.yaml up
Give Docker a few minutes to pull the images and create your containers, and you’ll have the following running on your device:
Loading Relational Data and Turning it into a Graph
Next, we need to load data in our PostgreSQL database and tell PuppyGraph about it. To load the data, run the following commands:
Then, head on over to localhost:8081 to access the PuppyGraph console. You’ll be prompted to sign in. Enter the following credentials and click Sign In:
Username: puppygraph
Password: puppygraph123
After that, you’ll be presented with a screen with an option to upload your Graph Data Schema. Download our pre-made graph data schema configuration file here, click Choose File, then Upload. PuppyGraph will perform some checks and in just a minute you should be presented with the following on your screen:
Your PuppyGraph instance is now ready to be queried with G.V() (or using PuppyGraph’s internal tooling)!
Connecting G.V() to PuppyGraph
So first off, make sure to download and install G.V(), which will only take a minute. Open G.V() and click on “New Database Connection”. Select PuppyGraph as the Graph Technology Type, and enter localhost as the Hostname/IP Address, then click on Test Connection. Next, you’ll be prompted for your PuppyGraph credentials, which are the same as earlier (puppygraph/puppygraph123). Click on Test Connection again, and you’re good to go! Click on Submit to Create the Database Connection.
You’ll be prompted to sign up for a 2 weeks trial – enter your details, get your validation code via email, and then we’re ready to start. If you’d rather not share your details, click on the close button for the application and you’ll be offered to get an anonymous trial instead, which will apply immediately. With that done, you’re all set!
Getting insights from your shiny new PuppyGraph instance with G.V()
With all that hard work done, we’re ready to write some cool Gremlin queries to apply the benefits of your PuppyGraph Analytics Engine to relational data.
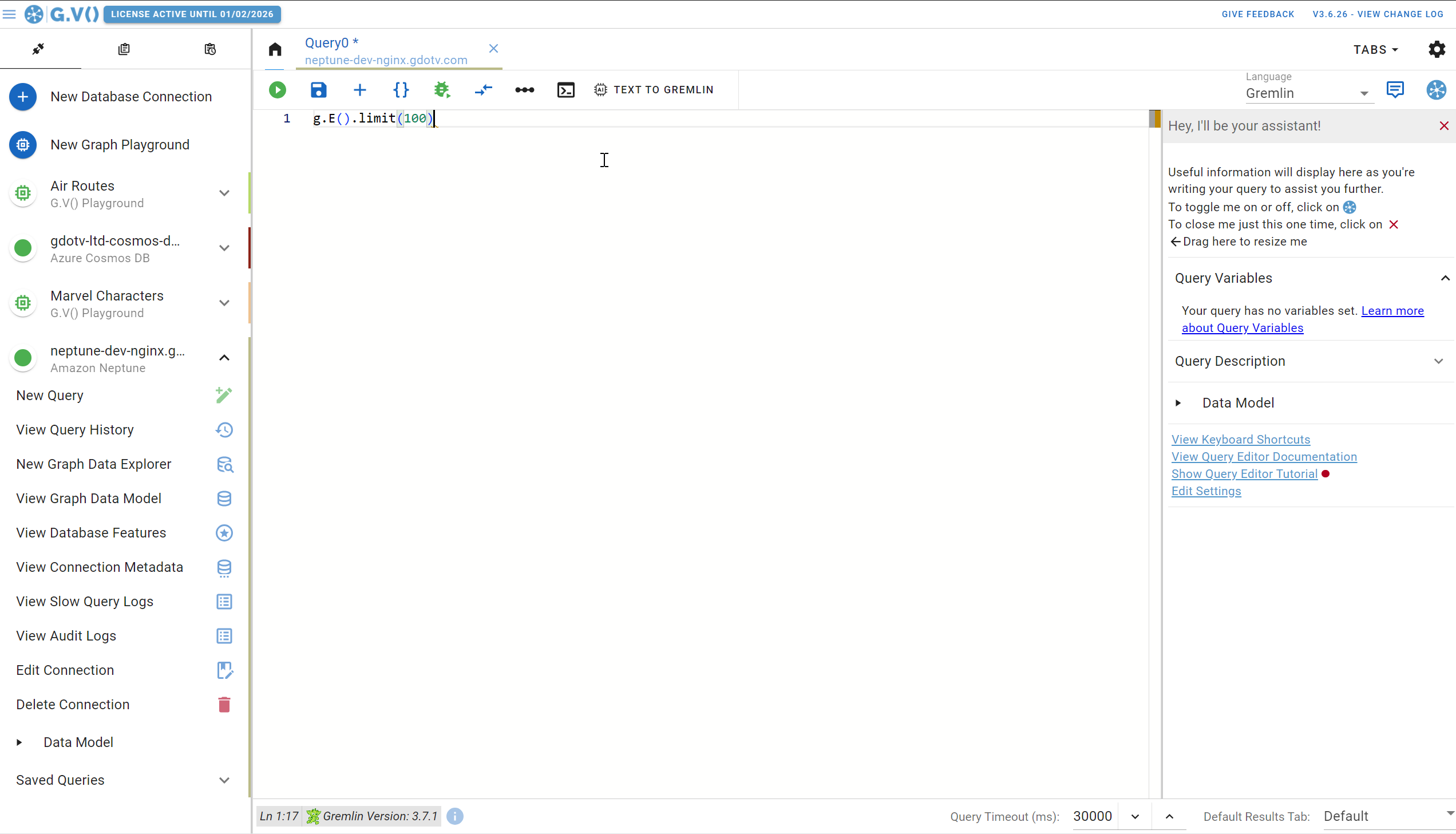
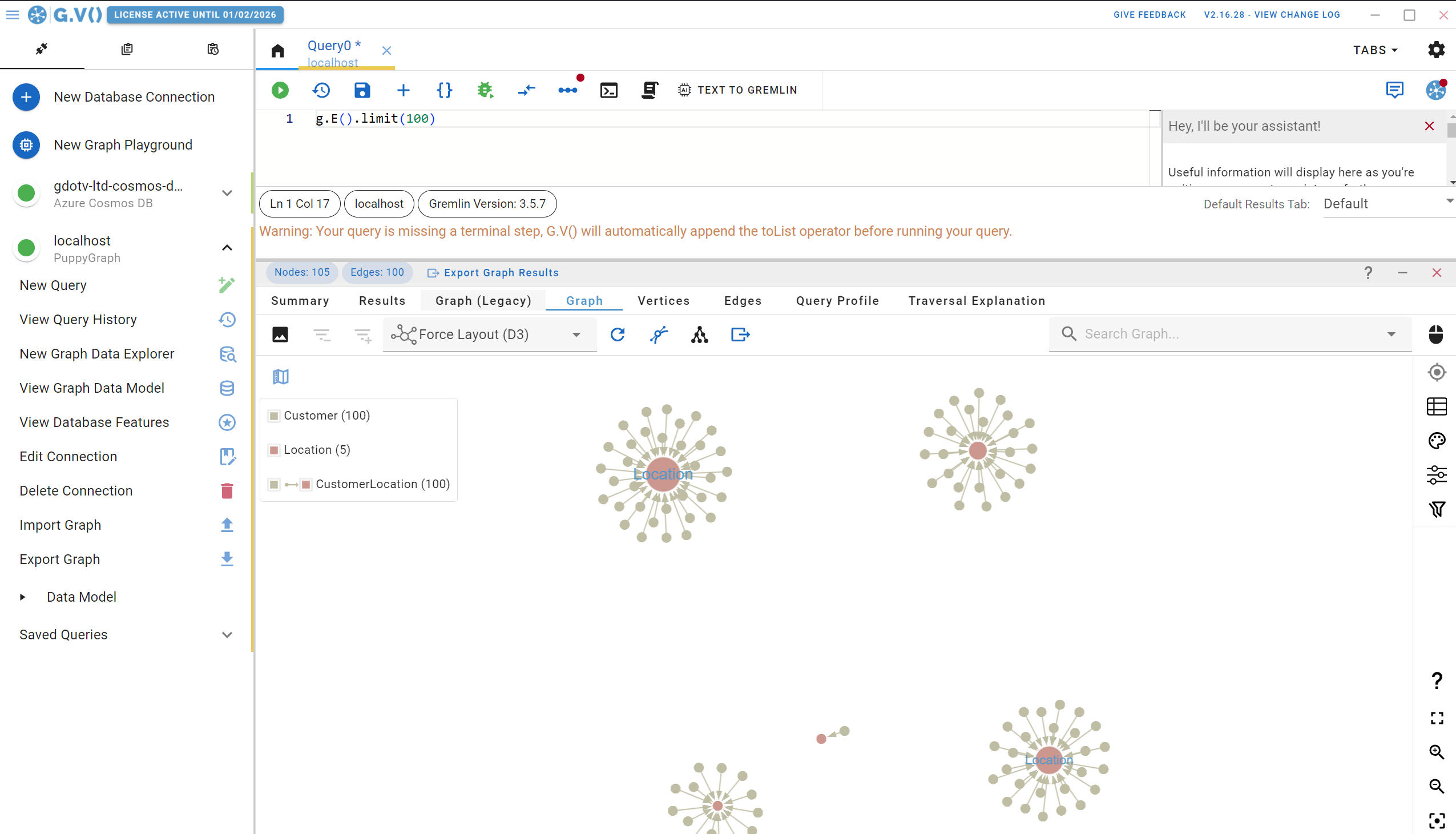
You’ll first notice a query tab opened with a simple query running, g.E().limit(100), and corresponding graph display, as shown below:
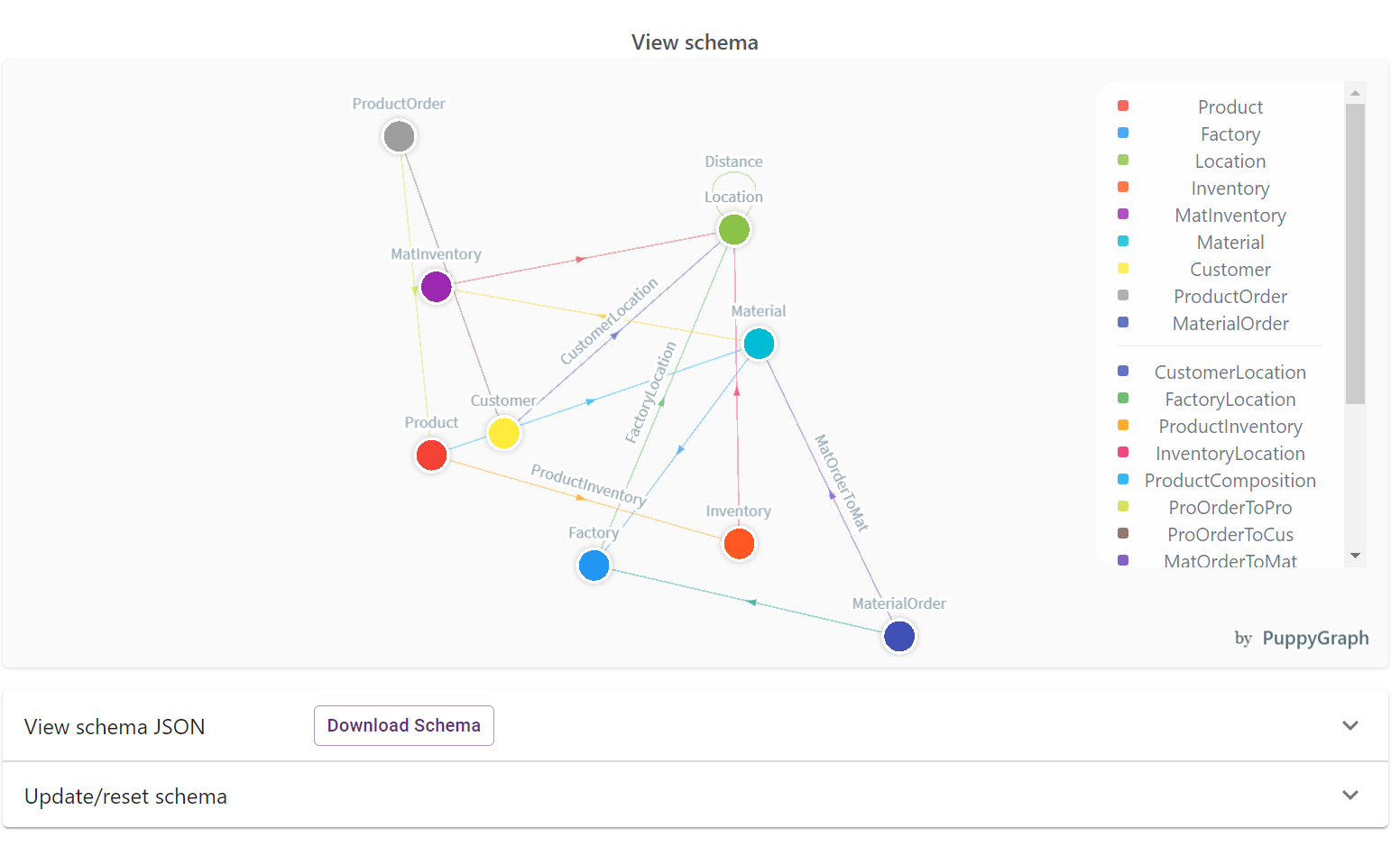
There’s a lot going on in this screen and we’ll come back to that. For now, let’s check out the Entity Relationships diagram G.V() has created for your PuppyGraph data schema. On the left handside, click on View Graph Data Model, and you’ll be presented with the following:
The Entity Relationship diagram G.V() provides gives you an easy way to inspect the structure of your data. This becomes especially useful when mixing multiple data sources in your PuppyGraph data schema as the resulting schema would be different from the individual data models of your data sources. Anyway, the added benefit of G.V() knowing your data schema is that it can also use it to power a whole bunch of features, such as smart autocomplete suggestions when writing queries, or graph stylesheets to customise the look and feel or your displays.
What’s important here is to realise what huge benefits a graph structure brings to your relational data. Let’s take a real life example applied to this dataset and compare how a graph query would perform against a normal SQL query. The dataset we’re using here is a supply chain use case. Unfortunately sometimes in a supply chain, a material can be faulty and lead to downstream impact to our customers.
