Apache AGE Explained: how does it work and how does it fit in the Graph Database Landscape?

This post is a deep dive into Apache AGE: A Graph Extension for PostgreSQL. We’ll cover what AGE is, where it came from, and how it works. We’ll also look at AGE within the wider graph-database ecosystem to see how it compares to current and upcoming technologies such as the SQL/PGQ standard in PostgreSQL 19, and native graph databases such as Neo4j, JanusGraph and FalkorDB.
By the end you should have a clear picture of what AGE is, how it works, and where it fits.
This is part 1 of a 4-post series. The next three posts walk through deploying AGE, loading data into it, and exploring it visually with gdotv.
What is Apache AGE?
Apache AGE (A Graph Extension) is a Postgres extension that adds graph database capabilities to a regular Postgres server. AGE offers openCypher language support which is based on Cypher, a property-graph query language originally created by Neo4j.
It’s the most widely adopted graph query language to date and the main inspiration behind the ISO GQL (Graph Query Language) standard. AGE lets you store and query property graphs alongside your relational tables, in the same database, on the same connection.
It started life at Bitnine (a Korean Postgres consultancy) as the proprietary “AgensGraph” before being open-sourced and donated to the Apache Software Foundation, where it has been a top-level project since May 2022.
The headline pitch is appealing: keep your existing Postgres operational know-how, add a graph workload, no new database to babysit. As a side benefit, AGE inherits everything Postgres is rightly known for: its maturity, its resilience, its backup and recovery capabilities, its replication and high-availability options, and its rich observability ecosystem.
Postgres is one of the most mature and most widely deployed databases in the world, and any graph stored in AGE rides on top of all of it.
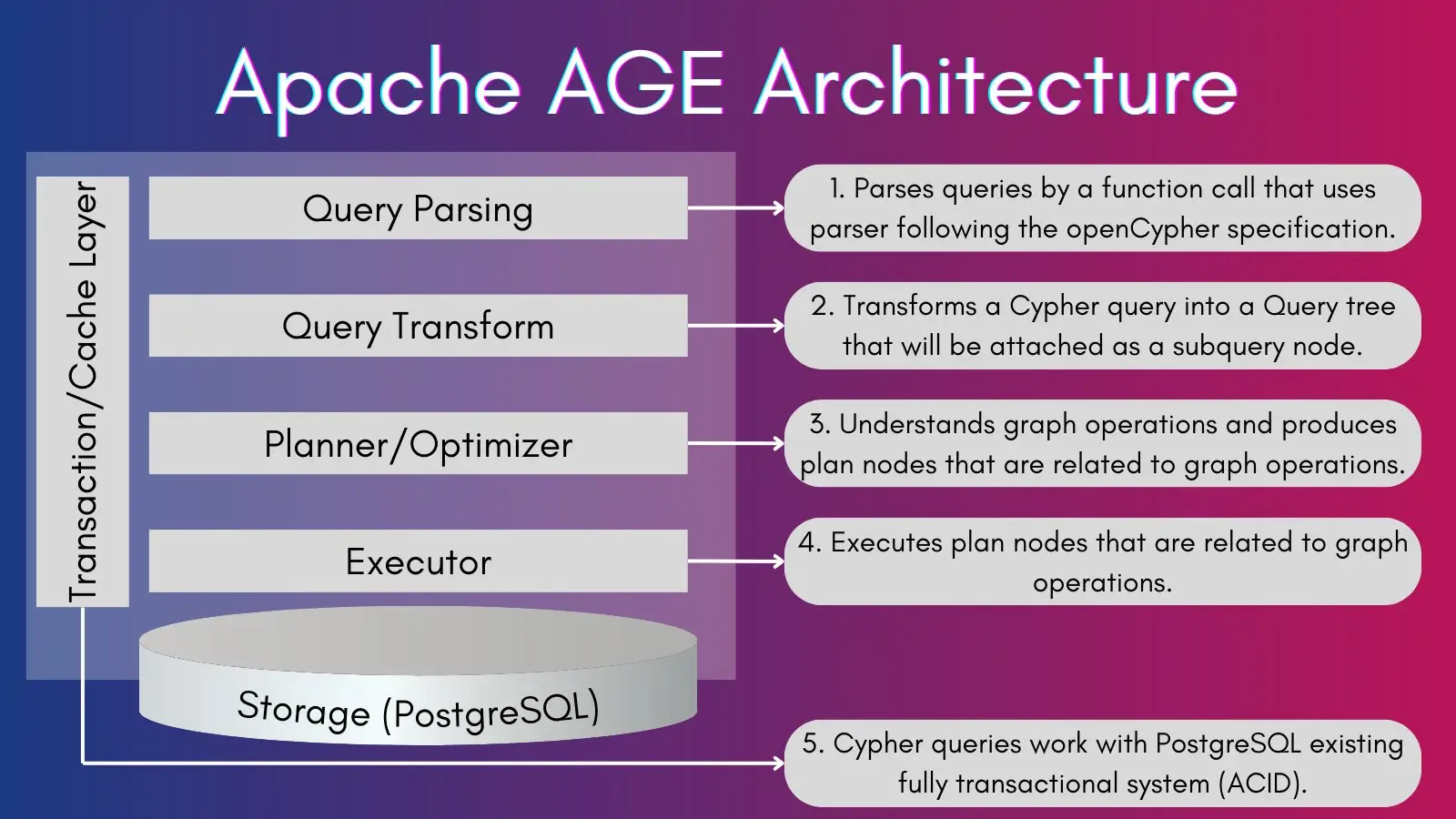
An overview of the Apache AGE architecture from their official website
Now that we’ve covered the broad strokes of what Apache AGE is and where it came from, let’s dive deeper into how it works.
The Cypher dialect AGE supports
AGE implements a subset of openCypher. If you’re coming from Neo4j, the everyday surface area is familiar (MATCH, WHERE, RETURN, CREATE, MERGE, WITH, parameters, basic functions), but the corners differ:
