
Evaluating Codebase-Oriented RAG through Knowledge Graph Analysis [Part 1]
![Evaluating Codebase-Oriented RAG through Knowledge Graph Analysis [Part 1]](https://gdotv.com/wp-content/uploads/2026/03/knowledge-graph-analysis-codebase-oriented-rag-part-1.png "Evaluating Codebase-Oriented RAG through Knowledge Graph Analysis [Part 1]")
One of the emerging applications of retrieval-augmented generation (RAG) systems is RAG for codebase analysis.
In this setting, static analysis pipelines – combining parsing, AST construction, symbol resolution, and dependency extraction – are used to construct a knowledge graph from the structure of a source code repository, including files, packages, classes, functions, and other structural elements.
This knowledge graph enriches the context provided to connected large language models, enabling them to answer questions about the code with improved grounding and significantly reduced structural hallucination. In more advanced workflows, such systems can also assist in proposing concrete modifications to the code.
In this two-part blog series, our goal will be to analyze the knowledge graph produced by such systems. We’ll approach this through a series of queries that pursue two main objectives:
- In Part 1 (today), we perform a codebase architectural analysis, assuming the generated knowledge graph is correct, to understand what structural insights can be derived from it.
- In Part 2 (next week), we critically evaluate the structural integrity of the knowledge graph itself (constructor validation) to assess how faithfully the graph represents the original codebase and explain some notes on expressiveness and semantic completeness, investigating whether the graph captures sufficient semantic richness to support deeper reasoning tasks.
Throughout this post, we’ll use Code-Graph-RAG as a case study, as it represents a recent and notable tool in this space. As the subject codebase, we’ll use Soufflé, a well-known Datalog language and engine. This choice is intentional: it provides a relatively complex C++ codebase with diverse input/output workflows, parallel execution mechanisms, and computationally intensive logical algorithms, making it a suitable benchmark for evaluating the strengths and limitations of codebase-oriented RAG systems.
All right, let’s begin.
Using gdotv for Knowledge Graph Analysis & Evaluation
Knowledge graphs generated by RAG-based code analysis tools are typically used behind the scenes.
Although these systems usually allow exporting or inspecting the graph (often through command-line interfaces) the graph itself is rarely treated as a first-class, explorable artifact. With a general-purpose graph exploration tool such as gdotv, however, these knowledge graphs can be analyzed visually and interactively, enabling deeper structural inspection and exploratory validation. In this experiment, we use the latest version of gdotv to systematically analyze and evaluate the generated knowledge graph.
Setup
In this analysis, we first need to set up Code-Graph-RAG, which in turn requires configuring the connected language model, preparing the target codebase, and generating the corresponding knowledge graph. To explore and analyze the resulting graph interactively, we also require gdotv.
Setup Code-Graph-RAG
![]()
First, clone the repository and install the required system dependencies:
clone the repo `git clone https://github.com/vitali87/code-graph-rag.git`
Then install required native tools:
install prerequisites: `brew install cmake ripgrep`
And now make the project:
cd code-graph-rag uv sync make dev
You may need to install uv in your system via brew or your package manager.
Configure Code-Graph-RAG
Create and configure your environment file:
cp .env.example .env vi .env
The.env file contains pre-written and commented configuration templates. Depending on whether you use a local small language model (SLM) via Ollama, or a hosted LLM API such as OpenAI, you can uncomment and adjust the appropriate section. For this example, we’ll use local models through Ollama:
# Model Provider Configuration # Example 1: All Ollama (local) ORCHESTRATOR_PROVIDER=ollama ORCHESTRATOR_MODEL=llama3.2 ORCHESTRATOR_ENDPOINT=http://localhost:11434/v1 CYPHER_PROVIDER=ollama CYPHER_MODEL=codellama CYPHER_ENDPOINT=http://localhost:11434/v1
Here the orchestrator model handles reasoning and high-level task planning and the Cypher model generates graph queries for Memgraph. Please note that using a high-capacity hosted LLM (e.g., GPT-class models) generally improves reasoning quality and query accuracy compared to small local models.