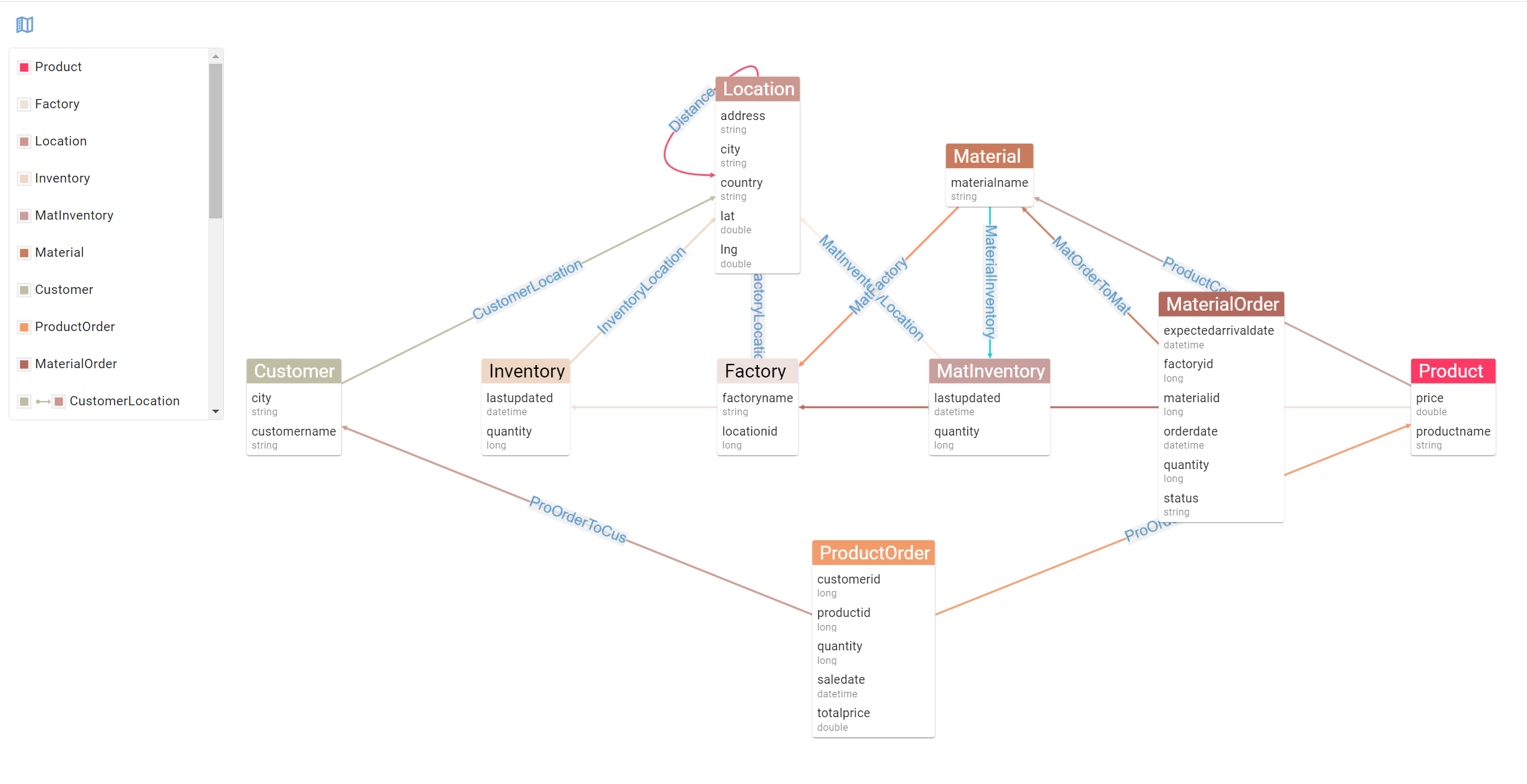
Let’s say as an example that a Factory has been producing faulty materials and that we need to inform impacted customers of a product recall. To visualise how we might solve this querying problem, let’s filter down our data model to display the relevant entities and relationships we should leverage to get the right query running:
Using this view allows use to see the path to follow from Factory to Customer. This concept of traversing a path in our data from a point A (a factory putting out faulting materials) to point B (our impacted customers) is fundamental in a graph database. Crucially, this is exactly the type of problems graph analytics engine are built to solve. In an SQL world, this would be a very convoluted query: a Factory joins to a Material which joins to a Product which joins to a ProductOrder which joins to a Customer. Yeesh.
Using the Gremlin querying language however, this becomes a much simpler query. Remember that unlike relational databases, where we select and aggregate the data to get to an answer, here we are merely traversing our data. Think of it as tracing the steps of our Materials from Factory all the way to Customer. To write our query, we will pick “Factory 46” as our culprit, and design our query step by step back to our customers.
In Gremlin, we are therefore picking the vertex with label “Factory” and factoryname “Factory 46”, as follows:
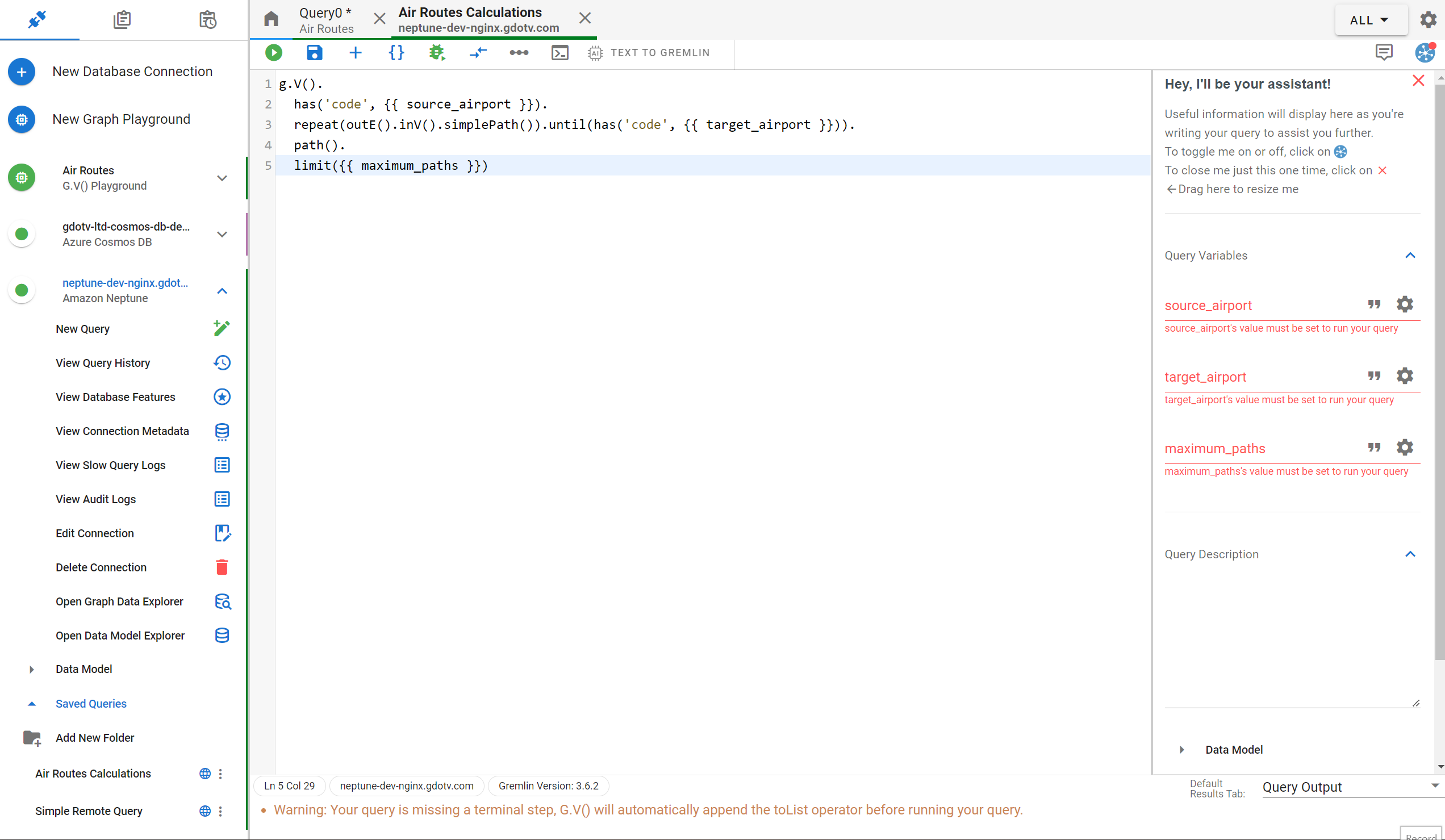
g.V().has("Factory", "name", "Factory 46")
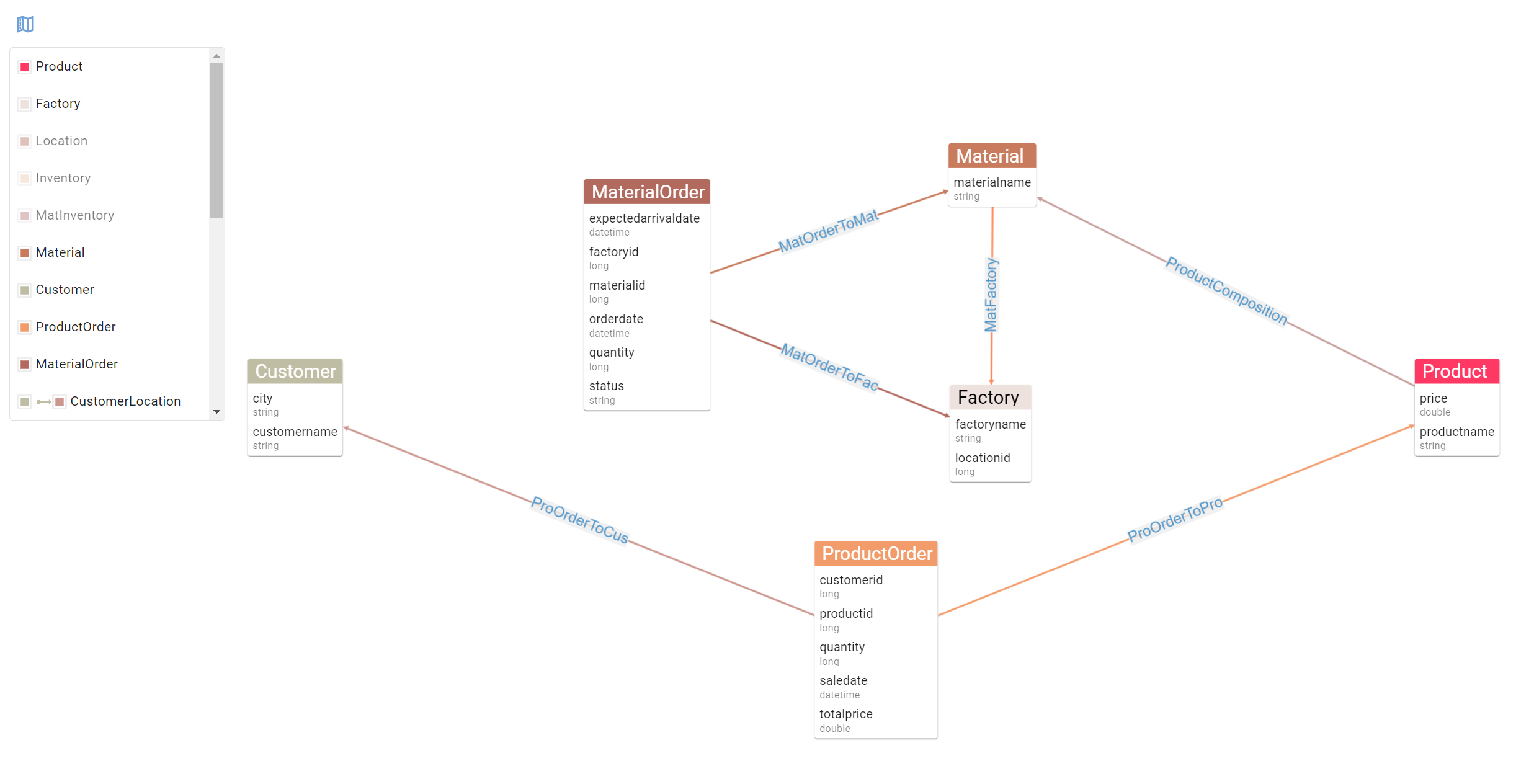
This is our starting point in the query, our “Point A”. Next, we simply follow the relationships displayed in our Entity Relationship diagram leading to our unlucky Customers.
To get the materials produced by the factory, represented as the MatFactory relationship going out of Material into Factory, we simply add the following step to our query:
And there you have it! This query will return the Customer vertices that have bought products made up of materials manufactured in Factory 46. Best of all, it fits in just one line!
Let’s punch it in G.V() – this will be an opportunity to demonstrate how our query editor’s autocomplete helps you write queries quick and easy:
We can of course create more complex queries to answer more detailed scenarios – for instance, in our example above, we could narrow down to a single faulty material or only recall orders made at a specific date.
The Gremlin querying language offers advanced filtering capabilities and a whole host of features to fit just about any querying scenario. G.V() is there to help you with the process of designing queries by offering smart suggestions, embedded Gremlin documentation, query debugging tools and a whole host of data visualisation options. If you’re interested in a more in depth view of G.V(), check out our documentation, our blog and our website. We also regularly post on upcoming and current developments in the software on Twitter/X and LinkedIn!
Conclusion
PuppyGraph has built an amazing solution to transform your relational data stores into a unified graph model in just minutes. It’s scalable to petabytes of data and capable of executing 10-hop queries in seconds. Their graph analytics engine is trusted by industry leaders such as Coinbase, Clarivate, Alchemy Pay and Protocol Labs. If you’ve got this far, you’ve now got a working setup combining PuppyGraph and G.V() – go ahead and try it on your own data!
