The Weekly Edge: RDF Inference, Yugabyte MAGE, Visualization with Apache AGE

Happy Thursday!
We’re back at it, once again keeping you updated on the latest graph news.
Headlines this week:
- “I am once again asking you to follow the rules.” Pieter Colpaert illustrates how to make the most of N3 rules along with a number of runnable demos.
- You get a database, and you get a database (etc. etc.): A new version of Yugabyte introduces per-agent Postgres databases, along with other features like Yugabyte MAGE with graph functionality.
- Visualization for the AGEs: Christian Miles talks through visualization with Apache AGE.
- Schema without the scheming: TRACE-KG illustrates a framework that builds knowledge graphs and schema without a pre-defined ontology.
- Who said what now? Researchers in Bologna have devised a DEC framework to handle concepts of provenance.
/* * It’s time to level up your graph game: * Query, explore, edit, and visualize your connected data with the gdotv graph IDE * Try out the free dev tier or upgrade to a 1-month, no-fuss free trial. */
If you’re new here, the Weekly Edge is your weekly tl;dr of graph technology news curated by the team at gdotv, giving you all the reads, repos, vids, and walkthroughs worth exploring from the past seven-ish days (or so).
/*
*/
[Tutorial]: Stop Hand-Aligning Your Ontologies. Let the Rules Do It

Anyone who’s worked with Linked Data has heard the pitch that it lets you align data automatically, then watched everyone quietly go back to spreadsheets and manual mappings. Pieter Colpaert opens with exactly this gripe. A decade-old conversation where a Transmodel Ontology lead asked him why she’d bother with RDF when the Linked Data crowd was still aligning everything by hand.
His answer, post-SHACL and post-agentic-AI, is to stop writing rules about your domain and start writing them about the ontology language itself. Instead of a separate rule for HydrogenBus, CargoBike and ElectricFerry, you write generic N3 rules once against primitives like rdfs:subClassOf, and each project just annotates its own vocabulary. From there he layers OWL 2 RL, SKOS and SHACL together — and reframes SHACL not just as a gatekeeper but as another flavour of inferencing, where the derived knowledge is the validation report itself. The really clever bit is using shapes as optimization hints for stream processing: work out the reasoning plan once, then apply a compact runtime to every message that matches the shape.
Best of all, the whole post is stuffed with editable in-page demos powered by his new rdfjs-inference-engine (now on npm) and Eyeling.
[News]: A Postgres For Every Agent (Yes, Every Single One)

Yugabyte has decided that if Gartner is right and the average Fortune 500 will be running 150,000-odd AI agents in a couple of years, then those agents are going to need somewhere to put their data. Their answer is YugabyteDB AMP (Agentic Multitenant Postgres), launched alongside YugabyteDB 2026.1.
The pitch is “the growth cliff”, the familiar pattern where a prototype runs on cheap serverless Postgres with a vector store bolted on, then ships, scales, and triggers a painful migration crisis. AMP’s fix is scale-to-zero serverless multitenancy where each agent gets its own real, isolated Postgres database, and every lifecycle operation (provisioning, branching, scaling, migration, teardown) is exposed over MCP rather than just a read endpoint.
For us graph folks, the interesting line item is YugabyteDB MAGE, a multi-tenant graph engine (in technical preview) sitting alongside native vector search and in-database RAG. The whole strategy is convergence: fold the primary database, vector store, graph layer and pipeline glue into one system instead of stitching five together.
Whether agents really want their own database is a debate for another newsletter, but the graph-on-relational momentum is hard to ignore.
[Talk]: Querying & Visualizing Graphs in Postgres with Apache AGE

