
Evaluating Codebase-Oriented RAG through Knowledge Graph Analysis [Part 2]
![Evaluating Codebase-Oriented RAG through Knowledge Graph Analysis [Part 2]](https://gdotv.com/wp-content/uploads/2026/03/knowledge-graph-analysis-codebase-oriented-rag-part-2.jpg "Evaluating Codebase-Oriented RAG through Knowledge Graph Analysis [Part 2]")
One common approach to codebase analysis is to use an LLM so you can ask questions and receive natural-language responses and feedback.
Of course, to increase the model’s accuracy, you often need to use codebase RAG to ensure your LLM is giving you accurate answers. This retrieval-augmented generation (RAG) process feeds all your files, packages, classes, functions, and other structural elements from your source code repo into a pipeline into a knowledge graph to further ground and contextualize your LLM (and significantly reduce hallucinations).
In the second part of this two-part blog series, you and I will analyze a codebase RAG knowledge graph. We’ll pursue two main objectives:
- In Part 1 (last week), we performed a codebase architectural analysis – assuming the generated knowledge graph is correct – to understand what structural insights can be derived from it.
- In Part 2 (today), we critically evaluate the structural integrity of the knowledge graph itself – a constructor validation – to assess how faithfully the graph represents the original codebase and explain some notes on expressiveness and semantic completeness, investigating whether the knowledge graph captures sufficient semantic richness to support deeper reasoning tasks.
In both series installments, we use Code-Graph-RAG as a case study, as it represents a recent and notable tool in this space. As the subject codebase, we’ll use Soufflé, a well-known Datalog language and engine. This choice is intentional: it provides a relatively complex C++ codebase with diverse input/output workflows, parallel execution mechanisms, and computationally intensive logical algorithms, making it a suitable benchmark for evaluating the strengths and limitations of codebase-oriented RAG systems.
We’ll also be using a Memgraph graph database to store our knowledge graph and using gdotv to query, explore, and visualize the results.
Okay, let’s get started.
Structural Integrity of the Knowledge Graph
Picking up from last week, now that we’ve looked at the codebase architecture, today we turn to evaluating the knowledge graph itself.
Our primary objective this week is to assess the graph from the perspectives of completeness and structural correctness.
The main responsibility for constructing the graph lies with a parser based on Tree-sitter, which extracts syntactic structures from the source code. The system’s construction logic then links these extracted elements together to form the final knowledge graph.
Schema Completeness: Missing Core Identity Properties
This Cypher query checks for schema completeness by identifying nodes that are missing essential identity properties such as name or qualified_name, depending on their type.
MATCH (c) WHERE (c:Class OR c:Function OR c:Method OR c:Module OR c:Package OR c:Interface OR c:Enum OR c:Type OR c:Union OR c:ModuleInterface OR c:ModuleImplementation) AND (c.qualified_name IS NULL OR c.name IS NULL) RETURN labels(c) AS type, count(c) AS incomplete_entities UNION MATCH (c) WHERE (c:Project OR c:Folder OR c:File OR c:ExternalPackage) AND c.name IS NULL RETURN labels(c) AS type, count(c) AS incomplete_entities
The above query returns an empty result, indicating that all relevant entities contain the required core properties.
Schema Completeness: File Nodes Missing extension
This Cypher query checks for File nodes where the extension property is either NULL or an empty string:
MATCH (f:File) WHERE f.extension IS NULL OR f.extension = "" RETURN f.path AS file, "missing extension" AS issue LIMIT 50
The returned results primarily consist of legitimate extensionless files such as LICENSE, dotfiles (e.g., .gitignore), Debian metadata files, and Dockerfile, all of which naturally lack standard suffixes.
Therefore, the output does not indicate a construction error but rather confirms that the knowledge graph accurately reflects real filesystem semantics, but it shows that the extension property should be treated as optional rather than mandatory.
Relationship Integrity: Orphan Nodes
In this section, we investigate the presence of orphan nodes in the knowledge graph.
Orphan nodes are those entities in the graph data not connected to any other node. Examples include classes not linked to a module, functions not defined or exported by any module, or methods not associated with a class. In other words, considering the expected schema relationships for each node type, we search for nodes that lack all structural edges.