Hello hello! I’m excited to announce the latest release of G.V(), 2.16.27, packed full of user experience/quality of life improvements for the software as well as some extra goodies.
Free trials are now up to a month!
So far, to allow users to trial G.V() Pro, we’ve been offering a 2 weeks trial which should give most people enough time to play with all of its features. We’ve also been offering users the option to get in touch with us directly to get an extension of typically 2 more weeks. We recognise that not everyone wants to have to ask and more importantly that sometimes during the trial things can get hectic and take the focus away from using our software.
For that reason, we’ve introduced a trial extension feature directly within G.V() – once your trial expires, you’ll be offered to extend it immediately in just one click. The best part is, you don’t even have to ask us anymore! If you aren’t on 2.16.27 yet, simply update G.V() and you’ll be offered the option to get your extensions as shown below:
We hope that this will take the stress of making the best of those 2 weeks out and give you more flexibility as well. You can also still sign up for a new trial every 3 months.
The Query Editor is getting a makeover
From its first release, G.V() used a popular text editor, CodeMirror, to provide its query editing features and various output displays (JSON, Console, Query Profile, etc). We recognise that a familiar user interface is essential to give users a better experience and so for that reason we’ve migrated all CodeMirror components to Monaco, Visual Studio Code’s own text editor. Aside from the sharp look and feel of VSCode, this change brings a whole host of new features and improvements:
All default VSCode keyboard shortcuts are now available to use (indent, comment, find & replace, etc)
Considerable performance improvements particularly on large JSON displays
Minimaps are now available on large text contents
JSON formatting and folding of objects/lists is more intuitive to use
With Monaco’s extensive highlighting and widget features, we can now insert more useful content into the text editor
To demonstrate these new capabilities, we’ve got you another animation, as usual!
Everything else
Aside from the above, we’ve also got a handful of small bug fixes and minor user experience improvements. One notable change is that we’ve now renamed the Graph (Advanced) View to just Graph View, and renamed the older graph view to just Graph (Legacy). As we continue to bring improvements and feature parity to our SigmaJS graph visualisation, the CytoscapeJS version (the legacy view) will eventually be fully replaced.
For a full list of changes, see the changelog below:
What else is cooking?
As previously mentioned we’ve got some big features in the works, and we’re looking at an announcement in July. Meanwhile, we’ll soon be introducing a new advanced custom authentication options allowing to you to generate credentials and authentication headers based on an external process. This is too support scenarios where your database access is protected in more complex ways, for instance with Google Cloud Identity-Aware proxy.
This article will cover how to connect your locally running Amazon Neptune database powered by LocalStack using G.V() – Gremlin IDE. To support this, we’ll use the AWS CLI to create a Neptune database on your local machine and start a connection while loading and querying data interactively on G.V().
Introduction
Before we start, let’s quickly introduce LocalStack, Amazon Neptune, and G.V().
LocalStack is a cloud development framework which powers a core cloud emulator that allows you to run your cloud & serverless applications locally. It helps developers work faster by supporting them to build, test, and launch applications locally — while reducing costs and improving agility. The emulator supports various AWS services like S3, Lambda, DynamoDB, ECS, and Kinesis. LocalStack also works with tools and frameworks like AWS CLI, CDK, and Terraform, making it easy for users to connect to the emulator when building and testing cloud apps.
Amazon Neptune is a managed graph database service designed to handle complex datasets with many connections. It’s schema-free and uses the Neptune Analytics engine to quickly analyze large amounts of graph data, providing insights and trends with minimal latency. Users can control access using AWS IAM and query data using languages like TinkerPop Gremlin and RDF 1.1 / SPARQL 1.1.
LocalStack supports Amazon Neptune as part of its core cloud emulator. Using LocalStack, you can use Neptune APIs in your local environment supporting both property graphs and RDF graph models.
G.V() is a Gremlin IDE – its purpose is to complement the Apache TinkerPop database ecosystem with software that is easy to use and install, and provides essential facilities to query, visualize, and model the graph data. If you want to find out more about G.V(), check out From Gremlin Console to Gremlin IDE with G.V().
Prerequisites
gdotv and LocalStack have partnered to offer a free trial of both LocalStack’s core cloud emulation and G.V() that you can take advantage of now if you haven’t already!
Install G.V(): Download and install for free from https://gdotv.com.
Install AWS CLI and awslocal: Download the AWS CLI as described in the AWS documentation, and install the awslocal wrapper script to re-direct AWS API calls to LocalStack.
Once you’ve done all the above, you’ll be ready to connect G.V() to your database and run queries.
Connecting G.V() to your LocalStack Neptune Database
Connecting G.V() to your LocalStack Neptune Graph database is quick and easy.
To create a LocalStack Neptune Graph database, follow these steps:
Start your LocalStack instance using either localstack CLI or a Docker/Docker-Compose setup.
Create a LocalStack Neptune cluster using Amazon’s CreateDBCl3uster API with the AWS CLI:
After starting the LocalStack Neptune database, you can see the Address and Port in the Endpoint field. Navigate to the G.V() IDE and follow the instructions:
Click on New Database Connection.
Choose the Graph Technology Type as LocalStack.
Enter localhost.localstack.cloud as the hostname and 4510 as the port. Customize the values if you have a different hostname and port.
Click on Test Connection. G.V() will make sure it can connect to your LocalStack Neptune database. It will then present a final screen summarizing your connection details, which you can now save by clicking Submit.
This will transition to a new query window. Now that your LocalStack Neptune database is up and running in G.V(), let’s run some Gremlin queries:
We’re only beginning to see the potential of LocalStack Neptune and G.V() when used together. This post shows how you can easily start working with setting up LocalStack Neptune on G.V() and running basic Gremlin queries. LocalStack also supports other AWS services, which allows you to test integrations supported by Neptune and shift left your database development without maintaining additional dependencies or mocks.
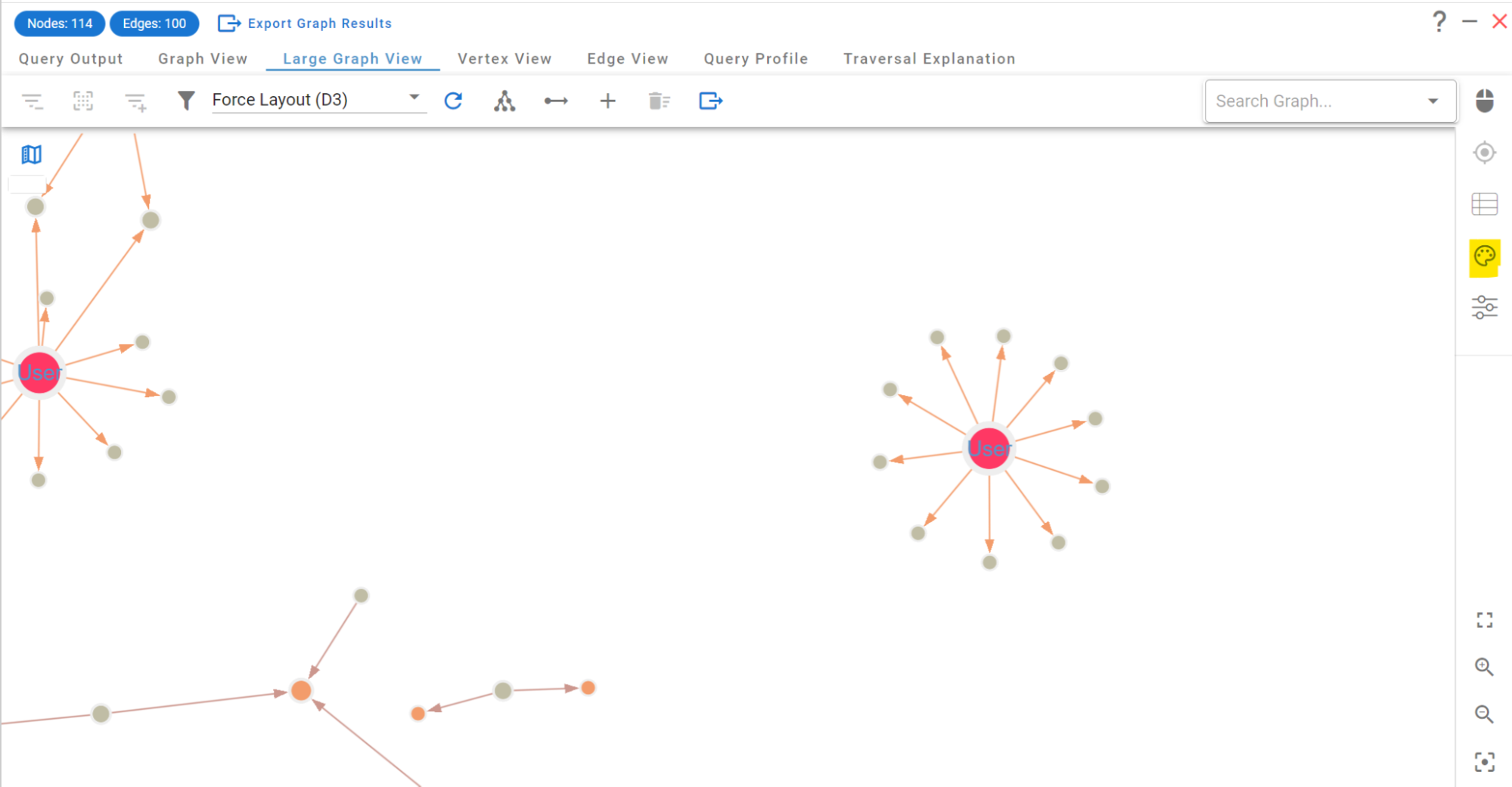
Today’s update announcement is actually a batch of the last two feature releases (2.5.9 and 2.10.17) which happened just a couple weeks apart of each other. The focus of both of these updates is mostly on the Large Graph View and its performance.
New Graph Filtering and Navigation options
As part of release 2.5.9, two new major features have been added to the Large Graph View to allow more advanced filtering and navigation options: the graph filtering view and the vertex neighbors highlighting tool.
Graph Filtering View
The purpose of this view is simple: to provide new filtering capabilities built upon the data available in your graph. To do so, we now leverage element property values to display filtering and element selection options. It also allows quickly determining the spread of values for a given property on a vertex or edge.
As always a picture is worth a thousand words and we’ve made a quick animation highlighting these new capabilities which you can check out below:
The filtering view includes a few nifty features to assist with navigation, such as the ability to sort filters by name or size and a search bar so you can quickly get to the property value you’re looking for. It’s a really powerful tool that also allows for some quick insights on your graph, so make sure to try it out!
Vertex Neighbors Highlighting
We’ve reworked and improved the neighbor navigation and highlighting tools available on G.V() to provide a more advanced and insightful experience. Previously, G.V() allowed incrementally selecting neighbors for a vertex but the UI was somewhat hidden and unclear. To remediate this, we’ve added a new tab under the Vertex Details tab as shown below:
This new capability calculates the maximum number of consecutive hops via a neighbor’s edges and their consecutive vertices and edges to reach the farthest (and closest) points of the graph from the currently selected vertex.
Each calculated hop then contains a report of which vertices can be found at that hop as well as how much of the graph they cover.