In his POSETTE 2026 talk, Christian Miles walks through what works and what breaks when you try to visualize Apache AGE query results, explaining that layouts obscure rather than reveal, node-link diagrams that turn to spaghetti at modest scale, and interaction patterns that fall apart when graphs get dense.
The framing is one we’d happily co-sign: AGE lets you store graphs inside Postgres and embed Cypher in SQL, but the usual database tooling was never built to actually show you a graph while graph results need visualization designed for connected data, not approaches that flatten everything back into rows. Drawing on fifteen years of building graph visualization tools, Miles covers when to reach for force-directed layouts versus layered or topology-aware ones. If you’re running AGE and squinting at result tables, this one’s for you. (And naturally, if you’d like to connect a proper IDE to your AGE instance, you know where we are.)
[Paper]: TRACE-KG: Build the Graph and the Schema, No Ontology Required
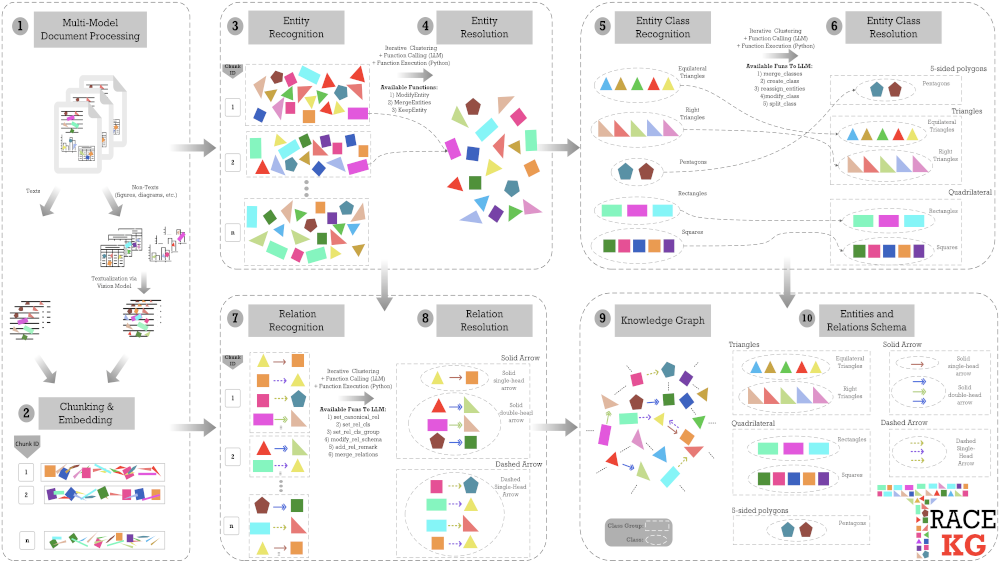
Knowledge graph construction usually forces an awkward choice. Ontology-driven pipelines give you consistent typing but cost a fortune in schema design and maintenance; schema-free extraction is cheap but produces fragmented graphs where the same entity shows up under five names and near-duplicate predicates proliferate. TRACE-KG, out of Arizona State, tries to have it both ways.
It’s a multimodal framework that constructs a context-enriched knowledge graph together with an induced schema (no predefined ontology) while keeping full traceability back to the source text. Two ideas stand out. First, conditional relations: rather than flattening everything into unconditional triples, it attaches structured qualifiers capturing when and under what conditions a relation holds. Second, auditable construction: the LLM never edits the graph directly. It emits a JSON array of actions like MERGEENTITIES that deterministic validators then execute and log.
The evaluation has a nice bit of methodological spine, too. They argue raw retrieval accuracy is misleading and introduce metrics that penalise “leakage” (copying long text spans into entity strings) and structural fragmentation. On those, TRACE-KG holds high accuracy with dramatically lower leakage than the baselines. A good read if you’re building text-to-graph pipelines and tired of the schema/no-schema dichotomy.
[Paper]: “According to…” Is Doing More Work Than Your Graph Admits

A wonderfully heady note to end on. Vitali and Pasqual (Bologna) point out that huge swathes of real knowledge graphs aren’t facts at all! They’re capta: claims, interpretations and hypotheses, like who painted the Salvator Mundi, where provenance isn’t optional metadata but the whole reason a statement is even in the graph.
The problem: today’s provenance models (PROV-O, Wikidata’s rankings, plain reification) deliberately stay semantically neutral. Attaching a source isn’t supposed to change a statement’s truth conditions. But that means a graph holding two scholars who disagree either collapses into a contradiction or loses the disagreement entirely, when the divergence is itself meaningful. Their DEC framework reads provenance predicates as signals of epistemic stance (“wrote” vs “believed” vs “supposed”) and groups statements with similar provenance into cognitive worlds, drawing on doxastic, epistemic and conjectural modal logics. That lets a graph reason over attributed claims, and explicitly surface disagreements and “delusions,” without everything dissolving into inconsistency, and it sidesteps the old reasoning headaches like the Superman paradox.
(The “Superman paradox” refering to a sticky region of semantics: without careful reasoning, the statements “Lois Lane believes Superman can fly” and “Superman is Clark Kent” could easily erroneously imply “Lois Lane believes Clark Kent can fly”.)
The lovely practical kicker: there’s a working prototype reasoner built as an Apache Jena Fuseki dataset module, and it works the same across named graphs, RDF-star quoted triples and classic reification. Pairs neatly with the TRACE-KG provenance story above. And be aware! Two papers, same week, both insisting that where a statement came from deserves to be a first-class citizen.
P.S. Postgres 19 is on the horizon, and looks like it might bring a few graph-ish updates along for the ride. More from the Weekly Edge on that next time!
P.P.S. If you didn’t catch the latest Graph Pulse, gdotv checked in with PuppyGraph CEO Weimo Liu on just why graphs are so popular right now!
P.P.P.S. Got an item to nominate for the next edition of the Weekly Edge? Hit me up at weeklyedge@gdotv.com or hit reply! ✍🏽