We begin with a type categorization query to identify isolated nodes by label:
MATCH (n) WHERE NOT (n)--() RETURN labels(n) AS label, count(n) AS orphan_count ORDER BY orphan_count DESC;
For our case study based on Soufflé, the result is:
[{
"label": ["Method"],
"orphan_count": 427
}]
This indicates that the only node type with isolated instances is Method, with 427 orphan nodes.
To inspect these nodes directly, we execute this Cypher query:
MATCH (n) WHERE NOT (n)--() RETURN n LIMIT 50
This allows us to create a graph visualization of a subset of the orphan Method nodes and examine them in detail.
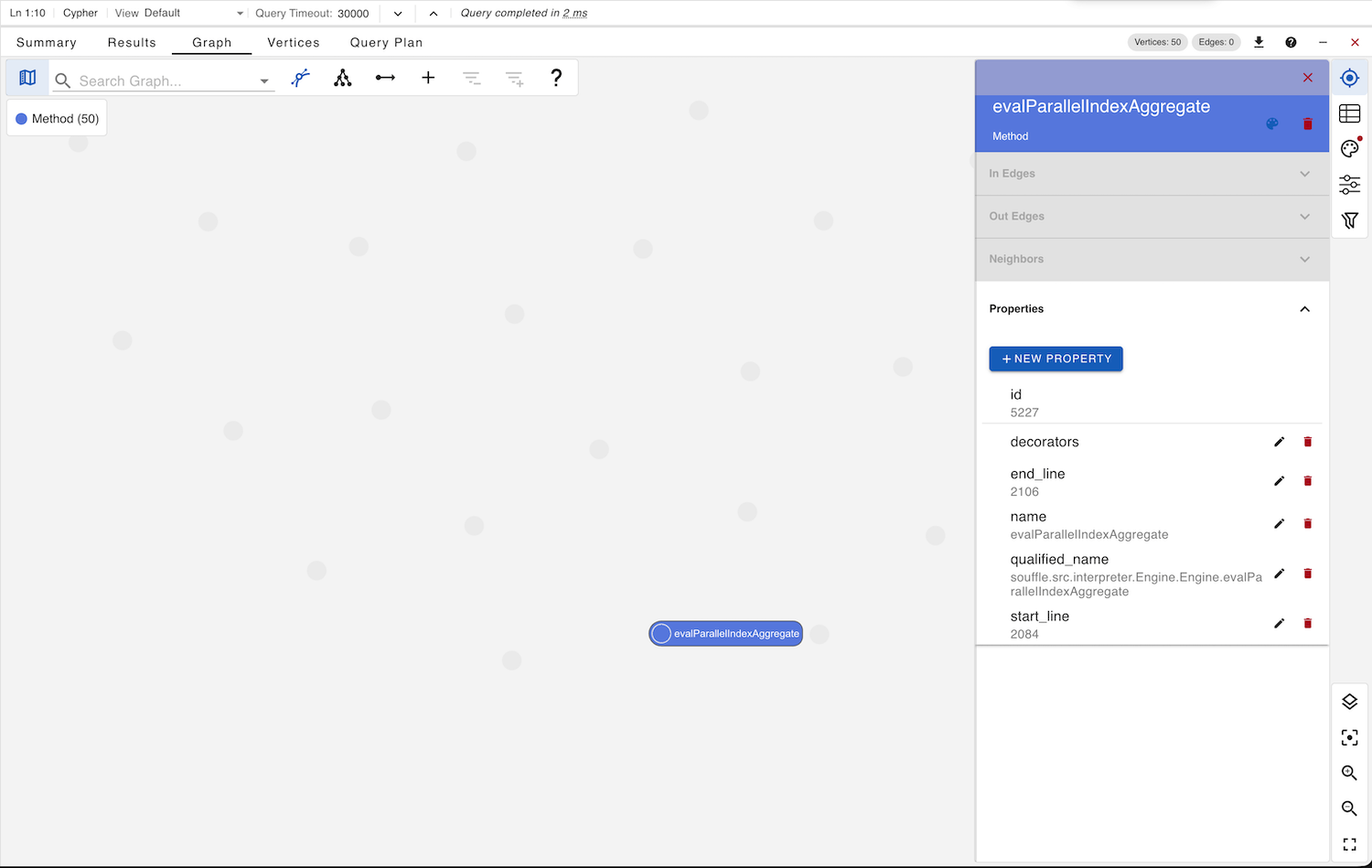
Upon inspection, this reveals a structural flaw in the graph construction process. As above, the orphan method evalParallelIndexAggregate is properly declared in Engine.h and implemented in Engine.cpp, and it is parsed correctly based on the package path and line numbers, yet it appears in the graph without any relationships to its enclosing class or file.