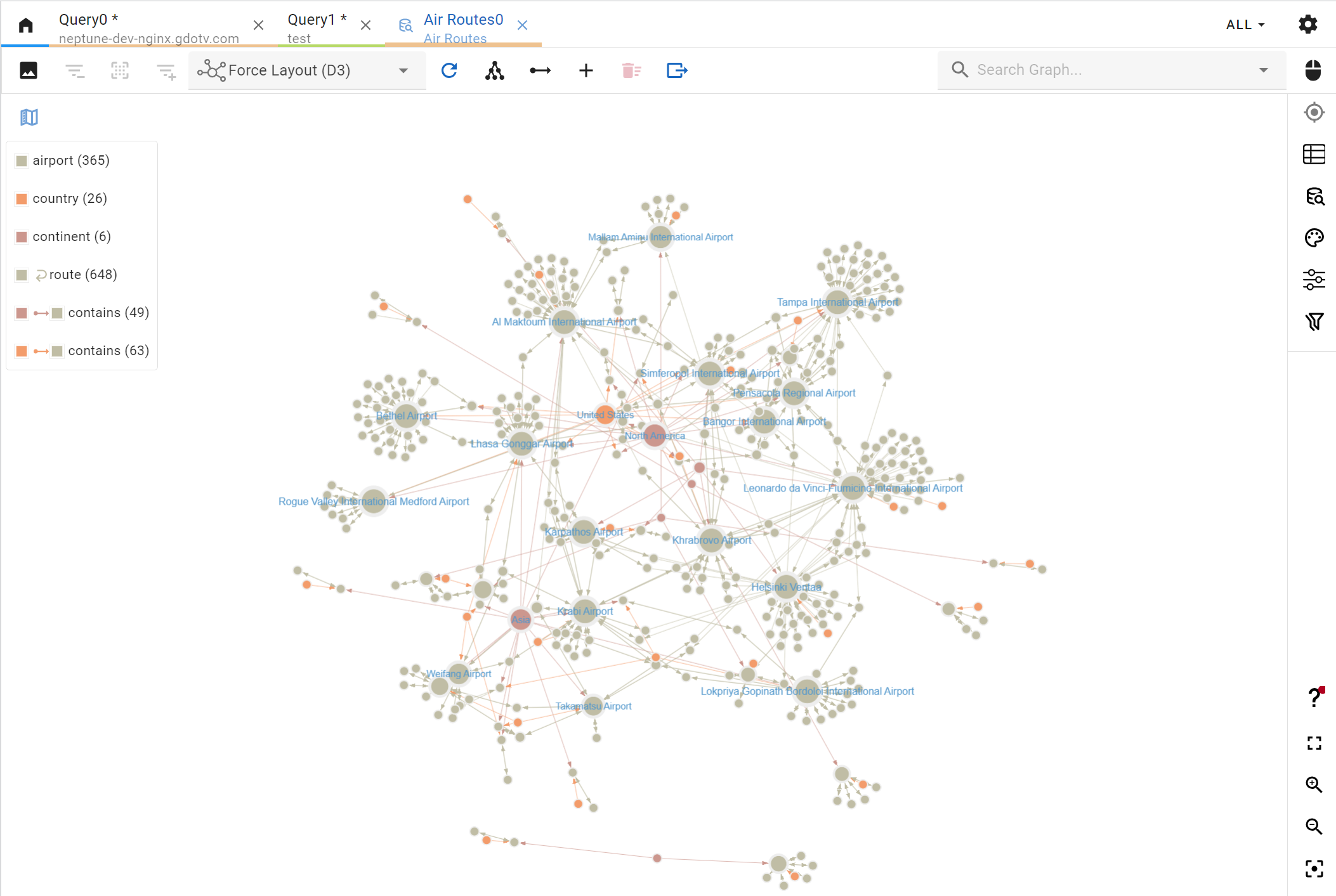
We’ve got another animation to illustrate this functionality further, shown below:
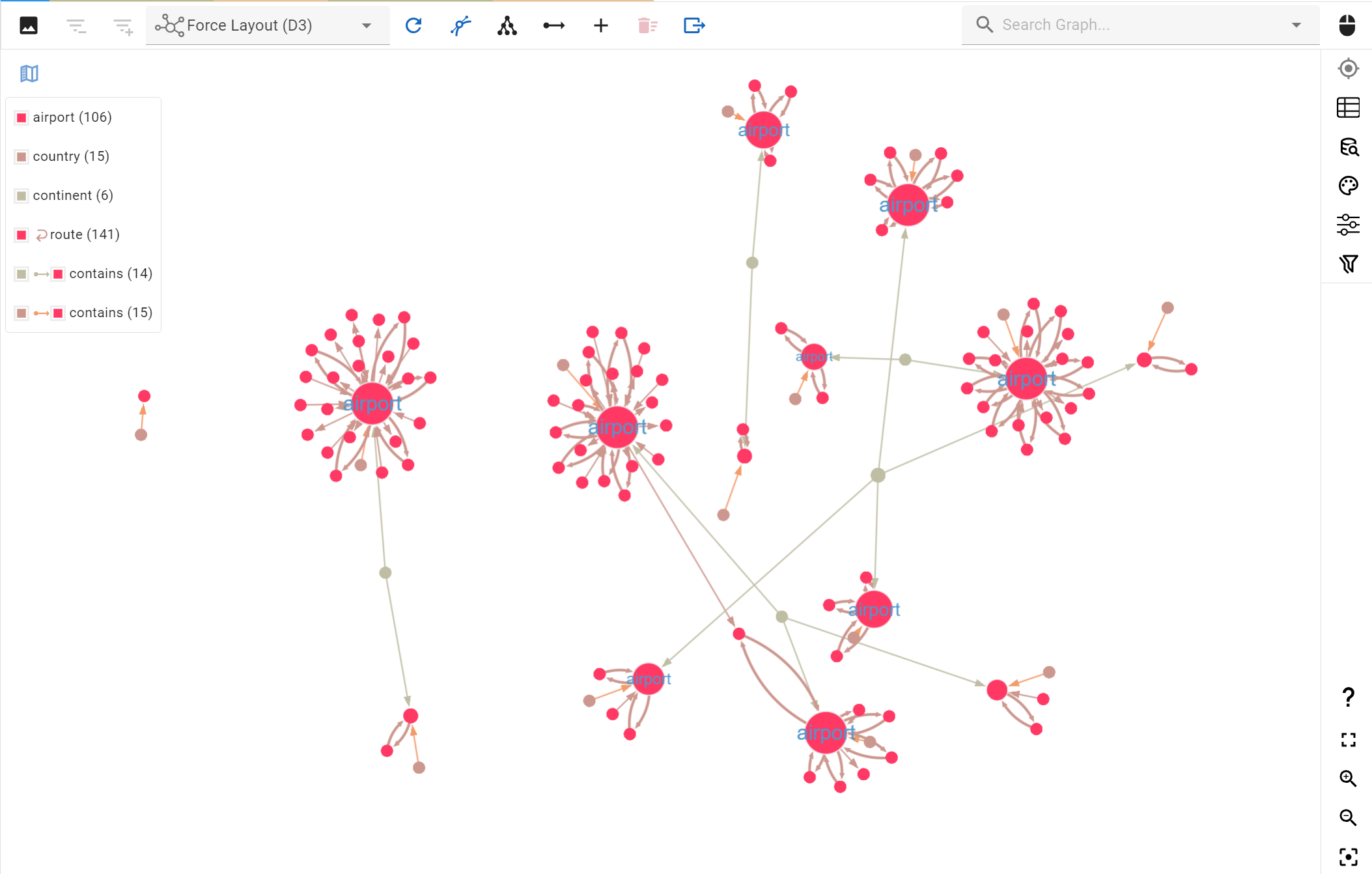
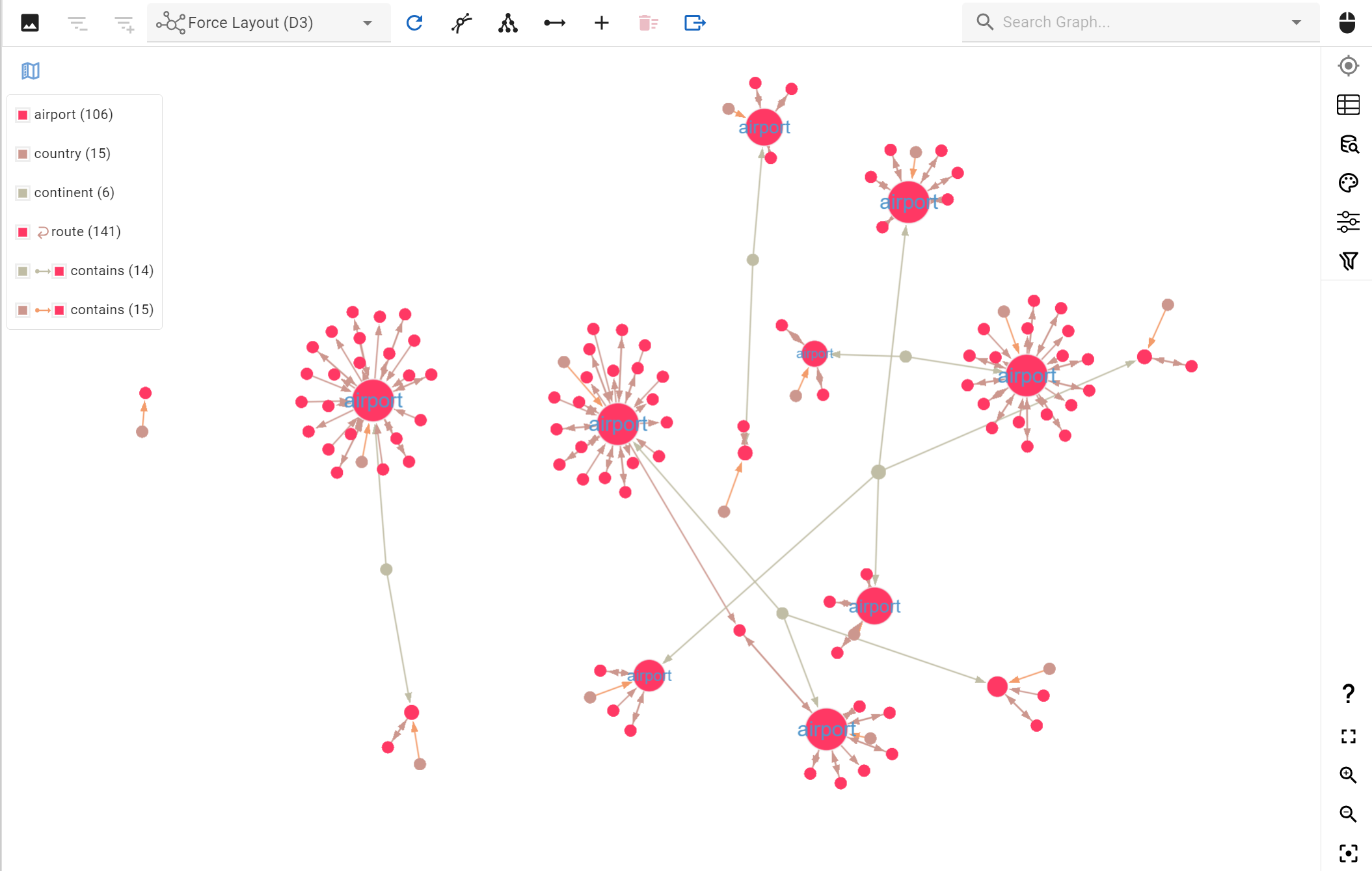
The example above is pretty insightful as it pertains to airports, countries and routes between them. It allows viewing how many hops (in this case airplane route) are required to travel from one country or airport to any airport, country or continent shown on the graph. Note that in this example for brevity only a subset of all airports and routes are showing but this should give you a good idea of where this tool can be effective in delivering visual insights from your graph.
Advanced Corporate Proxy Configuration Options
Some of our users, maybe yourself, need to deploy and use G.V() within a fairly airtight environment. Sometimes this would require the use of a corporate proxy of which your graph databases may be hidden behind. This new release of G.V() finally brings full proxy support to allow connecting to any graph database behind a proxy, through a set of new options that can easily be configured and detailed in our documentation.
Large Graph View Performance and UX improvements
The Large Graph View is a core component of G.V() that we’ve been continuously investing in since we first introduced it in 2022. It is powered by the SigmaJS graph visualization library (and it’s sister graph library, Graphology). Earlier this year, the SigmaJS team has announced the release of its long awaited v3, which we have proudly supported and sponsored. If you’re interested in building graph visualization then you simply must check SigmaJS/Graphology – it’s free and open-source!
This new v3 SigmaJS version is of course relevant to this post as we’ve now officially upgraded G.V() to use it, and it brings significant performance improvements as well as new rendering capabilities to provide a more versatile visual experience to the framework. The goal of these improvements is to allow SigmaJS (and therefore G.V()) to render more elements, faster, and increase the speed of processing graph updates for re-renders (e.g. when switching stylesheets in G.V()).
We’ve taken the opportunity with upgrading to SigmaJS v3 to also review the rendering of element labels to give them a crisper look and feel. Most important however is that with this new release, SigmaJS finally supports the drawing of curved edges. This may seem like a small change but it is extremely useful for graphs that contain many bidirectional relationships, as these were previously difficult to tell apart visually in G.V(), as shown in the comparison below:
A graph display with curved edgesThe same display without curved edges
With this new capability it’s now much easier to understand relationships in complex, highly interconnected graphs.
This is our first big project with the SigmaJS team and we’re hoping to bring more in the future, so stay tuned!
What’s next for G.V()?
We’re working on a few big projects behind the scenes but it’s too early yet for us to share more details. In the meantime you can expect to continue seeing regular updates to our product with a focus on user experience and performance. If you have any thoughts of your own on what you’d like to see next in G.V(), make sure to let us know by emailing us at support@gdotv.com. Our goal is to provide the best graph database tooling possible and there’s no better way to achieve this than by listening to what our users want and need from our product – your feedback is what drives our roadmap.
Today I’m very proud to announce the release, at long last, of G.V() 2.1.2. This is our most important update yet, and is full of essential improvements and changes to take our software to the next level.
Major version change and major performance improvements
The first thing you’ll notice is that we’re going from 1.70.92 to 2.1.2, which looks like a big leap (and it is). However there are no breaking change as part of this release – our compatibility remains the same as ever!
The main reason behind the shift from version 1.x to version 2.x is a major upgrade of the technology stack that G.V() runs on. When we first started developing G.V(), it was running on a Vue 2 + Vuetify 2 + Webpack stack which was just about to give way to a newer, better Vue 3 + Vuetify 3 + Vite stack. For a number of technical reasons over the years we’ve been unable to perform that upgrade, up until recently, which leads us to today.
The upgrade work itself was quite significant both in scope and reward. One of the most immediately noticeable improvement in G.V() 2.x is performance: thanks to the benefits of the Vue 3/Vite ecosystem, G.V() now runs much faster overall.
The performance improvements we’re seeing today aren’t the result of a deep dive into our application’s optimisation either – and so we will continue delivering faster, more resource efficient versions of G.V() throughout the year.
Whilst the bulk of the work we’ve done on this release is behind the scenes, we also have a number of new features and user experience improvements to show for it.
User Experience Improvements
First and foremost, if you’ve been using G.V() on a macOS or Linux based device, you’ll have likely found the auto update experience clunky at best. We have finally resolved this issue and all users across all operating systems will now receive the same one-click auto update experience, which we’re hoping will help you adopt newer (and as always, better) versions of G.V() more easily.
We’ve also reworked the layout and resizing features of the application, and whilst this may not be immediately visible to the eye, resizing of the Gremlin Query Assistant or Query Output is now much faster and much better looking.
Finally, we’ve improved the handling of presenting Query results such that when running consecutive queries, the Query Output will now automatically update itself without closing then re-opening, as shown below:
Exposing G.V() Playgrounds over localhost
When we sunset our free G.V() Basic tier in favor of G.V() Lite, one valid concern that our user base expressed was losing the ability to use G.V() for local development against a Gremlin Server, for instance.
To respond to those concerns, we’ve now made our in-memory graph, G.V() Playground, optionally available to connect to a configured port on localhost. Currently this feature is limited to wrapping G.V() Playground with a Gremlin Server, though we will be investigating other embedded server technologies, such as JanusGraph.
This means that from this release, you can use G.V() to quickly stand up and manage Gremlin Servers as well as query them directly from your development environment, for instance.
What’s next for G.V()?
Parallel to this 2.0 rewrite, we’ve been busy planning for our upcoming work for the year. Last year, we’d commissioned a number of improvements to SigmaJS, the WebGL based graph visualization framework that you’ll recognize as the “Graph (Advanced)” view in the Query Output, as well as our Graph Data Explorer. SigmaJS is a high-performance, open source library developed by OuestWare, a fantastic data analysis solutions company responsible for plenty open source gems built around SigmaJS, and many more.