Initialize Your Language Models with Ollama
Since the configuration specifies Ollama, we must install and prepare the models locally.
curl -fsSL https://ollama.com/install.sh | sh ollama pull llama3.2 ollama pull codellama
Ensure Ollama is running:
ollama serve
Ollama serves models at http://localhost:11434, which matches the .env configuration.
Parsing a Codebase: Soufflé (C++)

Now we prepare the target codebase. As I said before, we’ll use Soufflé as our case study.
First, clone the repository:
git clone https://github.com/souffle-lang/souffle.git
Then, make sure Memgraph is running (from inside the code-graph-rag directory):
docker-compose up -d
Memgraph is a lightweight and high-performance property graph database used here as the graph engine that stores the extracted knowledge graph.
Generate the Knowledge Graph
Now we parse the Soufflé repository and build the knowledge graph:
./.venv/bin/cgr -q start --repo-path ~/GitHub/souffle/ --update-graph --clean
When the process finishes the knowledge graph is fully stored inside Memgraph and you can query it via the cgr CLI or much better, you can connect to Memgraph using gdotv for interactive data exploration and validation.
In the following video, you can see how to connect gdotv to the running Memgraph instance and explore the basics:
A Quick Look at the Code-Graph-RAG CLI
When using a small local language model (SLM), the quality of responses can be noticeably limited even for the example questions provided in the cgr README. In practice, smaller models often struggle with multi-step reasoning, accurate Cypher generation, and deeper structural interpretation of the graph.
The following screenshot shows sample prompts and the corresponding outputs produced by the CLI.
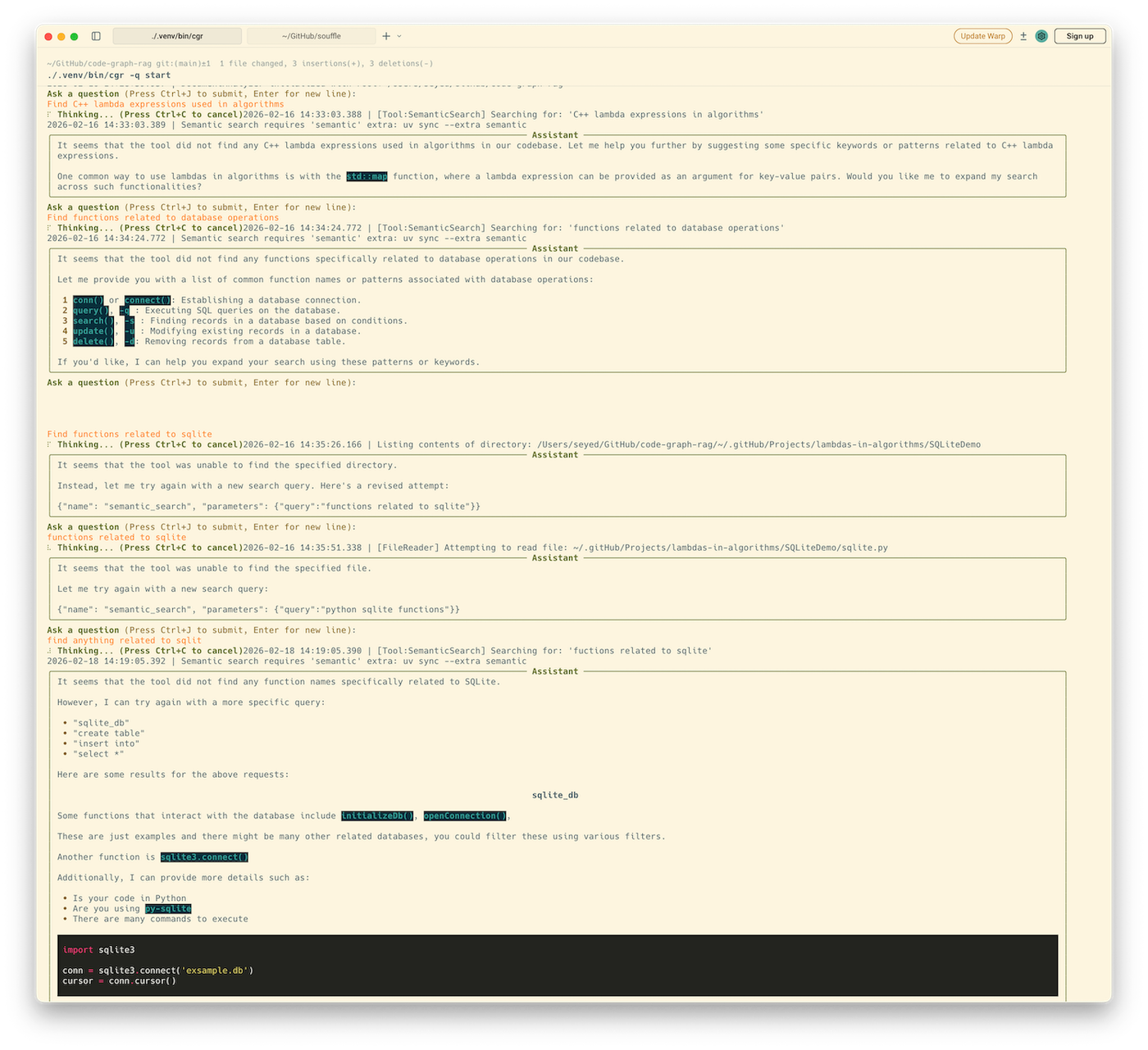