The presence of 427 such orphan Method nodes is therefore a strong red flag regarding the structural integrity of the generated knowledge graph.
Schema Inconsistency: External Modules
While we were busy identifying Module nodes that don’t define or export any entities in the knowledge graph, we executed the following Cypher query:
MATCH (m:Module) WHERE NOT (m)-[:DEFINES]->() AND NOT (m)-[:EXPORTS]->() RETURN m LIMIT 50
The result shows a set of modules that appear structurally empty. Upon inspection, we observe that (apart from modules related to Python packaging and setup) the C++ entries correspond to external modules. These nodes include a boolean property is_external, indicating their external status.
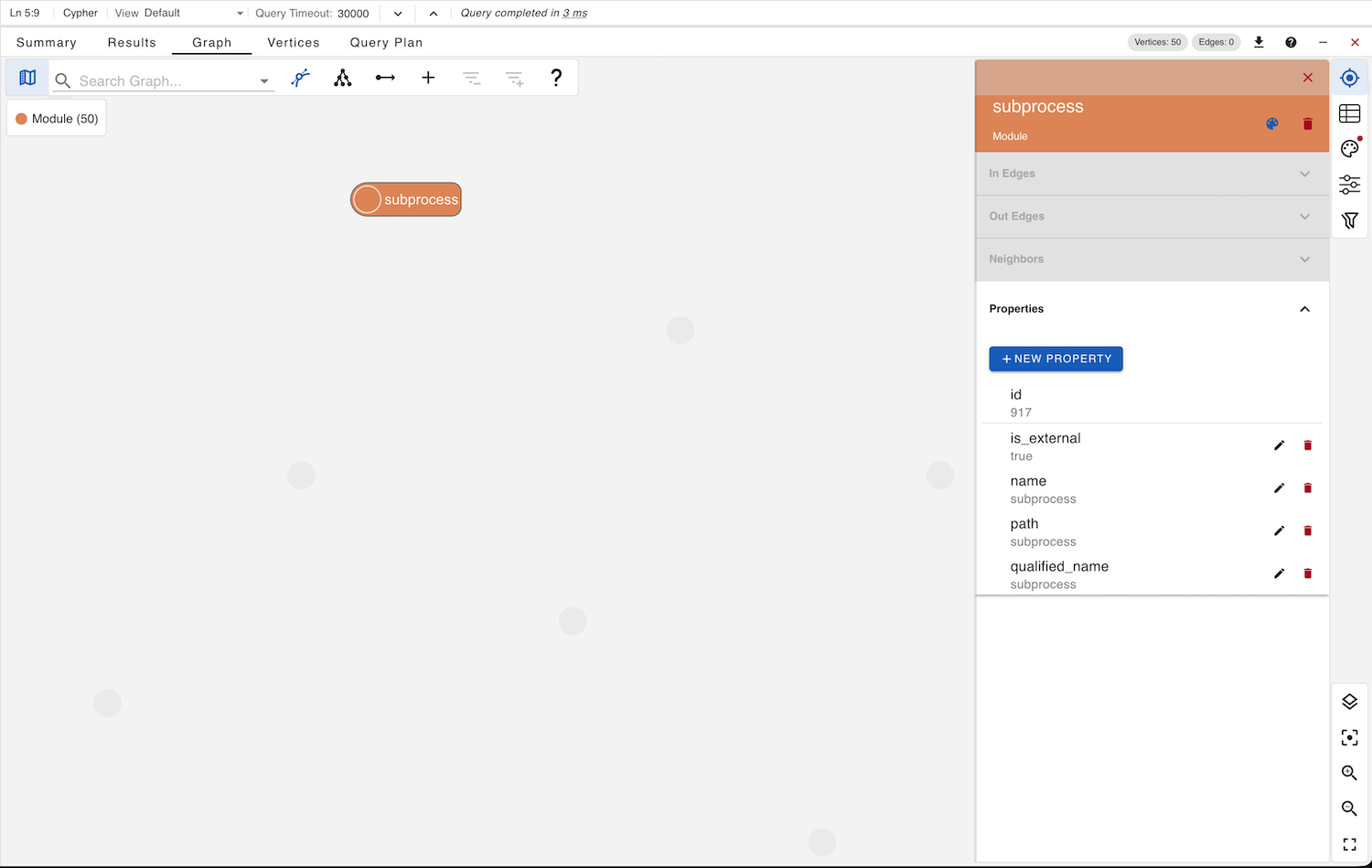
This reveals a schema inconsistency. The system already distinguishes between Package and ExternalPackage using separate node labels, yet for Module nodes, it introduces a boolean flag (is_external) instead of a dedicated ExternalModule label. Moreover, this property is not documented in the schema description.
The Schema View in gdotv confirms the presence of this undocumented field in the Module node definition.
Schema Mismatch: Modules Call Classes!