The 3.0 release of SigmaJS is coming soon and will be integrated in G.V() in the near future. This release focuses on performance improvements allowing rendering of more complex graphs, as well as a few cosmetic improvements such as the availability of curved edges, at long last!
Well hello there! It’s another month (October 31st so we technically made the cut on our monthly feature release) and with that we’ve got a bunch of new cool functionalities out in G.V().
Let’s go over them!
Working as a team: Remote Gremlin Queries and Folders
One big issue with the Apache TinkerPop framework and its implementations is the lack of a standard mechanism to store reporting queries directly within the graph – much like you would for instance in SQL using stored procedures. This was partially addressed by G.V() allowing you to save your queries locally on your device and organize into folders.
But what if you have 15 people in your team all connecting to the same graph database and wanting to run the same queries? What if you have hundreds of users looking to do this? You get the point – having each and everyone copy those queries over on their own G.V() client is not gonna cut it.
This is why we’ve introduced a new feature in this release allowing your G.V() Queries to be saved directly against your graph database so that they can be fetched automatically in G.V() whenever anyone connects to your graph using G.V().
The idea is simple: if you have reports that you want to centrally engineer and deploy to users that can connect to your database, design them in G.V() and save them remotely on your graph database in just a click and all your users will have access to them via G.V(). What’s more, you can also centrally update them and remove them, users will receive those updates automatically.
But here’s the best part: there’s no additional configuration required on your end! We’re keeping it simple by having all this information saved as vertices directly on your graph so that you don’t need any additional infrastructure to store and manage these remote queries (and folders).
We’ve put some documentation together on all of this that you can check out at https://gdotv.com/docs/query-editor/#save-a-query. This document goes through the details of how to use feature and how G.V() stores this metadata against your database.
In the future we plan to extend this further by allowing stylesheets to also be saved on your graph database so will soon be able to manage graph visualization configurations centrally too.
Gremlin Query Variables and Reporting
So you’ve got common Gremlin queries you’d like to deploy using Remote Gremlin queries and folders but you don’t want folks to have to write any Gremlin to run them? We got you covered!
In conjunction with the above feature, we’ve also added the ability to create variables in your saved Gremlin Queries along with a new “Run Query” option for saved queries that allows you to get your query’s results in full screen without having to go through the Gremlin Query Editor.
TL;DR: Think stored procedures for SQL but applied to Apache TinkerPop with a rich UI to prompt for the query’s parameters and display its results in a variety of ways!
There will be further customisation options introduced in future updates to allow creating even easier to run reports for your users, such as the ability to provide a dropdown of options for Query Variables or that ability to use boolean toggles.
Query Editor and Graph Size Settings Improvements
We’ve slightly improved the Query Editor’s suggestion engine to handle more complex scenarios (such as remembering property keys that have already been used in a step when generating suggestions).
Along that we’ve added a new Default Output Tab option allowing you to select which Result visualization G.V() should go to by default on the query.
The Graph Size Settings shown on the Large Graph View can now also be (partially) saved against your stylesheets so that you can easily apply defaults that meet your criteria on your visualization. Currently the sizing setting rules for Vertex and Edge labels cannot be saved against your stylesheet but this will be available in an upcoming release. The min/max vertex size, and apply custom vertex/edge sizes can all be saved on the stylesheet.
Goodbye G.V() Basic, hello G.V() Lite
We’ve covered this topic in a lot more detail in a separate blog post but G.V() Basic is going away and being renamed to G.V() Lite, along with a few changes to what the tier offers.
First of all (and most important), G.V() Basic is no longer going to be available to new users. Existing users will continue to have full access to it until February 5th, 2024, after which all G.V() Basic licenses will automatically expire.
The G.V() Lite tier now offers free access to our Gremlin Query Debugging feature as well as our OpenAI Text To Gremlin functionality. It will however now be restricted to only G.V() Playgrounds (our in-memory graph).
To find out all the details about this change, head over to this blog post.
Our October TinkerPop Wide presentation
We’ve held a presentation over at the Apache TinkerPop Discord Server on October 23rd covering upcoming features, roadmap and important G.V() related announcements.
You can check out the replay of the presentation on YouTube below:
In this article, we’ll cover how to visualize and query your Aerospike Graph database using G.V() – Gremlin IDE. To support this, we’ll use a sample movies dataset that we’ll load on our Aerospike Graph database and discover interactively on G.V(). We’ll also write and explain some Gremlin queries to extract valuable information for the dataset via Aerospike Graph.
Before we start, let’s quickly introduce Aerospike Graph and G.V().
Aerospike Graph is a new massively scalable, high-performance graph database launched on June 23 2023 as part of Aerospike’s multi-model NoSQL database. It uses Gremlin as its main querying language and reports < 5ms latency for multihop queries, even for graphs comprising of billions of elements. It was also recently made available on the Google Cloud Marketplace.
G.V() is a Gremlin IDE – its purpose is to complement the Apache TinkerPop database ecosystem with software that is easy to use and install, and provides essential facilities to query, visualize, and model the graph data. If you want to find out more about G.V(), check out From Gremlin Console to Gremlin IDE with G.V().
gdotv and Aerospike have partnered to offer a 60 days free trial of both Aerospike Graph and G.V() that you can take advantage of now if you haven’t already!
To get started, you’ll need the following:
Download Aerospike Graph: Have a running instance of Aerospike Graph as described in Aerospike’s Getting Started documentation with a folder of your choice mounted to the /etc/default-data folder of your container.
A dataset: This movies dataset can help you get you get started.
Once you’ve done all the above, you’ll be ready to connect G.V() to your database and visualize your data.
Connecting G.V() to your Aerospike Graph Database
Connecting G.V() to your Aerospike Graph database is quick and easy.
If you’re running your Aerospike Graph database from a networked device, ensure that the machine you’re running G.V() from can connect to the device. Refer to the demo below for connecting to an Aerospike Graph database run locally on the same device as G.V():
Follow these step-by-step instructions:
Click on New Database Connection.
Enter the hostname of your Aerospike Graph database; if running on your local machine, this will just be localhost.
Click on Test Connection. G.V() will make sure it can connect to your Aerospike Graph container. It will then present a final screen summarizing your connection details, which you can now save by clicking Submit.
Once you’ve created the connection on G.V(), you’ll first be prompted to sign up for your 60 days free, no obligation trial of G.V(). Pop your details in there, enter your validation code, and you’re all set.
This will transition to a new query window fetching the first 100 edges of your database, which should result in an empty array as we’ve not yet loaded data in our database.
Loading the Movies dataset in Aerospike Graph
Now that your Aerospike Graph database is up and running in G.V(), let’s load some data. Make sure you’ve mounted the volume to your Aerospike Graph Service Docker container, pointing either to a folder with the Movies dataset or to the dataset file itself.
For instance, in our setup, we’ve mounted our local default-data folder containing movies.xml to /etc/default-data. To load the movies.xml dataset in our database, let’s run the following query:
Give it a minute to run. Once complete, our dataset is loaded, and we’re ready to play with the data!
Styling the graph visualization
Let’s run a query to quickly visualize our data and get a good overview of the graph’s data model. In your G.V() query editor, run the following query:
g.E().limit(250)
Nothing fancy here – we’re just loading the first 250 edges in the database to generate a little display of your graph database. This is just to give you a taste of what G.V() can do!
Before we move on to our next steps, let’s quickly stylize the graph to make sure we’ve got the best display. To speed this along, we’ve created a stylesheet that you can import in G.V(). Download it here and follow the instructions below.
On the Graph view, click on Graph Styles as highlighted below:
Next, click on “Import Stylesheet”:
This will open a file explorer in which you need to select the “movies-aerospike.json” file you’ve just downloaded.
Once loaded, click on “Save New Stylesheet.” After the stylesheet is saved, toggle it to be the default stylesheet by clicking on “Set As Default Stylesheet” – Done!
You’ll see that the graph now displays the relevant information directly on screen, as shown below:
There are a lot of other things you can do in the graph view, so feel free to play around with the graph display. For reference, these are the graph controls and how to display them:
Exploring our graph’s data model
Once you’ve had a little interactive browse of your data, head over the Data Model Explorer view so you can examine the data structure:
As shown in the Data Model Explorer, our graph contains the following vertices:
Movie
Genre
Actor
Director
ActorDirector
User
Relationships in this graph are as follows:
Movies are in a genre (IN_GENRE)
Users have rated movies (RATED)
Directors have directed movies (DIRECTED)
Actors have acted in movies (ACTED_IN)
ActorDirectors have acted and directed in movies (ACTED_IN and DIRECTED)
It’s all pretty self-explanatory (and that’s the beauty of graphs!). We’ll not enumerate all the properties here, but let’s just go over the main ones of relevance:
All vertices have a name property
The RATED edge has a rating indicating the rating a user gave to a movie
All vertices but Genre and User have a poster property containing an image URL and a URL property pointing to their IMDB page
Querying, analyzing and visualizing the graph
There’s a lot of useful information that we can leverage to query our graph and get some insights. Let’s give it a go:
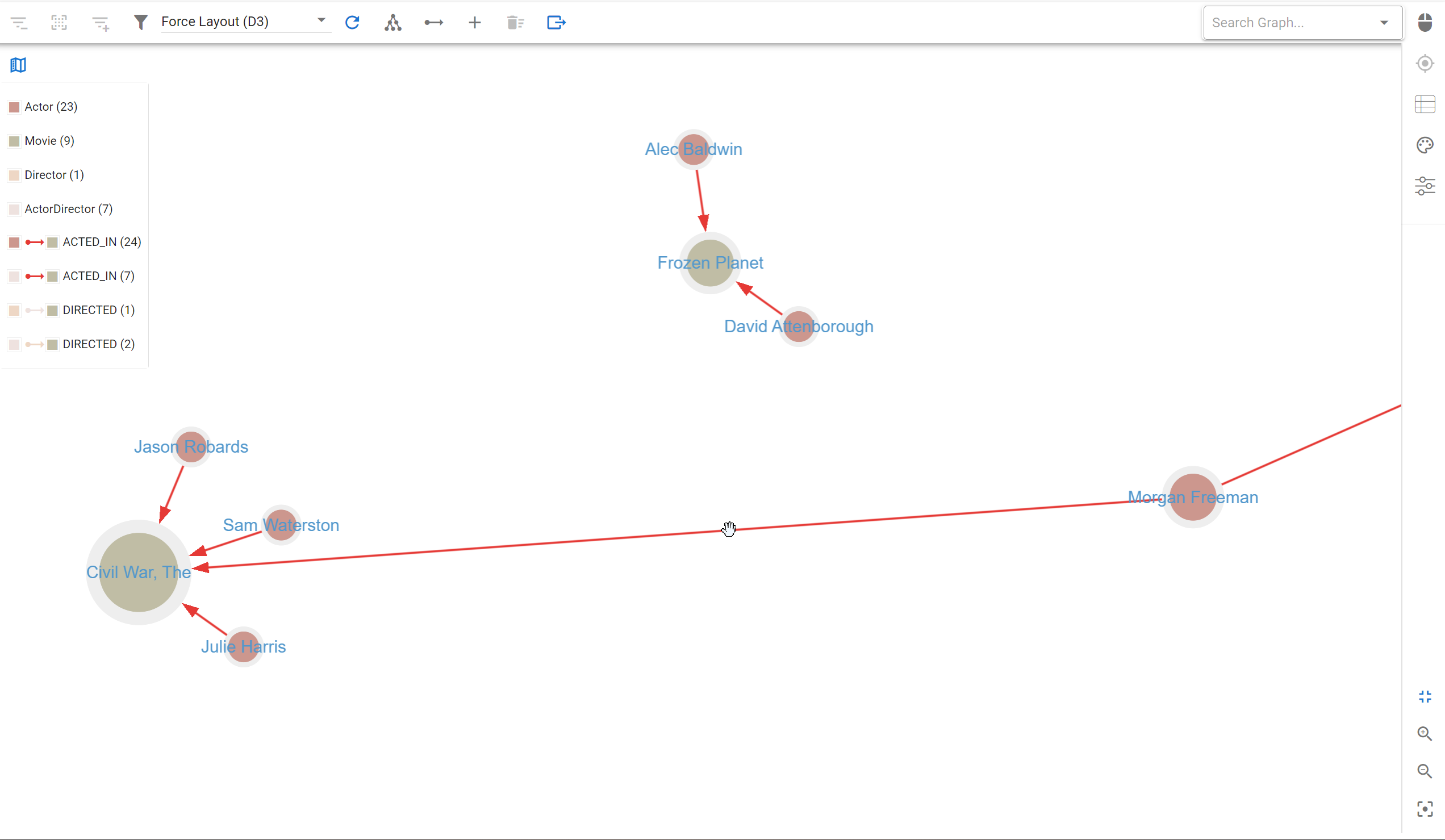
Our first query is going to be simple. I just want to see the graph surrounding the Titanic movie:
g.V().has("Movie", "title", "Titanic").bothE()
Quick breakdown:
g.V().has(“Movie”, “title”, “Titanic”) finds any vertices with a Movie label and a title property that equals “Titanic” – makes sense so far.
The .bothE() bit at the end there says, “fetch all incoming and outgoing edges to the vertices”, in other words, it will fetch all relationships to the Titanic movie.
To run the query, first, enter it in the query editor as shown below, then click on the green play button.