- No advanced graph analytics algorithms out of the box. AGE doesn’t ship the kind of pre-built procedures Neo4j users get from the APOC library (centrality, community detection, pathfinding heuristics, and so on). Anything along those lines you’ll need to build yourself or fall back to SQL for.
- Limited list and string functions. The most common are present (
size,head,tail, basicsubstring, etc.); the long tail isn’t. - Path semantics are pragmatic, not exhaustive. Variable-length paths work (
-[*1..5]->), but more exotic patterns (full path projections, complex predicates inside path patterns) hit edges. - Parameters. Cypher parameters are passed as a single AgType map alongside the SQL
cypher()call. Most client libraries (and tools like gdotv) hide this from you, but if you’re calling AGE directly via JDBC or psql, expect one parameter slot, not N.
The Cypher-to-SQL wrapping itself looks like this:
SELECT * FROM cypher('air_routes', $$
MATCH (a:airport {code: 'LHR'})-[:route]->(b:airport)
RETURN b.code, b.city
$$) AS (code agtype, city agtype);
The AS (...) clause is required and must match the number and order of RETURN items. Forgetting it is the most common “why won’t this query run?” cause.
This creates some friction particularly when developing your queries but it does enable a fairly substantial level of support for openCypher within Postgres.
To reduce that friction, gdotv handles this wrapping automatically: you write Cypher directly in the editor (with autocomplete and syntax validation) and gdotv translates it to the equivalent cypher(...) AS (...) SQL automatically. The same editor also lets you drop down to raw SQL whenever you need it, with or without an embedded Cypher block, which is handy for queries that mix graph and relational logic. We’ll come back to this in part 4 of this blog series. For now, let’s move on to how AGE stores graph data.
How AGE stores graph data
Before you can store any graph data in AGE, you need to create a graph:
SELECT create_graph('my_graph');
Behind the scenes, this creates a new Postgres schema named my_graph and registers it in AGE’s system catalog. Two system catalog tables drive everything:
ag_catalog.ag_graph: one row per graph. Stores the graph name and the OID of its schema.ag_catalog.ag_label: one row per label (vertex labels, edge labels). Stores the label name, the graph it belongs to, the kind (vfor vertex,efor edge), and the OID of the Postgres table that physically holds the label’s data.