It is worth noting that Soufflé makes extensive use of lambda expressions and includes integration with SQLite.
Codebase Architectural Analysis
We now use gdotv to analyze the knowledge graph generated from the Soufflé codebase, enabling us to uncover structural indicators of architectural complexity and engineering design characteristics.
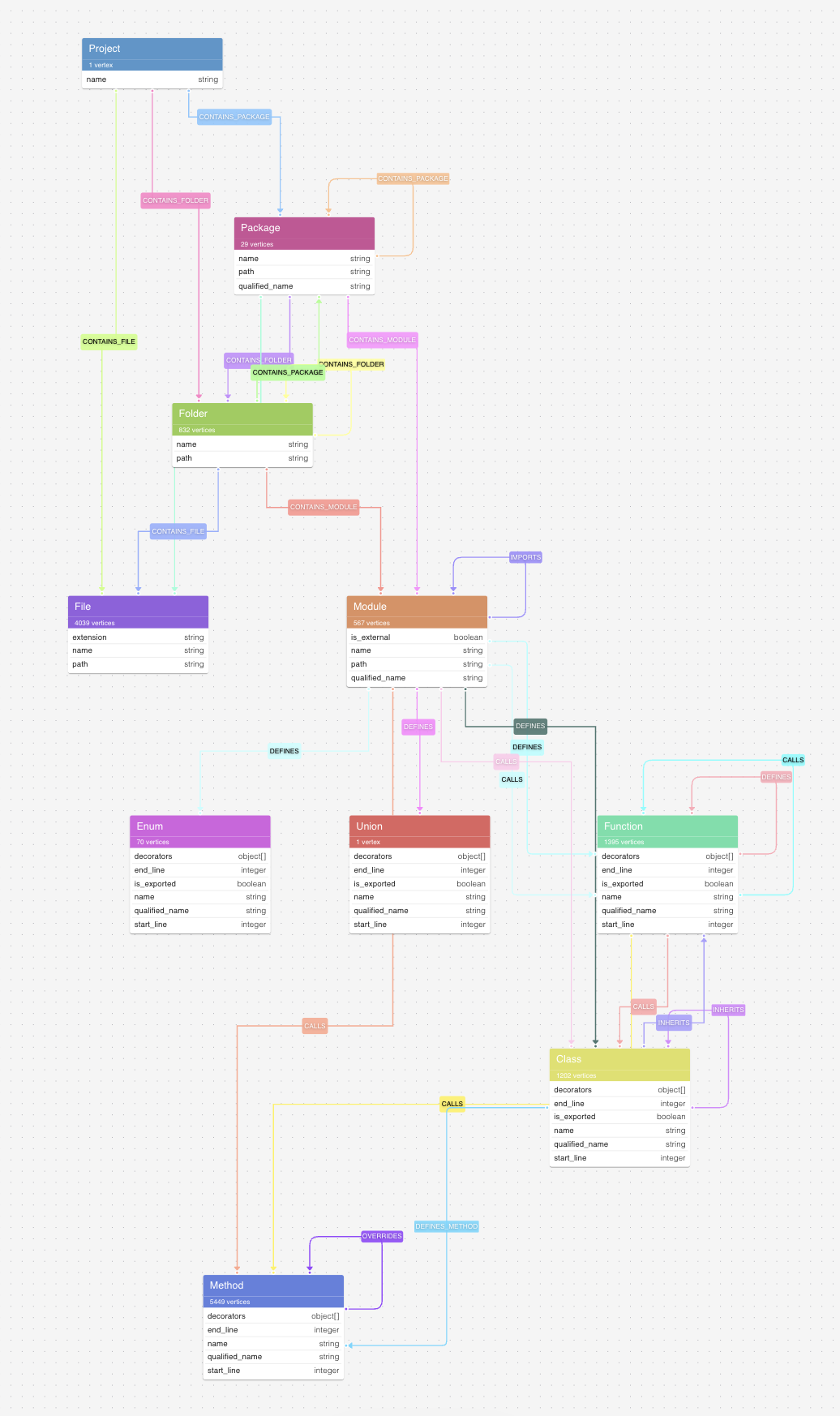
Below, you can see the data model of the knowledge graph. It mostly matches the schema described in the Code-Graph-RAG documentation, but there are some strange paths that we discuss in the next sections.
Full Structural Drill-Down
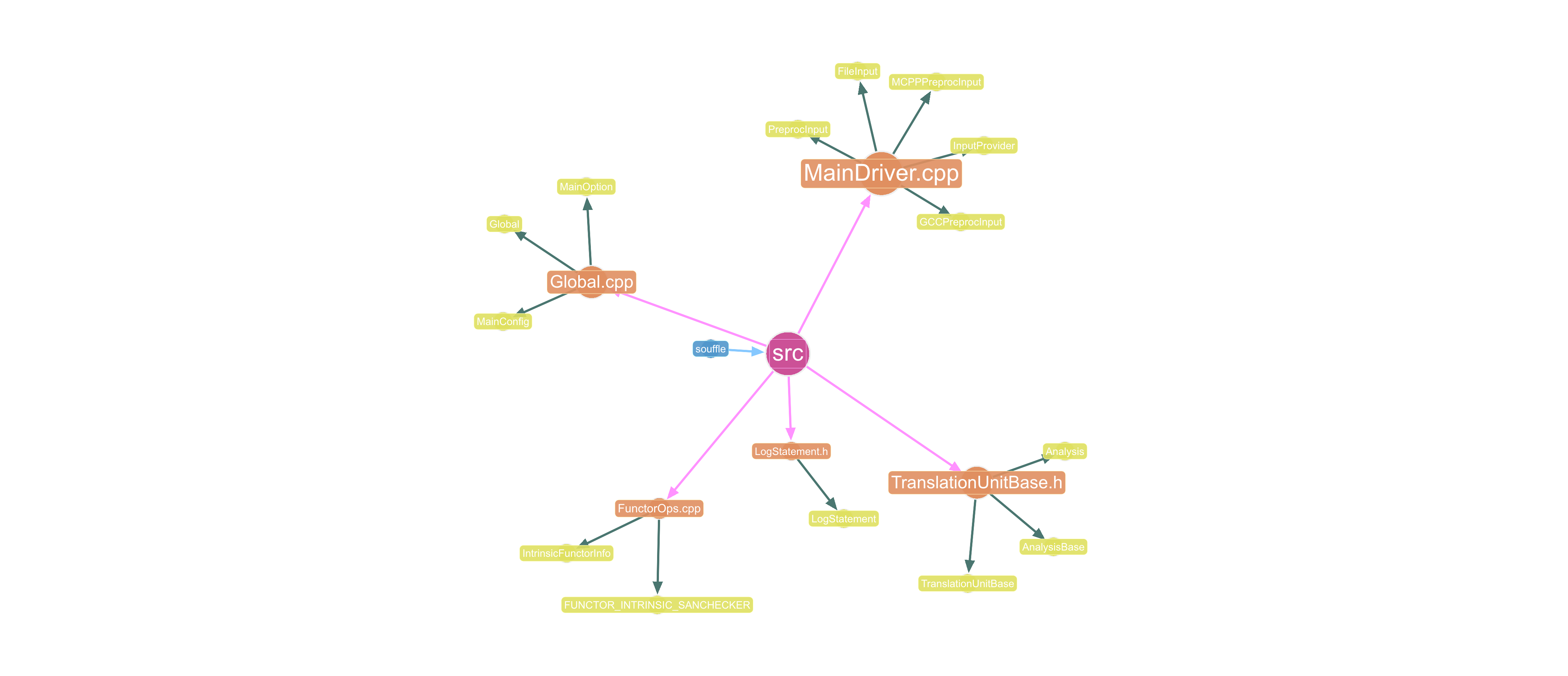
The following Cypher query traces the full containment spine of the codebase from the top-level project down through its packages and modules, all the way to the classes they define. This makes it immediately clear how code is physically organized and where responsibility is concentrated.
