
G.V() 3.9.32 Release Notes: New Free Tier, Map View, and more!
 3.9.32 Release Notes: New Free Tier, Map View, and more!")
Introduction
The New Free Tier of G.V()
G.V() is often used in new graph projects and proofs of concepts, where scale is not yet fully of concern, but graph database technology adoption is a central challenge for teams. We’ve heard many stories from our customers over the years of how they’ve successfully delivered a graph database project using our software to learn how to query their database, as well as demonstrate the results of their work to stakeholders. We’re very proud to hear how G.V() played an important role in graph database adoption, and would like to do more.
We often discuss ways to improve graph database adoption with our technology partners, and find that learning to shift from constrained, relational data to interconnected graph data is a major change for many. It is certainly one that requires time to learn and practice. Our tool offers many useful learning and assistance features designed to soften the learning curve of query languages like Gremlin.
But with a 1 month free trial limit, and the many conflicting priorities of day-to-day development, users can find themselves needing to decide on adoption of tooling like G.V() too early in their proof of concept. To address this, we are now offering a no sign-up, unlimited free tier of G.V() automatically available for any graph database with below 500 vertices and 500 edges. Along our already free to use in-memory graph feature, we’re delivering a feature-rich tool crucial to early-stage graph database projects.
The free tier can be accessed automatically by connecting to your graph database – if it is free tier eligible, you’ll be presented with the following message:
Using our free tier also does not impact your ability to sign up for a free trial later on – so once your graph database starts to scale, you can still get up to 1 additional month of G.V() for free by signing up for a trial.
Visualize your Graph Data with a Map Overlay
Often times, graph data stores properties that represent the geographical location of an entity. Analyzing geographical data is a common use case that G.V() 3.9.32 now supports with an optional map overlay layer on the graph view.
This feature lays out your graph data according to latitude and longitude values extracted from vertex properties, with an interactive map display underneath. It’s easily configurable and can be toggled in one-click, with the ability to save a configuration of the properties to be used for lat/lon values.
As always a demo speaks a thousands words so here’s a quick snipped showing this feature:
New Graph Layout Configuration Options