Every label is its own Postgres table. So if you have a graph called air_routes with labels airport and route, you end up with two physical tables (one for airports, one for routes), both living under the air_routes schema.
Vertex tables look like this:
| Column | Type | Notes |
|---|---|---|
id |
graphid |
64-bit composite of label-id + local sequence |
properties |
agtype |
All vertex properties live in this one column |
Edge tables add two more columns:
| Column | Type | Notes |
|---|---|---|
id |
graphid |
The edge’s own id |
start_id |
graphid |
Pointer to the source vertex’s id |
end_id |
graphid |
Pointer to the destination vertex’s id |
properties |
agtype |
All edge properties |
The implication: a Cypher MATCH (a:airport)-[r:route]->(b:airport) translates, internally, into a Postgres join across the airport and route tables, with predicates on start_id/end_id. AGE is essentially a Cypher → SQL compiler, and the compiled SQL operates on regular Postgres tables. There’s no exotic graph engine running underneath. It’s just Postgres’s planner, with all its strengths (mature, robust, well-understood) and limitations (no graph-aware index structures, no specialized traversal operators).
You can even poke at the catalog directly:
SELECT * FROM ag_catalog.ag_graph;
SELECT name, kind, relation FROM ag_catalog.ag_label
WHERE graph = (SELECT graphid FROM ag_catalog.ag_graph WHERE name = 'my_graph');
AgType: the type that holds everything
agtype is the Postgres composite type AGE uses to store all property values, all return values from Cypher queries, and the structured representations of vertices and edges themselves. If you’ve worked with Postgres jsonb, AgType will feel familiar: it’s a tagged value that can hold:
- Scalars: integers, floats, strings, booleans, null
- Containers: lists and maps (objects)
- Graph structures: vertex, edge, path
When a Cypher query returns a vertex, you don’t get back a row of typed Postgres columns. You get a single AgType value that represents the whole vertex (its label, its id, its properties map). Same for edges and paths.
That’s powerful: it means AGE can return graph-shaped data without flattening it. It’s also the source of friction: every time you want to use a value returned from Cypher in regular SQL (feed it to a JOIN, compare it against a typed column, pass it to pg_typeof), you have to cast it out of AgType into a plain Postgres type.
Where AGE sits in the graph-database landscape
There’s no single “best graph database”. There are databases that fit different operating profiles. Here’s how AGE compares to three relevant alternatives, each chosen for the architectural ground it shares with AGE. There are many other alternatives available and worth discussing that we won’t cover in this post for the sake of brevity.
vs Postgres 19 SQL/PGQ: the standard is coming
The SQL:2023 standard introduces SQL/PGQ (Property Graph Queries), and Postgres 19 is the first Postgres release expected to ship support. SQL/PGQ adds a GRAPH_TABLE(...) operator that lets you write graph pattern queries directly in SQL, against a graph defined as a property graph view over your existing relational tables.
This is meaningful because it’s a genuinely different design point from AGE:
- Schema-first vs schema-flexible: SQL/PGQ requires you to declare your graph (which tables map to vertex labels, which map to edge labels, which columns are which properties). AGE lets you
CREATEa vertex with any label and any properties, and only enforces what you explicitly enforce. - Standard vs extension: SQL/PGQ is part of the SQL standard, which means portable querying across vendors that implement it. AGE is a Postgres extension following the openCypher dialect, with its own community.
- Available now vs later: AGE works on Postgres 12+ today. SQL/PGQ is upcoming in Postgres 19.