MATCH path = (proj:Project)-[:CONTAINS_PACKAGE]->(pkg:Package)
-[:CONTAINS_MODULE]->(mod:Module)
-[:DEFINES]->(cls:Class)
RETURN path
LIMIT 30
In gdotv, the graph visualization is rendered as a clean tree from the project root, exposing the depth and breadth of the codebase at a glance.
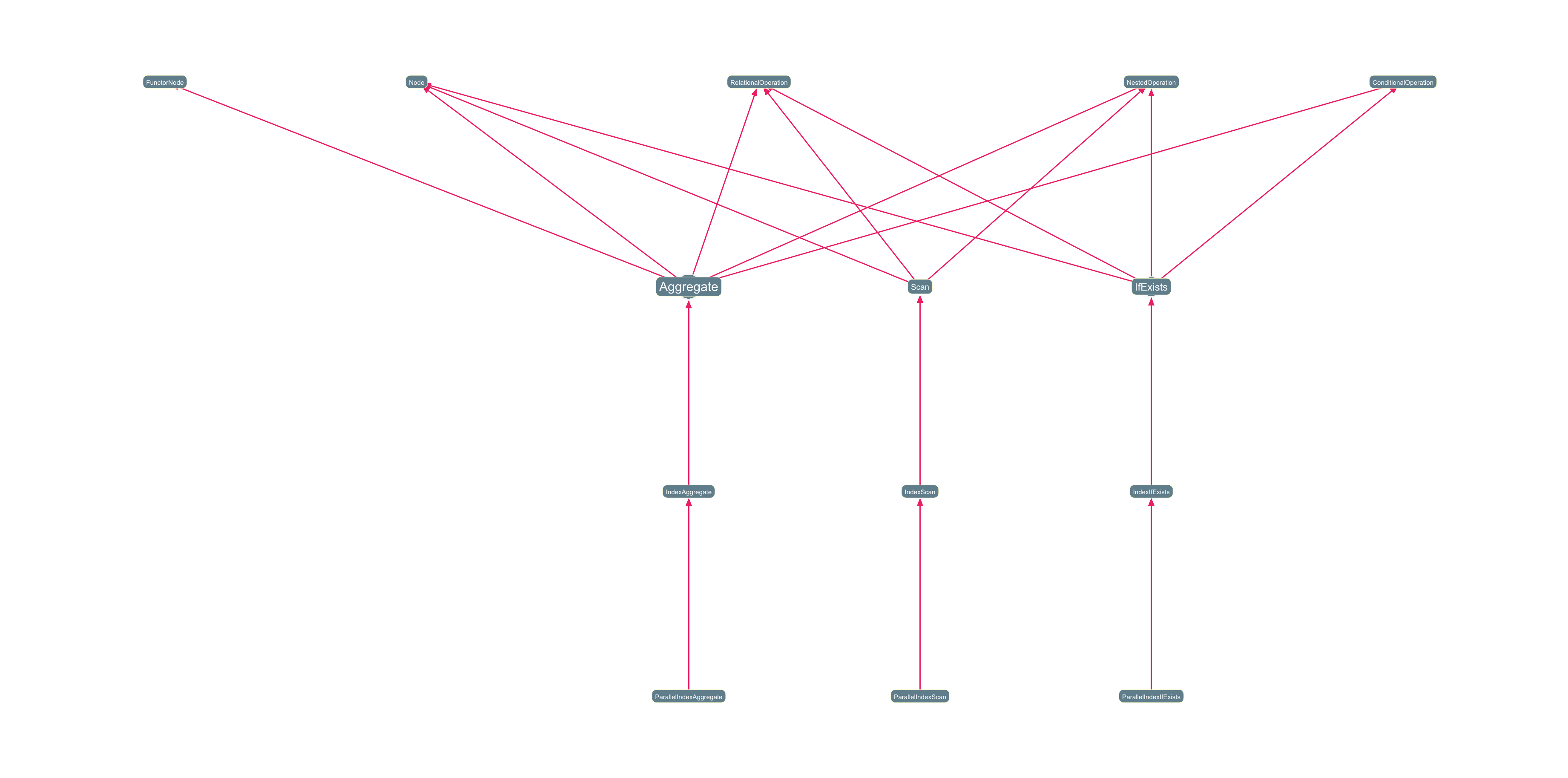
Inheritance Chains (Class Hierarchy Paths)
This next Cypher query surfaces how classes extend one another, following inheritance between at least three and at most five levels deep. It is one of the most revealing queries for understanding design philosophy.
MATCH path = (child:Class)-[:INHERITS*3..5]->(ancestor:Class)
WHERE length(path) > 2
RETURN path
Deep chains (more than five) often signal heavy OOP reliance or framework-driven patterns, while flat hierarchies suggest a more composition-oriented codebase. In the graph visualization below, these render as elegant directed chains that make hierarchy depth immediately legible.
Most Connected Modules (Hub Detection via Paths)