As observed earlier in the schema view, there exists a surprising relationship: nodes of type Module have a CALLS edge to nodes of type Class. This relation is neither documented in the official schema nor conceptually well-defined.
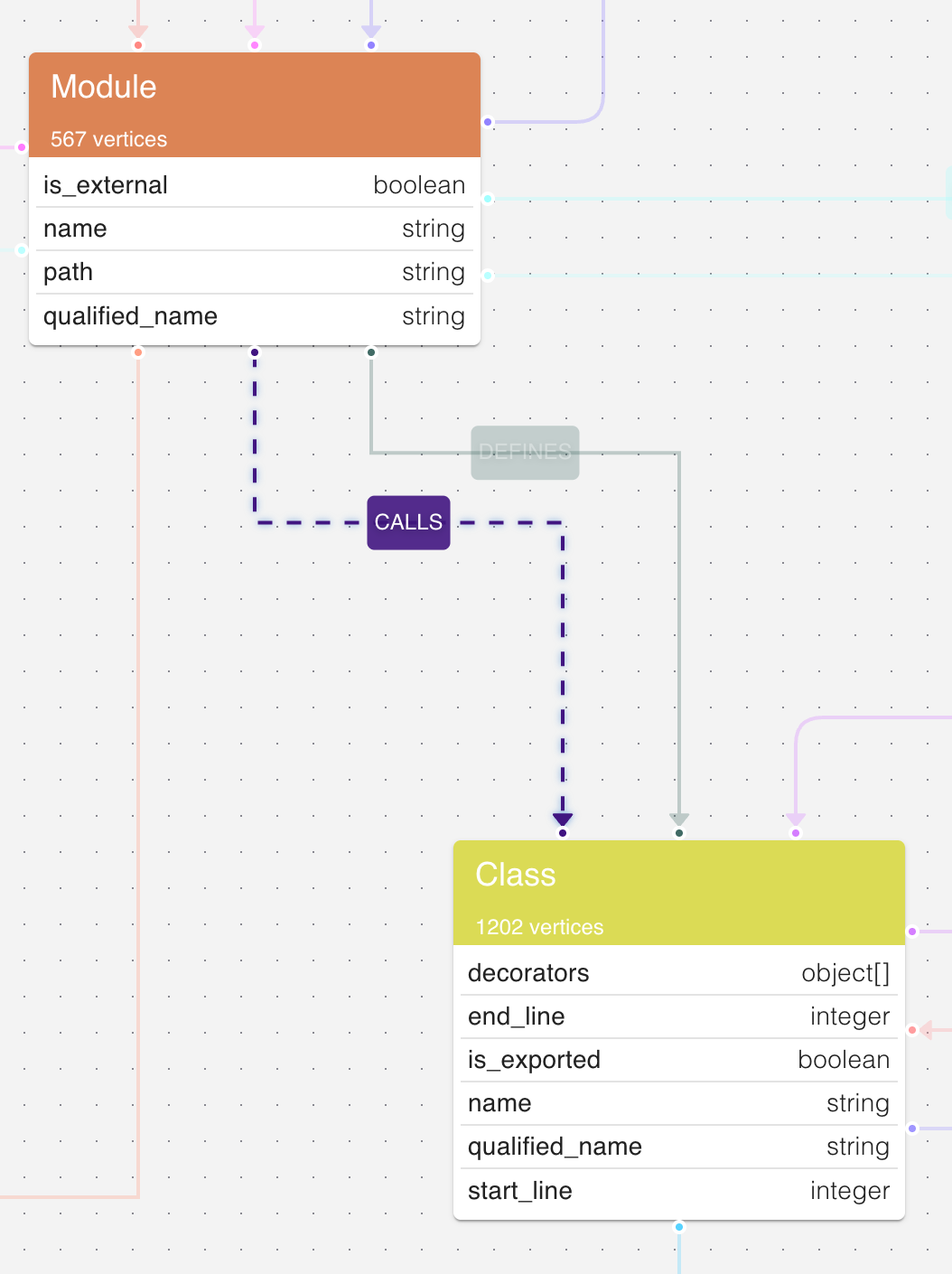
From a language semantics perspective, particularly in C++, a module (or source file) does not call a class. Instead, it may instantiate a class, inherit from it, reference it, or invoke its methods. Therefore, modeling a direct CALLS relationship between Module and Class appears questionable.
To investigate further, we execute this Cypher query which results in the following graph visualization:
MATCH path = (m:Module)-[p:CALLS]->(c:Class) RETURN path
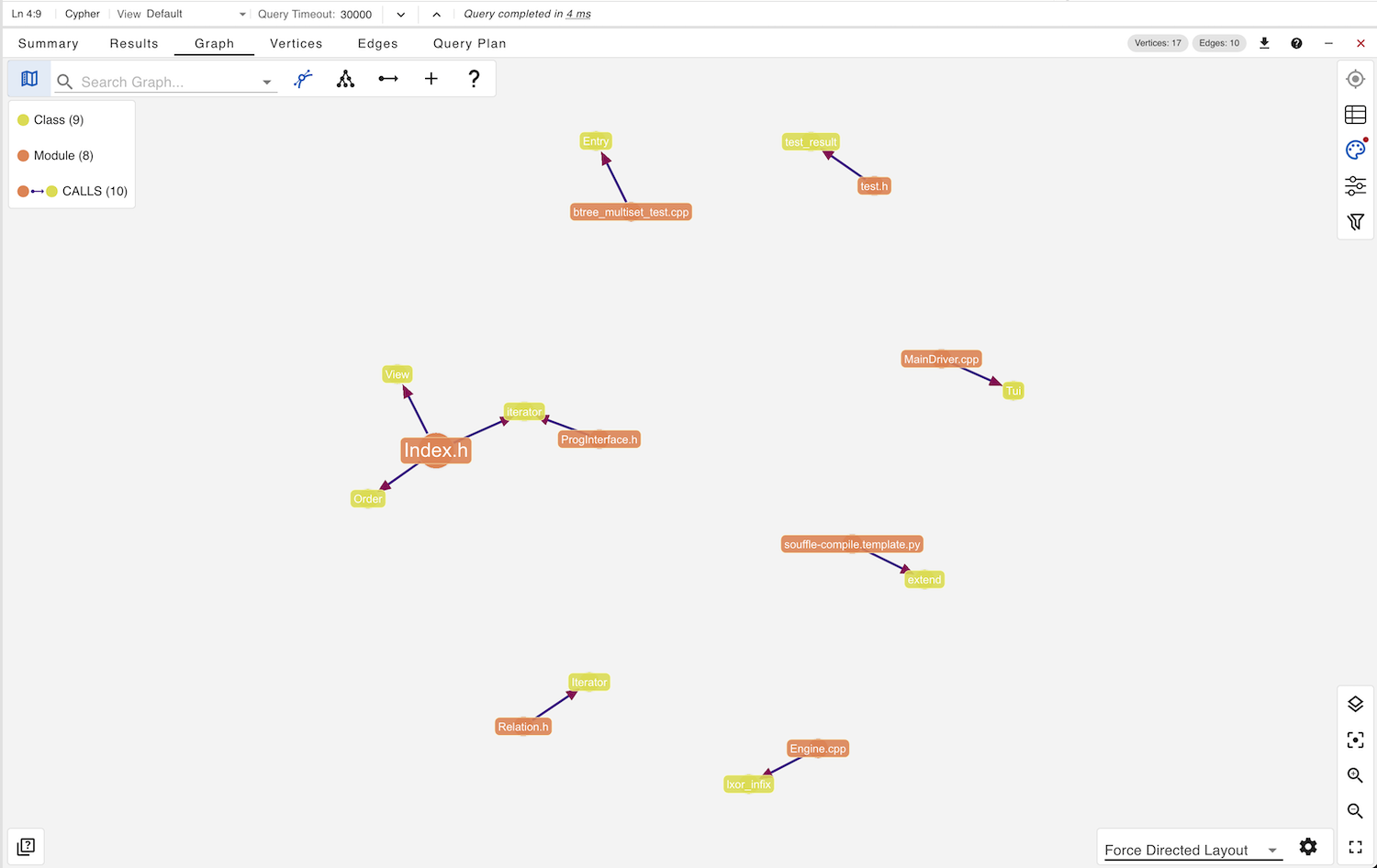
Inspecting one of these paths from Level.h to ValueLevelVisitor and examining the source code reveals the following pattern in the Level.cpp:
namespace souffle::ram::analysis {
std::optional LevelAnalysis::getLevel(const Node* node) const {
// visitor
using maybe_level = std::optional;
class ValueLevelVisitor : public Visitor {
...
Here, ValueLevelVisitor is a locally defined class inside a function scope within the module. The module does not call the class. Rather, it declares and defines it within its translation unit.