G.V() comes packed with standard graph layout algorithms optimized for a variety of graph structure archetypes (hierarchical, dense, sparse. clustered). These algorithms are automatically configured on G.V() with sensible settings based on the structure of your graph, that provide an optimized output on the graph.
However some of these algorithms provide useful options for users that can now be configured manually. In addition to that, we’ve added a new algorithm, Circlepack. which is optimized for cluster layout. Circlepack simply requires specifying one or more property identifying the community a verteex belongs to, and the layout will do the rest. Check it out:
We’ve also tuned default algorithm settings and graph camera handling for an overall better user experience.
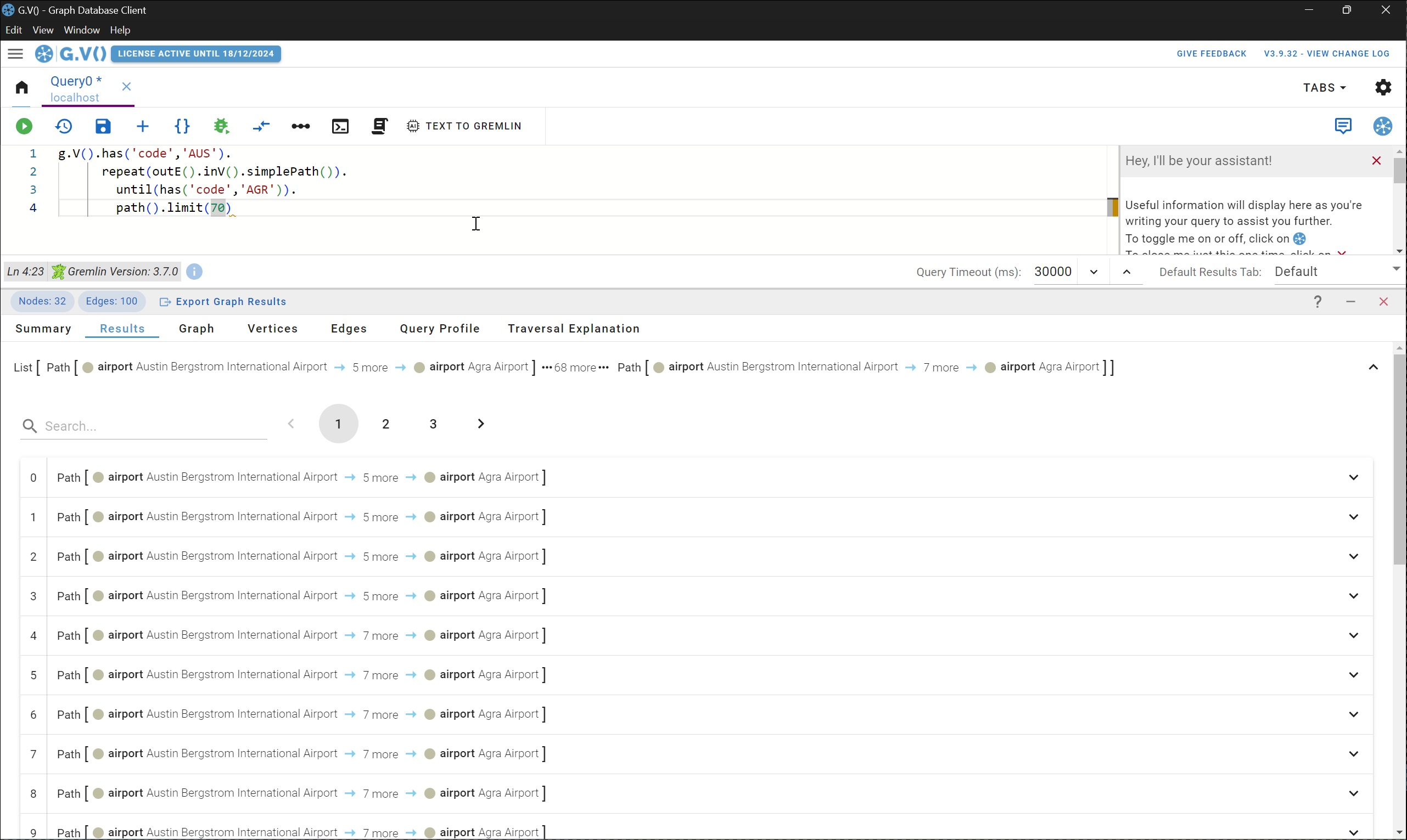
Improved Results Display User Experience
One of our data visualization option, the “Results” tab, offers a convenient way to browse data regardless of its structure. It’s filterable and efficient, meaning you can navigate complex object results with ease. In previous versions however the overall display was just…not pretty. We’ve reworked the display to not just look better but convey essentil information of the records you’re browsing in just a glance. See for yourself:
Everything Else in this New Version
As with every new release of G.V(), additional minor changes and bug fixes are part of this update. Apart from a few user experience bug fixes, we’ve also changed/added the following:
- Improved UI of the graph stylesheet sidebar
- Added ability to change and save the graph viewport’s background color
- Updated documentation look and feel
- Graph data explorer search can now be cancelled
- Elements in the graph data explorer can now be retained in the viewport between searches
- Added ability to specify a default Gremlin/Cypher query when opening a new query editor
Conclusion
This release marks the end of 2024 for us – as the holiday season nears this will be our last feature release of the year. We’re working hard on the January 2025 update which will feature a new set of major upgrades for G.V() as a solution. 2025 will be the year we expand the horizon of our product beyond the Apache TinkerPop ecosystem, and offer new ways to deploy and use G.V() in organizations.
To keep track of all the latest news on our product make sure to follow us on LinkedIn where we regularly post developer previews, announcements and other news, such as our attendance of the Knowledge Graph Conference next year in New York!
Until next time.
, a GQL Playground, a Knowledge Graph of Your Vibe Code & More")
![Cypher DISTINCT: Removing Duplicates from Results [Byte-Sized Cypher Series]](https://gdotv.com/wp-content/uploads/2026/02/distinct-clause-byte-sized-cypher-query-langauge-video-series.jpg "Cypher DISTINCT: Removing Duplicates from Results [Byte-Sized Cypher Series]")
