
G.V() 3.14.38 Release Notes: Now with Support for Neo4j, Memgraph, Neptune Analytics, Query Editor Improvements, and more!
 3.14.38 Release Notes: Now with Support for Neo4j, Memgraph, Neptune Analytics, Query Editor Improvements, and more!")
Introduction
Graph Database Support Expansion
This is the first wave of graph database support expansion on G.V(). In the near future, you’ll be able to interact with even more graph databases using Gremlin, Cypher and many more query languages we’re working on integrating in G.V().
For now, here is the list of newly supported databases:
- Neo4j, version 4.4 and above
- Neo4j AuraDB, version 4.4 and above
- Memgraph, version 2.0 and above
- Amazon Neptune Analytics, all versions.
As always, connecting to these newly supported technologies is easy as 1-2-3, as illustrated below:
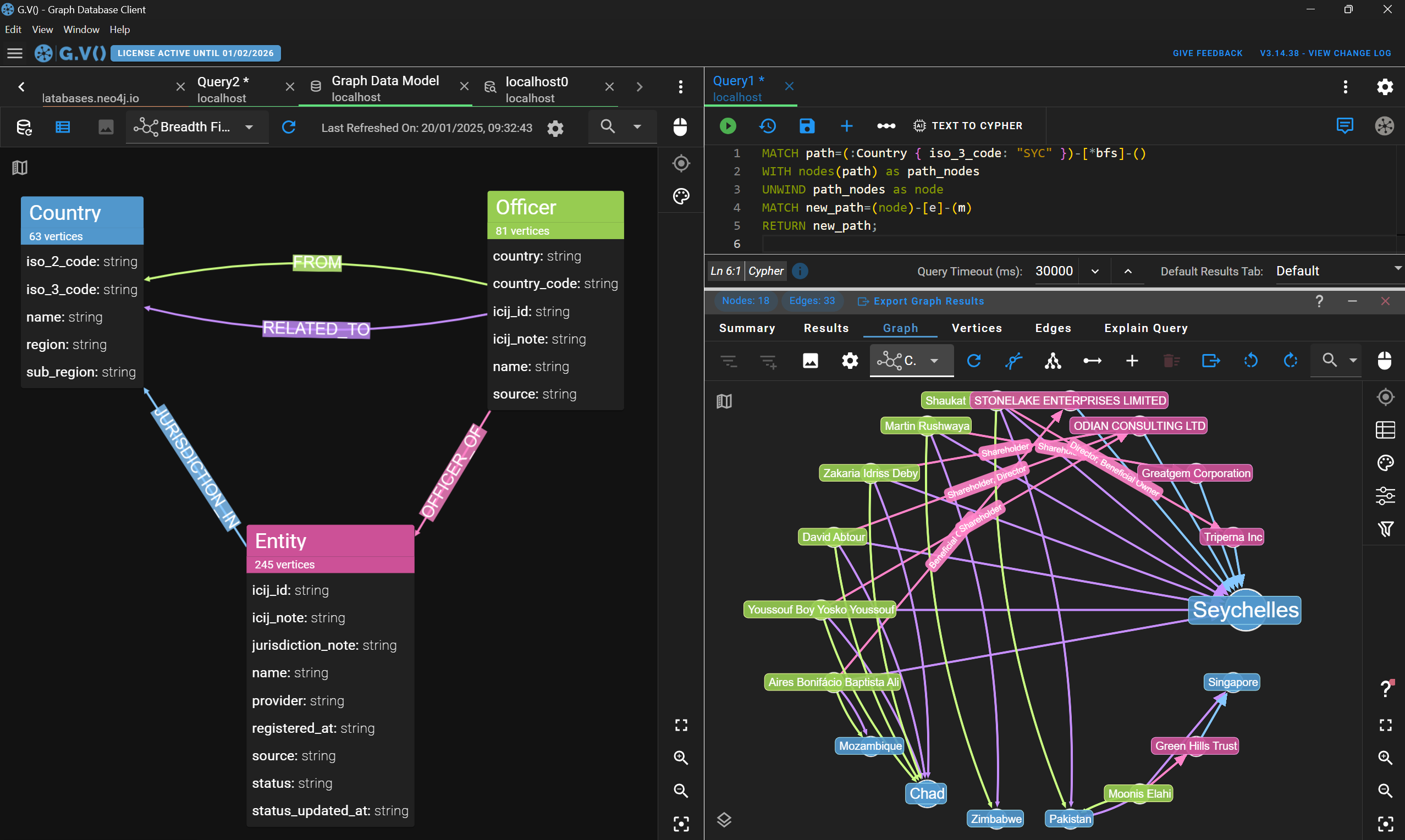
Using the respective schema APIs of Neo4j, Memgraph and Neptune Analytics, our software can retrieve and display your graph data schema in seconds. The data schema display is an essential tool to track and manage the structure of your data, as well as share it internally.
 Visualizing a sample ICIJ Pandora Papers graph data schema on G.V()
Visualizing a sample ICIJ Pandora Papers graph data schema on G.V()
Improved Graph Styles Generation
We’ve reworked our default graph styles generation to use a more vibrant and discernible color palette. This update also makes vertices easier to distinguish from edges on large graphs.
Labels now come with a background by default to improve readability. Overall this gives graph visualizations a more distinct visual identity whilst carrying visual information more accurately. As always a picture speaks a thousand words, and the comparison between old and new below should give you a perfect idea of the positive impact of this change:
")
Large graph display in previous versions of G.V()
")
The same graph display in the new version of G.V()
We’ve followed a similar approach in the handling of label displays to ensure they contrast better with the graph elements by default. Note that you can configure stylesheets manually to achieve the results displayed above, but ideally this should all happen automatically, which is what we’ve done here!
")
Default labels display in previous versions of G.V()
")
Defaults labels display in latest version of G.V()
Query Editor Improvements
We’ve made performance improvements to our query editor, allowing it to generate code suggestions faster and without interrupts to the main UI thread. Detection of multiple Gremlin queries in a single editor is now also more efficient and accurate.
The Summary results view has been visually improved to convery the same information more succintly, with the ability to hide/show the various types of outputs presented from the query. When using Gremlin as the query language, you’ll be shown the JSON Output by default, with the Console Output available to view as well.
When using Cypher as the query language, you’ll be shown the JSON Output by default with the option to see the Result Summary as returned by the Bolt protocol, where available. This includes useful Bolt Summary details such as Database Impact Statistics or Database/Server info.

Displaying tabs side by side
Conclusion
For the first time ever, G.V() can be used simulatenously across most major labeled property graph databases such as Neo4j, Amazon Neptune and Azure Cosmos DB. This release sets out the initial roster of Cypher-enabled graph databases we’re bringing support to – and there will be many more in the future.
If there’s a specific graph database you’d like to use with G.V() that’s not made it to our list yet, drop us a line at support@gdotv.com.
We’re actively working with graph database vendors to bring these new integrations to life. As always, stay tuned!


![Evaluating Codebase-Oriented RAG through Knowledge Graph Analysis [Part 2]](https://gdotv.com/wp-content/uploads/2026/03/knowledge-graph-analysis-codebase-oriented-rag-part-2.jpg "Evaluating Codebase-Oriented RAG through Knowledge Graph Analysis [Part 2]")