This suggests that the graph construction logic may be overloading the CALLS relation to represent structural containment or usage patterns, rather than true invocation semantics. If so, the relation is semantically misnamed and potentially misleading. From a schema design perspective, this is a modeling flaw.
Conclusion
This two-part blog series demonstrates that evaluating a codebase RAG system requires looking beyond prompt quality and language model responses.
While small local models struggled with multi-step reasoning and semantic interpretation, the underlying knowledge graph proved to be the true source of structural truth. When inspected directly through gdotv and Cypher queries, the graph revealed both its strengths such as accurate structural extraction and meaningful architectural signals, and its weaknesses, including orphan methods and schema inconsistencies.
The structural analysis highlights an important distinction: LLM performance and graph quality are independent variables. A weak model can obscure a strong graph, and conversely, a flawed graph cannot be rescued by a powerful model. Therefore, rigorous validation of the knowledge graph schema consistency, relationship integrity, and semantic correctness is essential before evaluating downstream RAG behavior.
Codebase-oriented RAG systems should be treated as graph construction systems first and language systems second. The knowledge graph is the backbone. If the graph is structurally sound, transparent, and semantically coherent, it becomes a deterministic and inspectable foundation for reliable code reasoning.
See for yourself: Explore the data with gdotv – query, edit, explore, visualize, and more – with a no-fuss, free 1-month trial.
![Announcing SPARQL Query Guardrails, Dashboarding, Query Editor Upgrades, & More [v3.53.111 Release Notes]](https://gdotv.com/wp-content/uploads/2026/03/rdf-sparql-query-guardrails-interactive-graph-dashboarding-gdotv-release.jpg "Announcing SPARQL Query Guardrails, Dashboarding, Query Editor Upgrades, & More [v3.53.111 Release Notes]")
![Cypher SET: Updating Node Properties in Your Graph Database [Byte-Sized Cypher Series]](https://gdotv.com/wp-content/uploads/2026/03/set-clause-byte-sized-cypher-query-langauge-video-series.jpg "Cypher SET: Updating Node Properties in Your Graph Database [Byte-Sized Cypher Series]")
")