Quick note: If you click on the individual steps in the query, you’ll be able to see the official Gremlin documentation in the Gremlin Query Assistant on the right side of the editor. Great way to learn or remind yourself of the various steps and how they work:
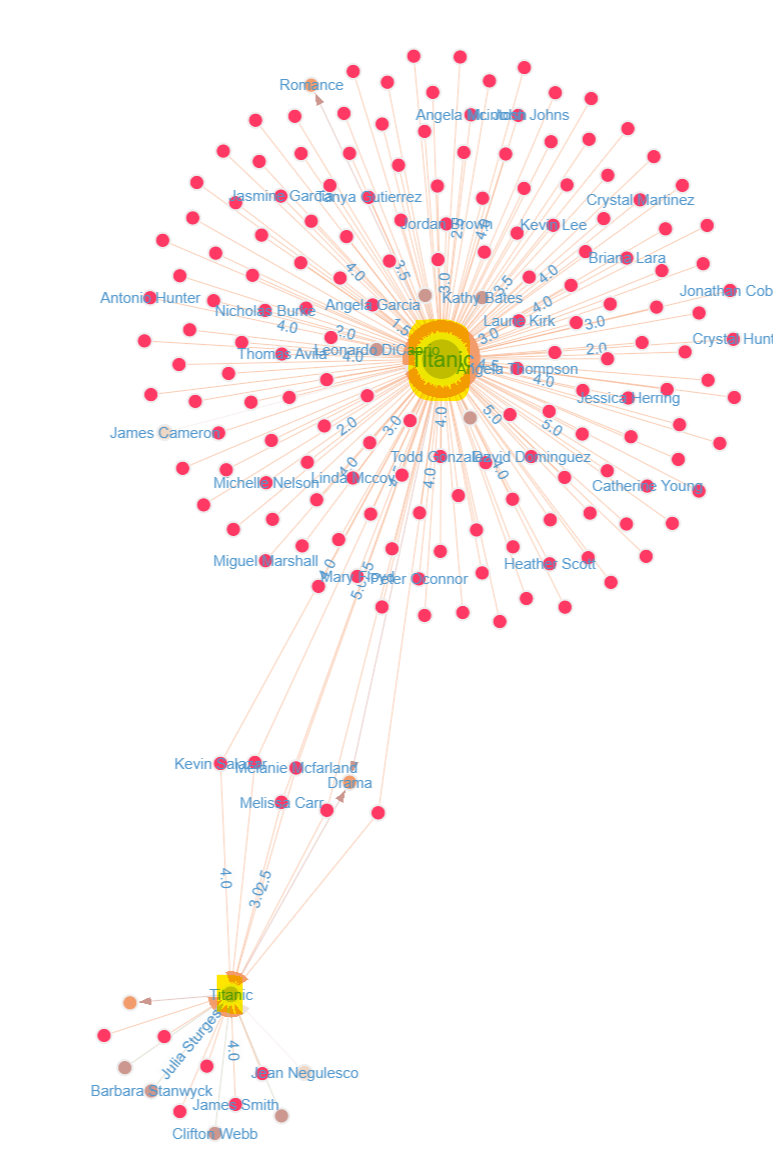
Anyway, once you’ve run the query, you’ll be presented with a graph display of the resulting data, and you should notice something odd: there are two Titanic movies!
(Now of course there’s nothing odd here – there are indeed two Titanic movies but I for one was born in the 90s and I have missed the release night for the first one by just about 40 years)
The graph display also visually indicates that one of these Titanic movies has many more reviews than the other. Unsurprisingly, it is James Cameron’s version, as highlighted by the DIRECTED_BY relationship between Titanic and James Cameron.
Well, it’s simple: it just turned out James Cameron’s Titanic wasn’t the only one or even the first to come out!
If you click on the Titanic nodes, you’ll also be able to check out their posters or open their IMDB movie page, as demonstrated below:
Let’s try a more complex query. What are the top 10 movies with the most user ratings?
First of all, we’re only interested in movies, so filter the vertices accordingly with g.V().hasLabel(“Movie”).
Next, order these movies by a metric, in descending order, and get the first 10 results, which happens at:
order().by(…, desc)
Now, for the order itself, use the count of incoming RATED edges as the main metric , which is done via inE(“RATED”).count().
Finally, to display the title of the matched movies and limit this to a top 10, add values(“title”).limit(10)
The final result is (drum roll please):
==>Forrest Gump ==>Pulp Fiction ==>Shawshank Redemption, The ==>Silence of the Lambs, The ==>Star Wars: Episode IV - A New Hope ==>Jurassic Park ==>Matrix, The ==>Toy Story ==>Schindler's List ==>Terminator 2: Judgement Day
Now, these are all pretty good movies, but they’re not the highest rated films .
In this database, there are two types of ratings available:
User ratings from 0 to 5 as shown in the RATED relationship from User to Movie
IMDB ratings based on votes which are aggregated into the rating property of movies
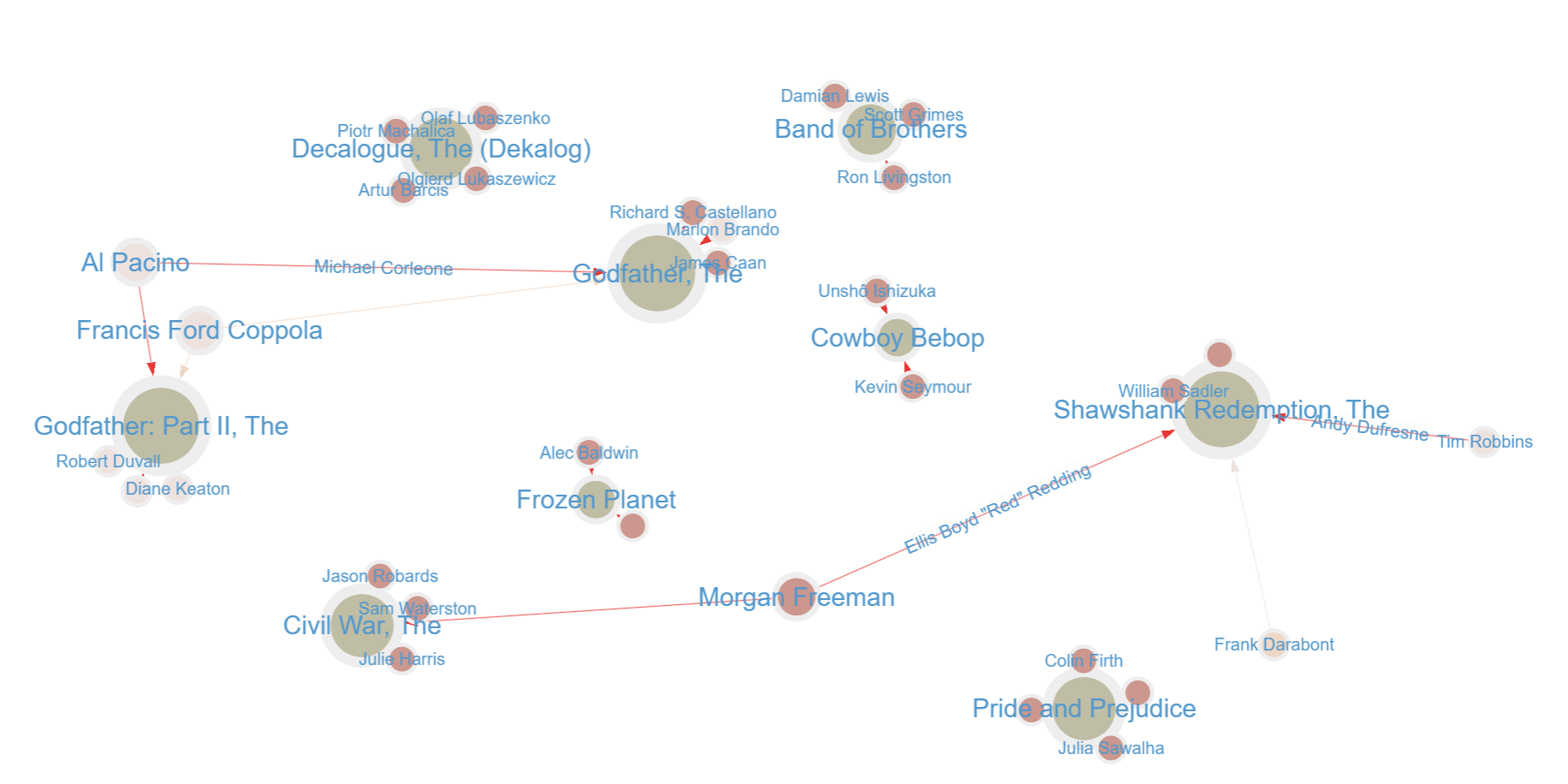
==>Band of Brothers ==>Civil War, The ==>Shawshank Redemption, The ==>Cosmos ==>Godfather, The ==>Decalogue, The (Dekalog) ==>Frozen Planet ==>Pride and Prejudice ==>Godfather: Part II, The ==>Power of Nightmares, The: The Rise of the Politics of Fear
Okay, I don’t know half of these, but then again I’m no movie critic. Let’s change the query slightly to also include the rating of these movies:
==>{title=Band of Brothers, imdbRating=9.6} ==>{title=Civil War, The, imdbRating=9.5} ==>{title=Shawshank Redemption, The, imdbRating=9.3} ==>{title=Cosmos, imdbRating=9.3} ==>{title=Godfather, The, imdbRating=9.2} ==>{title=Decalogue, The (Dekalog), imdbRating=9.2}
==>{title=Frozen Planet, imdbRating=9.1} ==>{title=Pride and Prejudice, imdbRating=9.1} ==>{title=Godfather: Part II, The, imdbRating=9.0} ==>{title=Power of Nightmares, The: The Rise of the Politics of Fear, imdbRating=9.0}
Let’s enhance the query a bit further by including the director and actors in these movies.
At a glance, we can see that Morgan Freeman and Al Pacino both acted in two top-rated IMDB movies and that Francis Ford Coppola directed two of them, as well. This kind of makes sense, given that for the latter, both movies are part of the same trilogy, The Godfather.
Just to wrap things up in this first introductory post, you’ll notice that some of the actor relationships are missing information; for instance, Morgan Freeman’s role in The Civil War is not stated. Using our graph visualization, we can easily update the graph interactively to fix any missing data. I will also add myself as an actor on Pride and Prejudice in this dataset, just because I can!
Try Aerospike Graph and G.V() free for 60 days
We’re just barely scratching the surface of what Aerospike Graph and G.V() can deliver together. This post simply demonstrates how you can quickly get up and running with a sample dataset on Aerospike Graph to explore graph data interactively or via Gremlin queries.
For instance, Aerospike Graph offers a Bulk Data Loader that can load your semi-structure CSV data into a graph database, enabling fast access to visual insights and interactive editing via G.V().
And as a reminder, here’s the best part: you can try this all out for 60 days for free! So what are you waiting for? Get your Aerospike Graph 60-day trial now and explore your shiny new graph database with G.V()!
G.V() Basic is our free tier. It allows you to use most of our software’s functionality without restrictions for the following Apache TinkerPop Graph Systems:
Gremlin Server
JanusGraph
ArcadeDB
Azure Cosmos DB Emulator
On February 5th 2024, this tier will be removed and all G.V() Basic Licenses that have been issued will expire. Continuing to use G.V() with the above Graph Systems will require a paid G.V() Pro license.
A new free tier, G.V() Lite, has already been introduced for new users and allows (mostly) unrestricted use of G.V() with our in-memory graph, G.V() Playground.
Continuing to support the developer experience with G.V() Lite
This free tier is designed to support users learning graph databases or Gremlin and will receive new specific functionality before G.V() Basic’s expiry allowing for in-memory graphs to be exposed over a network to connect your development environment (or any other application).
Initially G.V() Playground will be restricted to running TinkerGraph (Apache TinkerPop’s own in-memory graph) but we plant to extend this to support JanusGraph’s as well.
As part of this, we’re also opening up access to our Gremlin Query Debugging functionality and our OpenAI Text To Gremlin feature to all users of G.V() Basic and G.V() Lite.
Our goal is to give everyone a free to use software that allows them to stand up and manage Apache TinkerPop in-memory graphs effortlessly, and to expose them over a local network so that they can be accessed from their development environment.
This will allow developers and engineers to continue to develop their graph project locally using G.V() without the burden of having to stand up and manage Apache TinkerPop graph systems by themselves. When the time comes for these graphs to be deployed in production using one of the many Apache TinkerPop systems G.V() support, they can then choose to start using G.V() Pro to continue supporting their graph use cases.
Why is this happening?
G.V() is a passion project that I’ve now embarked on three years ago at time of writing. G.V() saw it’s first beta release after a year of work and remained 100% free to use until January 2023, when we’ve introduced G.V() Pro for Amazon Neptune and Azure Cosmos DB. We’ve received a lot of great feedback that helped us improve the software over the years.
To continue delivering quality updates at a monthly cadence we need financial support from our user base. With your support we can work on more ambitious features that keep pushing the boundaries of tooling in the Apache TinkerPop ecosystem.
We hope that you will understand and support this decision – it’s essential to sustaining the growth of our software.
Will there be exemptions/exceptions?
We offer a 30% discount on G.V() Pro for small companies like us that you can apply for here.
If you are a student or an academic looking to use G.V() for learning or educational purposes, contact us at support@gdotv.com via your academic email address and we’ll provide you with a G.V() Pro license free of charge.
If you’re a committer to one of the open source Apache TinkerPop systems listed above, we’ll also be happy to send you a free G.V() Pro license. Just contact us at support@gdotv.com from an email address that can be tied back to any of your contributions in the last 12 months.
So I’ll (likely) need a G.V() Pro license – where do I start?
To purchase a G.V() Pro license, head on over to our Pricing page. We’ve included a whole lot of FAQs to help you through the process. If you need to raise a Purchase order with us simply get in touch at support@gdotv.com and we’ll get this all over to you in no time – same goes if you have vendor onboarding questionnaires or any similar due diligence.
What’s next for G.V()?
G.V() is going to continue receiving monthly feature updates – and with all your support it will just keep getting better and better, so stay tuned!
Are you new to Apache TinkerPop or Graph Databases in general? Are you looking for directions on how to get started with graph data and the Gremlin query language?