This Cypher query below finds modules that are imported by at least two other modules, exposing the architectural hubs of the system, including the shared utilities, core abstractions, and foundational layers that everything else depends on.
MATCH path = (importer:Module)-[:IMPORTS]->(hub:Module)<-[:IMPORTS]-(importer2:Module)
WHERE importer <> importer2
RETURN path
LIMIT 100
These nodes are the highest-leverage points in the codebase: changes to them ripple everywhere, and they’re the first place to look for tight coupling or hidden god-objects.
While exploring these structures in gdotv for the Soufflé codebase, we observed that the knowledge graph contains two major connected components: one corresponding to the Python-based compile/test/install tooling, and another representing the core C++ implementation of the system. Increasing the query limit primarily expands the C++ component, adding further structural detail rather than revealing new high-level subsystems.
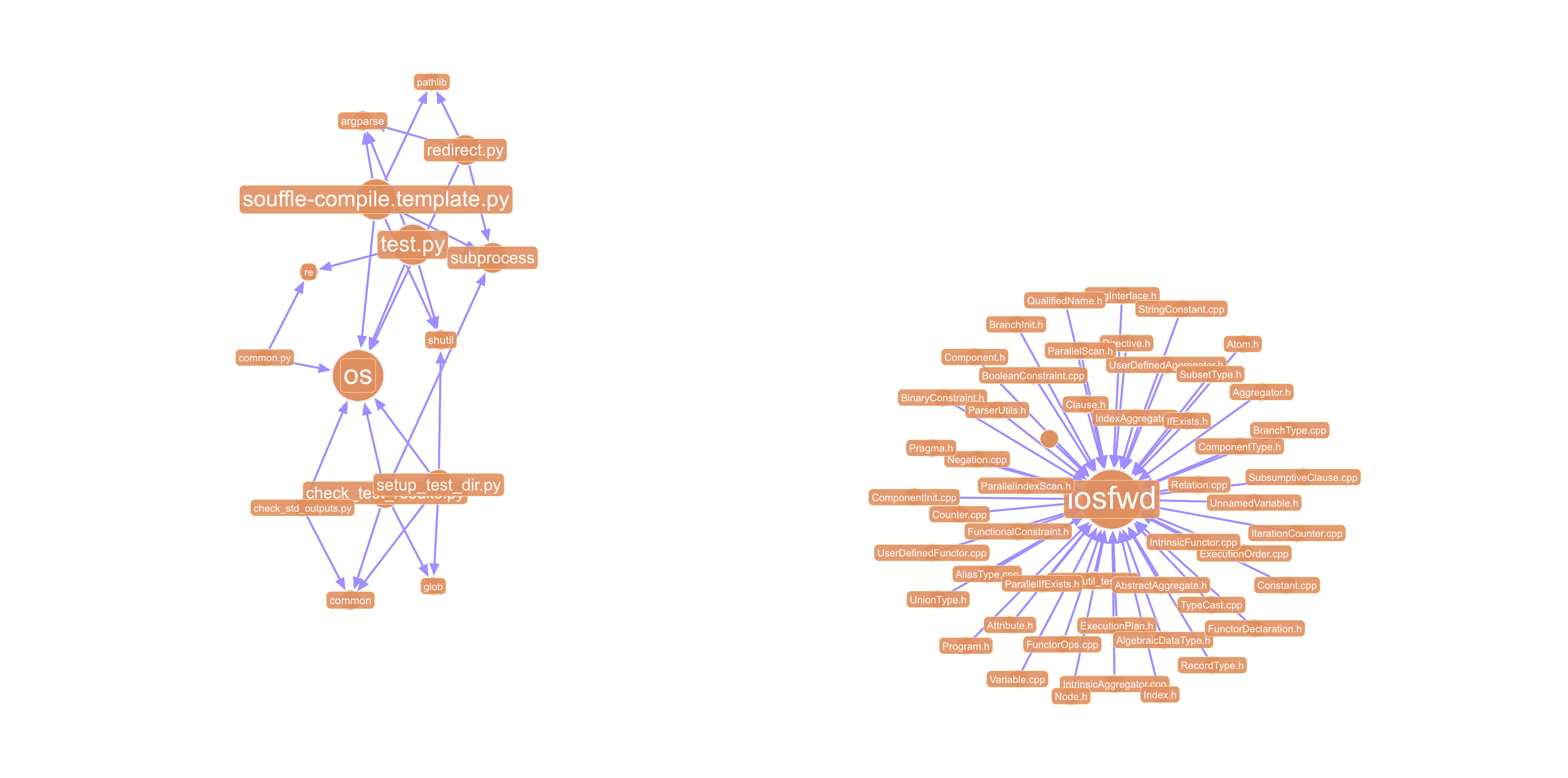
Addressing the Unsuccessful Prompts
Although the SLM were unable to adequately answer our question regarding SQLite integration, the knowledge graph itself retains sufficient structural and semantic information to compensate for these limitations. In other words, even when the LLM layer underperforms, the graph remains a reliable source of grounded insights.
By leveraging gdotv and executing the following Cypher query…
MATCH path = (m:Module)-[:DEFINES]->(element)
WHERE (element:Function OR element:Class)
AND (toLower(element.name) CONTAINS 'sqlite'
OR toLower(element.qualified_name) CONTAINS 'sqlite'
OR toLower(m.name) CONTAINS 'sqlite'
OR toLower(m.qualified_name) CONTAINS 'sqlite')
RETURN path
UNION
MATCH path = (c:Class)-[:DEFINES_METHOD]->(method:Method)
WHERE toLower(method.name) CONTAINS 'sqlite'
OR toLower(method.qualified_name) CONTAINS 'sqlite'
OR toLower(c.name) CONTAINS 'sqlite'
OR toLower(c.qualified_name) CONTAINS 'sqlite'
RETURN path
UNION
MATCH path = (pkg:Package)-[:CONTAINS_MODULE]->(m:Module)-[:DEFINES]->(element)
WHERE (element:Function OR element:Class)
AND toLower(pkg.name) CONTAINS 'sqlite'
RETURN path
…we obtain precise and verifiable results directly derived from the graph structure. The output correctly captures the relevant entities and relationships associated with SQLite.