If you’re picking a long-term technology and graph-on-relational is the right shape for your problem, both are credible, and the right answer depends on whether you value openCypher familiarity (AGE) or eventual SQL-standard portability (SQL/PGQ). They may even coexist on the same database in time.
vs native graph databases: Neo4j, FalkorDB, Memgraph
Native graph engines like Neo4j (disk-based), FalkorDB (Redis-based), and Memgraph (in-memory) store graphs in formats designed for graph traversal from the ground up. Their planner has graph-aware operators; their indexes are graph-aware; their performance on traversal-heavy queries reflects that.
The trade-off is shape:
- Native graph DBs are another database to operate, with their own backup model, their own replicas, their own observability story. If your application is graph-first, that overhead pays for itself.
- AGE is a Postgres extension. If your application is mostly relational with a graph workload bolted on, AGE’s “no new database” pitch is genuinely valuable.
Performance-wise: for deep multi-hop traversals on large graphs, native engines win. For shallow queries on modest graphs, the gap is much smaller, and AGE is often “good enough”.
vs JanusGraph: same idea, different stacks
JanusGraph and AGE both rest on the observation that you don’t need to invent new storage to do graph queries; you can layer graph computing on top of an existing storage engine. JanusGraph picks distributed wide-column stores (Cassandra, HBase, Bigtable, ScyllaDB) and exposes Gremlin (the Apache TinkerPop language). AGE picks Postgres and exposes Cypher.
Where they diverge:
- Distribution: JanusGraph is built for clustered, horizontally-scaled deployments from day one. AGE is single-node Postgres. If you need a graph that spans multiple machines, JanusGraph is the more natural fit; if you want one Postgres box doing graph alongside other work, AGE is.
- Performance and scale: JanusGraph uses the Apache TinkerPop graph computing framework and delivers its own optimizations for large-scale graph query processing. eBay published a series of articles showcasing this quite well.
- Query language: JanusGraph uses the Gremlin query language, which is imperative and traversal-shaped. Cypher is declarative and pattern-shaped. This comes down to personal preference but Gremlin and Cypher are fundamentally different graph querying languages.
- Operational footprint: AGE inherits Postgres’s mature operational ecosystem (backups, replicas, monitoring). JanusGraph sits on top of a different but comparably mature infrastructure stack (Cassandra, HBase, ScyllaDB, etc.), which delivers a similar set of operational guarantees once it’s properly deployed and tuned, with the trade-off of having more moving parts to operate.
When AGE is a fit (and when it isn’t)
AGE is a good fit when:
- Postgres is already your primary database and operational center of gravity.
- Your graph workload is one workload among several, not the whole application.
- You want Cypher’s ergonomics and don’t need a deep catalog of pre-built graph analytics procedures.
- Your graph fits comfortably on a single Postgres box (or you’re willing to scale Postgres vertically and via replicas).
AGE is probably not the right call when:
- Graph traversal performance at scale is the application: go native.
- You need horizontal sharding of the graph itself: look at JanusGraph or a distributed native engine.
- You depend on advanced Cypher features or rely heavily on APOC-style graph analytics procedures: Neo4j or Memgraph will be a closer fit.
- You need rigorous schema enforcement on the graph: wait for SQL/PGQ in Postgres 19, or use a schema-first native engine.
The most useful framing: AGE optimizes for “I already have Postgres, and I have some graph things to do.” If that sentence describes you, AGE is worth a serious look. If it doesn’t, the alternatives are likely better aligned with what you actually need.
What’s next in this series
- Part 2: Running Apache AGE: Docker Quickstart and Cloud Postgres Provider Landscape. Where you can actually deploy AGE today: who supports it (Azure), who doesn’t (AWS RDS, Aurora), and who’s pointing elsewhere (Supabase → pgRouting). Includes a copy-pasteable local Docker setup.
- Part 3: Loading Data into Apache AGE: A Practical Guide with the Air Routes Dataset. Loading the air routes dataset via
agload, AGE’s built-in CSV loader, with notes on CSV format expectations and property type inference. - Part 4: Visualizing Apache AGE: Connecting gdotv and Exploring the Air Routes Graph. Connecting gdotv to your AGE instance and exploring the loaded graph: schema discovery, Cypher editor, graph visualization, neighbor expansion.
")