Then look no further than Kelvin Lawrence’s Practical Gremlin: An Apache TinkerPop Tutorial. It’s a free ebook that you can read right here from your browser. It covers the Apache TinkerPop framework and its querying language, Gremlin in great depth. Or as Kelvin describes it:
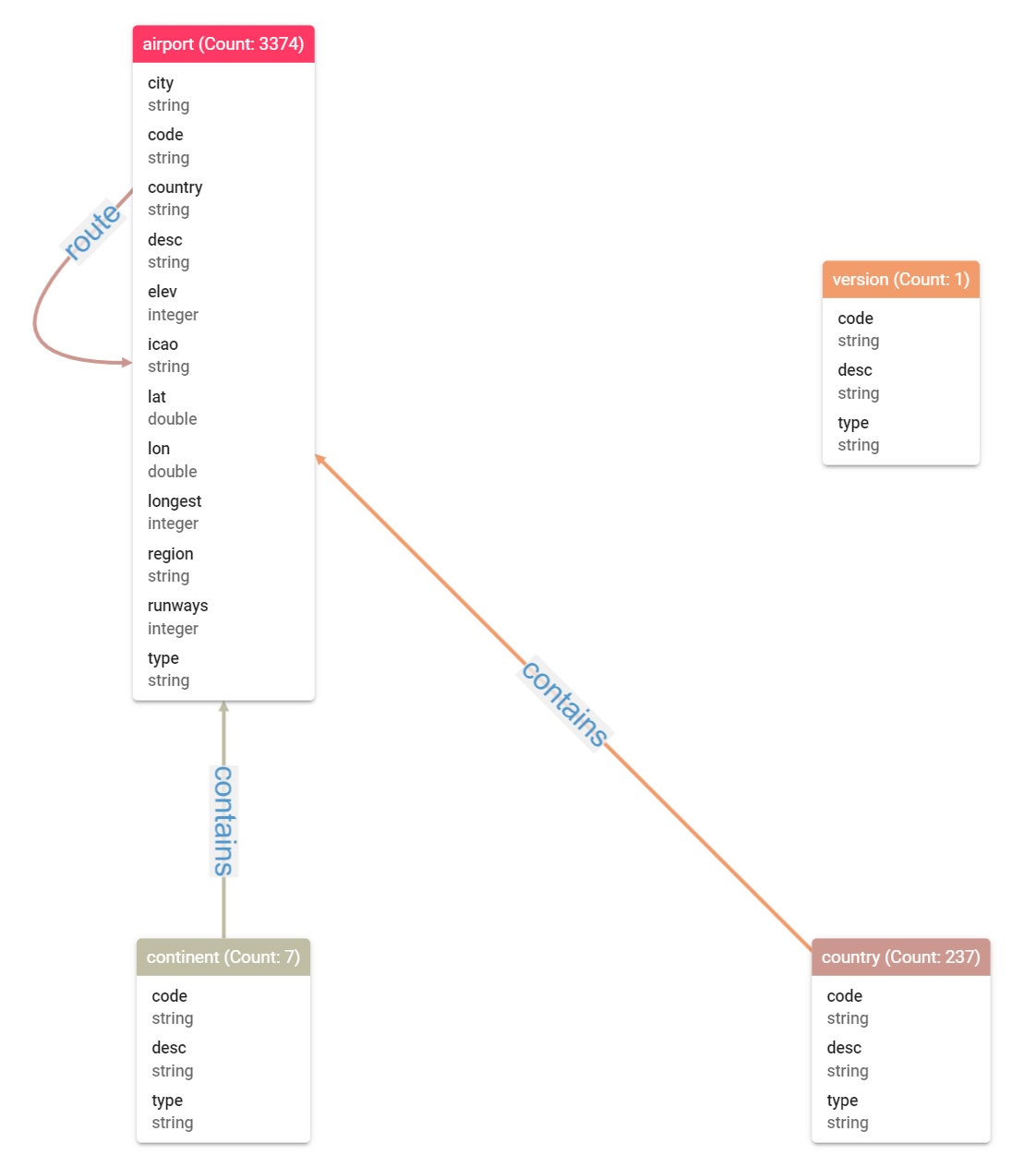
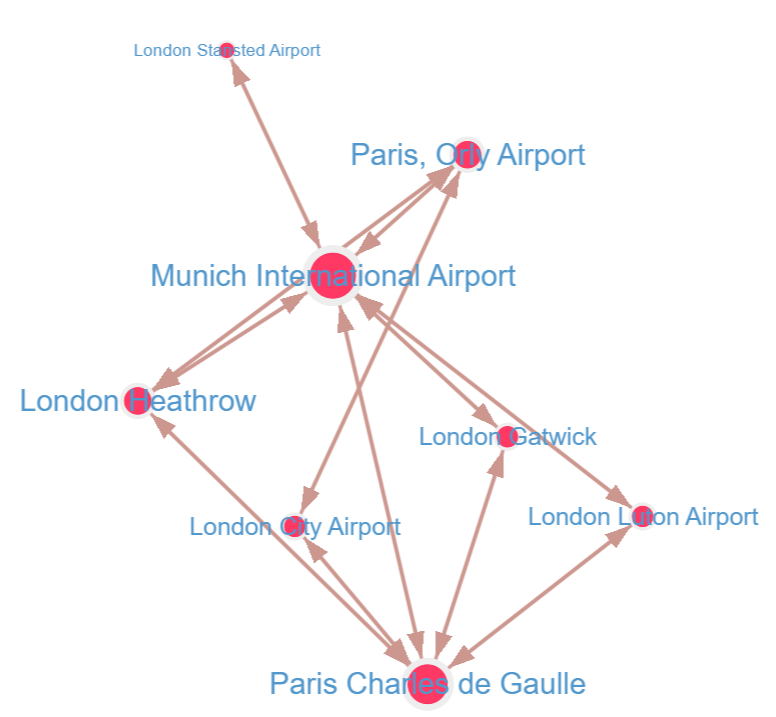
This book introduces the Apache TinkerPop 3 Gremlin graph query and traversal language via real examples featuring real-world graph data. That data along with sample code and example applications is available for download from the GitHub project as well as many other items. The graph, air-routes, is a model of the world airline route network between 3,373 airports including 43,400 routes
Practical Gremlin is packed full of example queries that will give you a comprehensive overview of the capabilities of the framework. It also discusses very concept behind graph databases and their advantages over traditional relational databases such as SQL. Each query presented in the book corresponds to a genuine use case The query description shows what the data is needed for, its format, and how it is written using Gremlin.
The Air Routes dataset is simple to understand and intuitive. It contains the relationship between Airports, Countries and Continents. A continent contains countries which contain airports which have air routes allowing travel between cities and countries across the world.
For reference, this is the structure of the Air Routes dataset represented as an Entity Relationship diagram using G.V()’s Data Model Explorer tool:
The graph use case is clear too, especially over the use of relational data. In order to calculate possible itineraries based on existing routes between Airports in different countries, a lot of joining operations are required. For instance when calculating all routes from Austin, Texas, USA to Paris, France, all relationships going out of Austin, into Paris, and potentially in between have to be evaluated as well. This approach would scale very poorly in SQL due to the immense amount of joining operations required. Additionally, the more hops are required in the data, the worse performance (and query structure) would get!
This works in graph because the relationships between entities are first-class entities too, the same way vertices are – you can query entities in a relational database, but you can’t directly query relationships without having to go through its entities (tables in this case, where relationships are the foreign keys).
We’ve covered the basics of our favorite Gremlin learning resource – now let’s use the best available tool (G.V() of course :D) to practice the contents of the book!
Getting started with G.V()
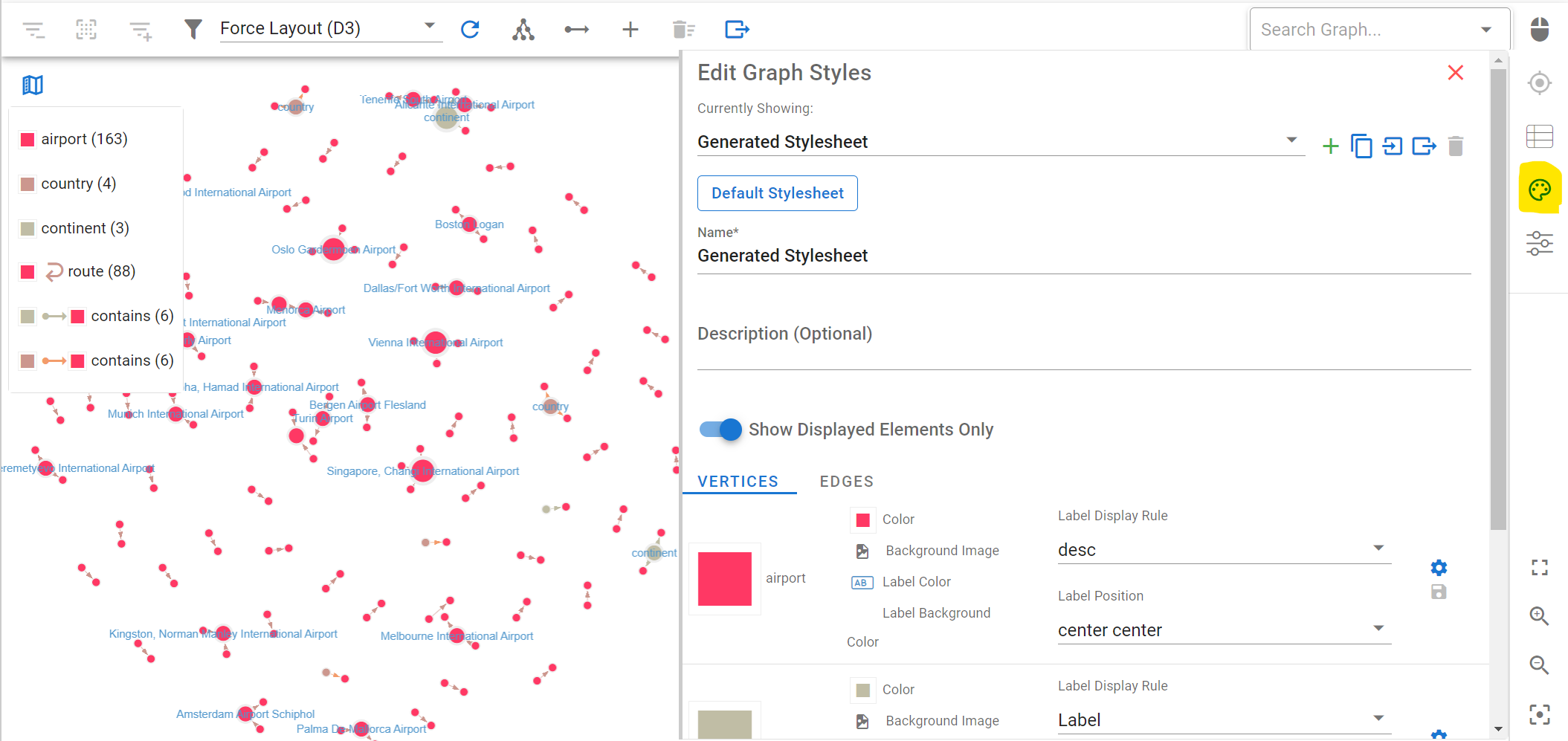
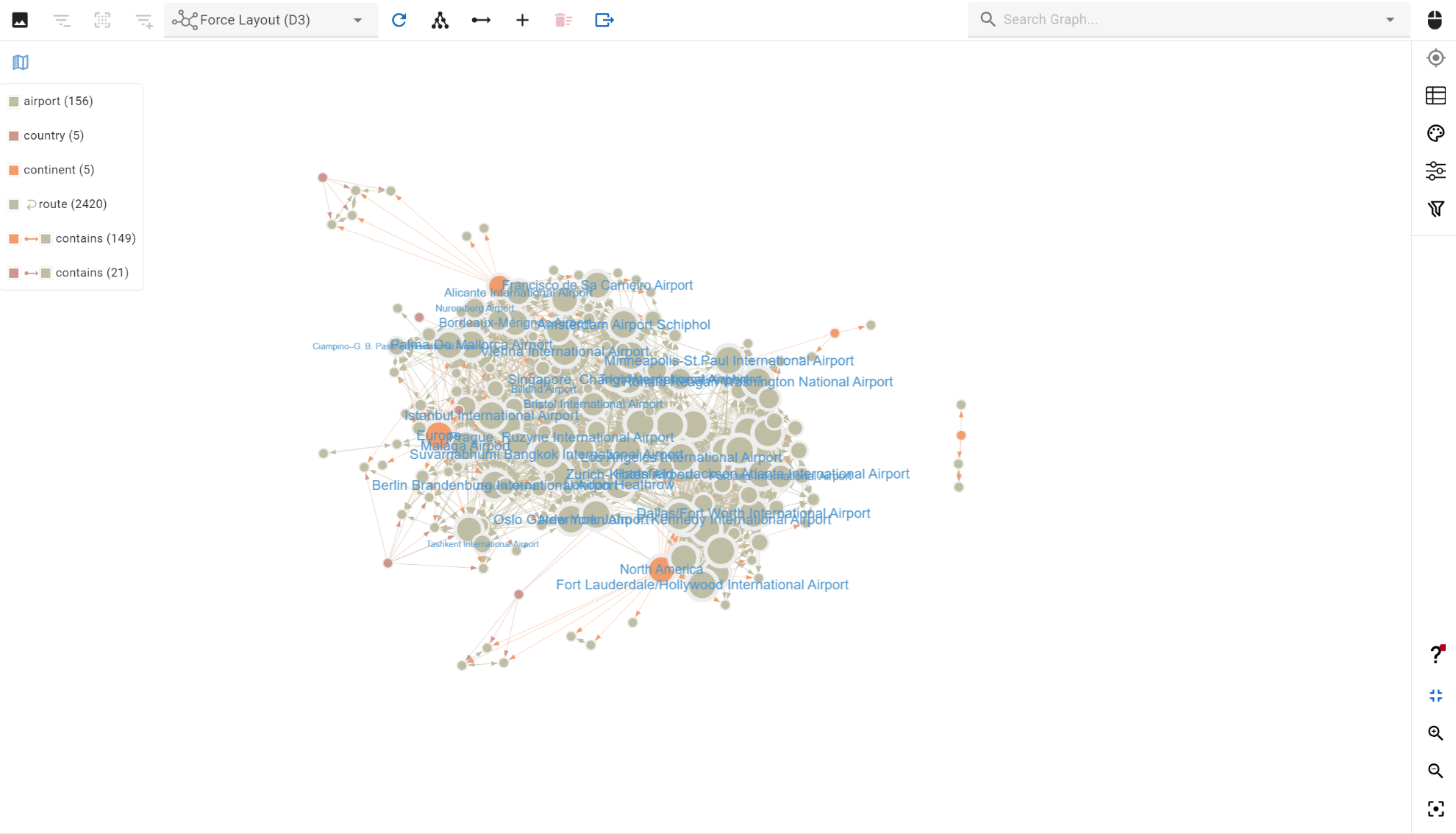
The entire Air Routes Dataset display in G.V()’s Graph View – Now is it just me or does this look a bit like our world map?