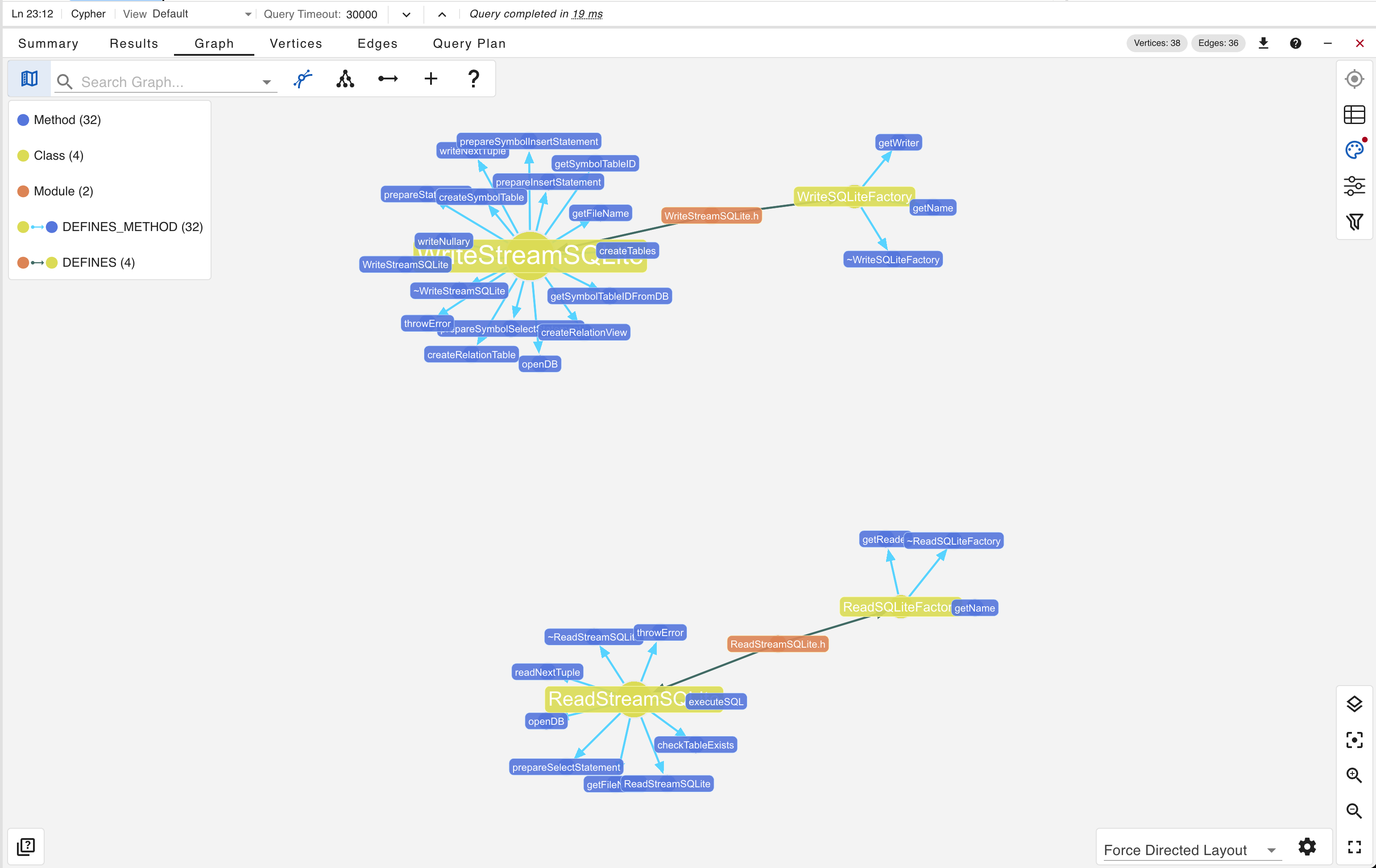
Conclusion
This post kicked off our codebase architectural analysis, created a knowledge graph for inspection, and helped us understand what structural insights of the codebase can be derived from the graph. When inspected directly through gdotv and Cypher queries, the graph revealed both its strengths such as accurate structural extraction and meaningful architectural signals.
That’s it for Part 1 of this two-part series. In Part 2 we’ll examine the structural integrity of the knowledge graph, including schema-completeness, orphan nodes, and the tension between LLM and knowledge graphs for data accuracy. See you next week!
Want to try it out for yourself? Dig into the data with gdotv – query, edit, explore, visualize, and more – with a no-fuss, free 1-month trial.
")