Let’s get to work! First things first, you need to download and install G.V() – and don’t worry, this is all 100% free.
Once you’ve got G.V() installed, you’ll be presented with a Welcome Screen. We love Kelvin’s work so much that we’ve put it front and center on our application. Scroll down (if you’re on a small screen) and you’ll notice a Learn Gremlin With Kelvin Lawrence’s PRACTICAL GREMLIN section. Click on Open Practical Gremlin to open the book, if you haven’t already, and click on Create Air Routes Graph to create an in-memory TinkerGraph instance on G.V() with the air routes data set pre-loaded.
Quick editor’s note: you’ll be prompted to sign up for a G.V() Basic License – it’s free and permanent. We’re just asking for some basic details and we’ll not bother you unless you agree to be contacted by us!
Once you’ve created your air routes graph and signed up for a free G.V() Basic License, you’ll be presented with a query screen with the following query run for you:
g.E().limit(100)
This is a simple query that simply says “fetch me the first 100 edges in the database” – this allows G.V() to produce a nice little initial graph visualisation for you.
G.V() is a Gremlin IDE – long story short, it can do a lot. For the purposes of this blog post you can mostly just stick to this newly opened query tab to run queries from the book. Have a little click around the various result tabs showing (Query Output, Vertices, Edges) to get a better idea of what’s being displayed. You can also click on elements in the graph to view their details, modify their properties, etc.
Additionally, you can view your database’s graph schema by clicking “Open Data Model Explorer” on the left navigation pane. If you just want to explore the data in free form or query it without writing any actual query, you can also open a Graph Data Explorer, also in the left pane. Finally, you can open as many queries as you like, so you can easily compare them. Go ahead and click “New Query” on the left navigation pane under your Air Routes connection to create another query tab.
There’s a lot more functionality available but as far as this follow along with the book exercise is concerned, this should about do you! Feel free to have a play around though.
We’re all setup to follow along with the book now. Note that since we’ve already loaded Air Routes in a G.V() in-memory graph, you can just go ahead and skip section 2.6 and 2.7, but we recommend you have a read and give them a try at some point anyway! There’ll be plenty queries for you try from section 3 through to 5. Further sections of the book will give you a great start on developing a graph application, deploying a graph database, and what your options are!
Get reading, pop those queries in G.V() and give them a whirl! Try and type them manually in G.V() too so you can see our smart autocomplete feature in action!
Graph Visualization Options
Here’s a few advanced configurations you can do in G.V() to improve your graph visualization. Open a graph data explorer for your Air Routes connection, as explained before, and click on Graph Styles as shown below:
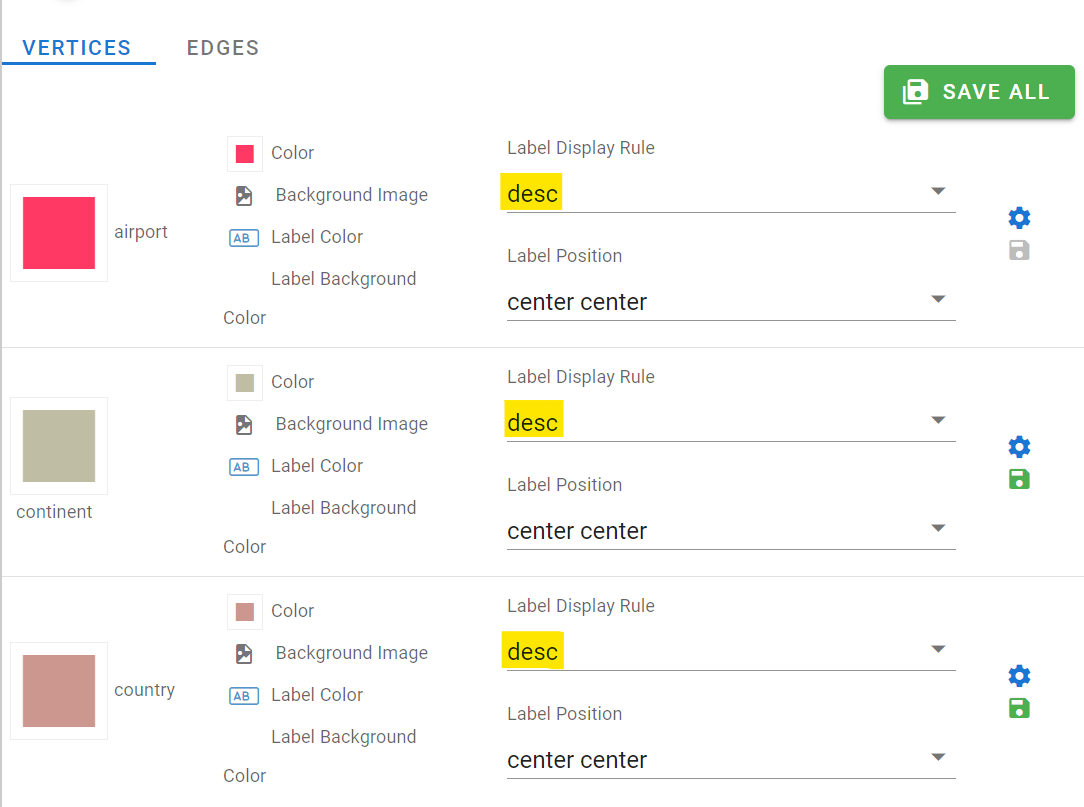
You can change the styles of your graph visualization. For instance, you can select what text to display on the vertex and edge labels. This is really useful to get quick and effective visual of your graph data. For your vertices, set the Label Display Rule value to “desc” (the name of the property in the graph containing the object’s name, e.g. country name or airport name) and click on “Save All”:
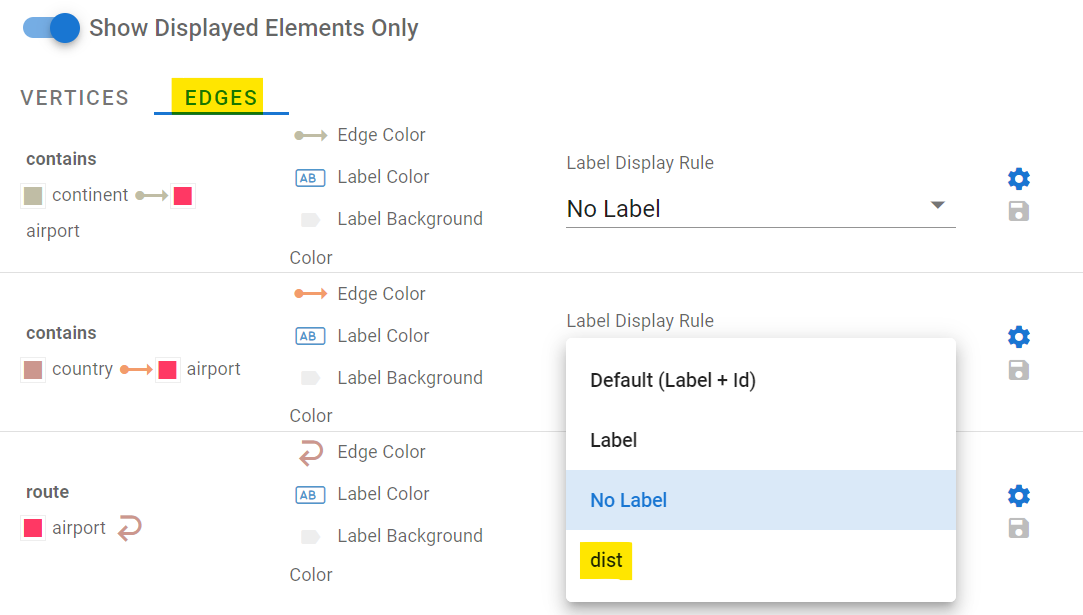
You can also set styles for your edges. Click on Edges, and for the “route” edge, select “dist” as the label display rule to display the route’s length (in miles) on the graph visualization.
Change the label display rule and hit Save Changes again. The graph visualization will update in real time as you change these configurations. You can also create multiple stylesheets and swap between them. There’s a lot of options available which we’ll not list here, but have a play. You can even set images for your vertex backgrounds!
You can also change the graph layout algorithm displaying your data. This can be useful to de-clutter the visual and is typically highly dependent on the volume of the data on your graph as well as how interconnected it is, check it out:
Generating Gremlin queries on your dataset with OpenAI
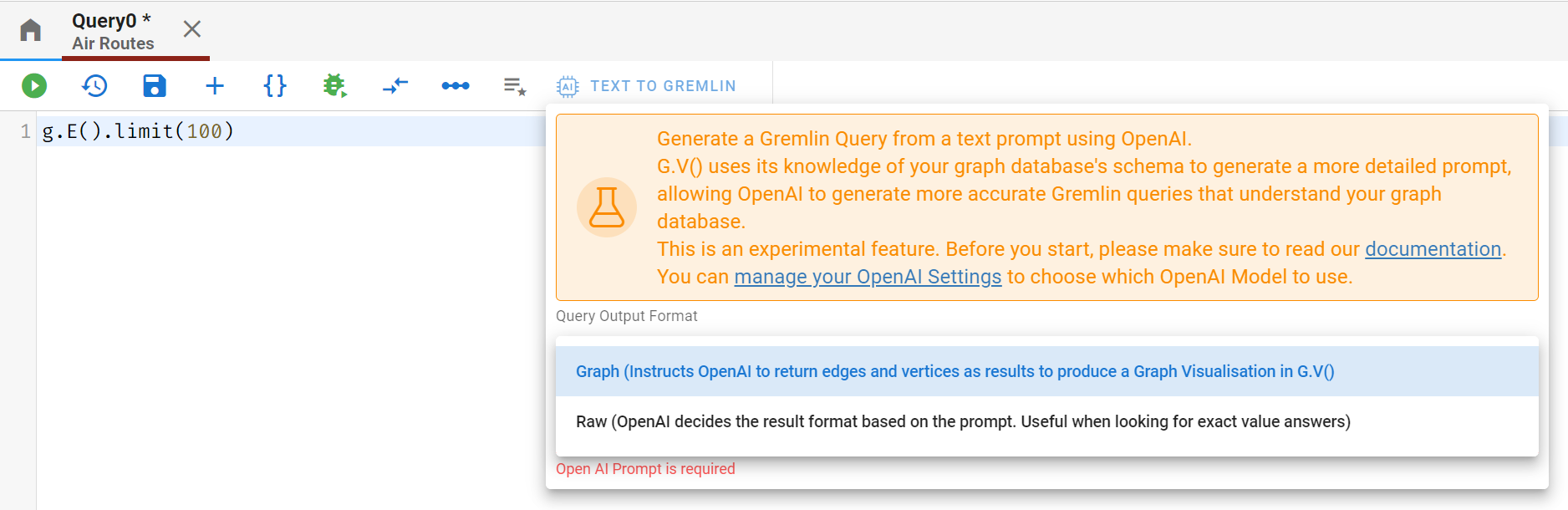
If you’re not much in the mood for writing queries today, guess what? You can just ask an OpenAI Model to do it for you. Open a new query editor and click on “Text To Gremlin” in the toolbar. First off, you’ll need to configure your OpenAI key – check out the documentation linked in the popup on your screen for more information.
Once you’ve got your OpenAI API Key configured within G.V(), you’re ready to go. Note that you can also choose with GPT model to use – GPT3.5 Turbo , GPT3.5 Turbo 16k (useful for more complex data schemas) or GPT4.
Let’s pop some prompts in and let OpenAI work its magic:
We’ll start with the following prompt, using GPT4:
find all the routes between airports in London, Munich and Paris
Editor's note: taking out the by('code') from the query to allow it to output a graph visualization rather than
plaintext Airport codes
And we get the following visual:
It’s the same result! Uncanny….G.V() does a little bit of magic behind the scenes to ensure that the GPT prompt submitted to OpenAI contains the essential information it needs to generate a Gremlin query that is aligned to your graph data schema. Give it a try! It’s a great way to query your data without ever having to write a Gremlin query.
Everything else
G.V() is the most feature rich Gremlin IDE available – so we’re not covering everything it can do here. But have a look at our documentation to find out more and make sure to check our Blog regularly too for new content demonstrating the capabilities we have in store. We have monthly new feature releases so you can be sure there’ll always be more for you to do on G.V()!
Conclusion time
Graph databases are great – they’re still relatively new compared to titans such as SQL and that means it can be hard to unlearn years or relational data reflexes. Kelvin Lawrence’s Practical Gremlin: An Apache TinkerPop Tutorial is a great way to learn more about Graph Databases, Apache TinkerPop and the Gremlin query language. With G.V(), you can enhance your learning experience and start seeing the concrete benefits of using a graph database with cool visuals and features to match with your data, at no cost.
There are other learning resources available too of course – many of them just as great, for instance, Apache TinkerPop’s own Getting Started guide!
Who knows, with a bit of practice and learning you might find yourself developing and deploying your graph database to one of our many supported graph systems (Aerospike Graph, Amazon Neptune, Azure Cosmos DB, JanusGraph, and more)!
Did you like this post? Share it around and tell us your thoughts below!
 3.6.26: Cypher Support for Amazon Neptune & PuppyGraph, and more!")

")



 2.16.27 Release Notes")


 and LocalStack, the AWS Cloud Emulator")
 2.10.17 Release Notes")

 – Gremlin IDE")




 and Practical Gremlin by Kelvin Lawrence")