The Weekly Edge: Gdotv on Apache TinkerPop Wide Stream, Aerospike Goes Open Source, Information Retrieval Benchmarks & more

Happy Thursday!
We’re back at it, once again keeping you updated on the latest graph news. This week we’re getting philosophical about graph construction, with several items getting deep, gritty and technical about what it makes to be a graph. But if that sounds daunting, don’t worry, Amir’s here to talk you through much of it with a laid-back video discussion, and we have some lighter items for dessert.
Headlines this week:
- Text on my edges? It’s more likely than you think. Gdotv’s Amir talks with Apache TinkerPop Wide about the TEG-DB benchmark.
- 3, 2, 1, liftoff! Aerospike’s jettisoned its protective shell as Aerospike Graph Service has gone open source.
- When in Rome, build a graph: A historical themed dataset aims to serve as a new integrated benchmark for information retrieval.
- Data visualization, your way. Neo4j Enterprise Studio brings querying, no-code exploration and dashboarding to self-hosted graphs.
- I’m a doctor, not an ontologist! Rosetta statements promise to simplify RDF contruction and leave ontologiest to the ontology engineers.
If you’re new here, the Weekly Edge is your weekly tl;dr of graph technology news curated by the team at gdotv, giving you all the reads, repos, vids, and walkthroughs worth exploring from the past seven-ish days (or so).
/* * It’s time to level up your graph game: * Query, explore, edit, and visualize your connected data with the gdotv graph IDE * Try out the free dev tier or upgrade to a 1-month, no-fuss free trial. */
[Watch]: Gdotv’s Amir Speaks with Apache TinkerPop

This one is a gdotv special, as my colleague Amir Hosseini recently appeared on the Apache TinkerPop Wide Stream to discuss his recent deep-dive into the TEG benchmark.
If you didn’t catch Amir’s series, here’s a recap: Textual-Edge Graphs (TEGs) are basically knowledge graphs with natural language text on both the nodes and edges. Simple, right? Sort of. Easy to imagine them, hard to build them in a way that’s structured or useful.
The TEG benchmark is an attempt to illustrate what useful TEGs might actually look like in practice. The dataset spans a few different domains, like social media and book reviews. Amir’s deep dive reviewed the TEG-DB in four main parts:
In the first half, Amir gives a general guide to how you might wrangle the TEG-DB benchmark into a queryable format via some CSV files and AWS Neptune. Once you’ve got set up, you’re ready to take a close look at the benchmark with gdotv and start asking real questions about its structure: What do these “test-enriched” edges actually look like, and do they carry valuable information?
These are the critical questions that will determine the future for TEGs, so the second half focuses entirely on Amir’s investigation and conclusions regarding this benchmark. We’re not going to give spoilers here, but given his PhD was on reference quality in Wikidata, you can expect to get an expert’s opinion. Eagle-eyed viewers will spot he even name-checked two datasets we’ve discussed previously as future candidates: the European Railways Agency Knowledge Graph and the transition metal tmQM-RDF dataset, both of which were discussed in the Weekly Edge from two weeks ago.
[News]: Aerospike Graph Service is Now Open Source

The Aerospike Graph Service (AGS) repository has now gone open source.
If you’re not familiar with Aerospike, it’s a distributed graph database engine built for low latency and scale. Using the Apache TinkerPop framework for communication, Aerospike translates Gremlin traversals into high-efficiency Aerospike-specific operations in a way that leverages a multi-modal base (i.e. not strictly graph-native) to deliver extremely high performance across even billions of elements.
Aerospike Graph has been in Cloud Preview for a while, and is among Aerospike’s primary advertised services, alongside Aerospike Cloud and Aerospike Voyager, so the decision to open up this proprietary service is significant. It’s not entirely unprecedented for the company, though, a base distribution of the Aerospike database itself is already available open source via the Community Edition.
If you do decide to spin up anything with AGS or any other Aerospike service, remember that you can use your gdotv client to investigate the graph! Read more about that here.
[Dataset]: A Potential New Integrated Benchmark for Information Retrieval
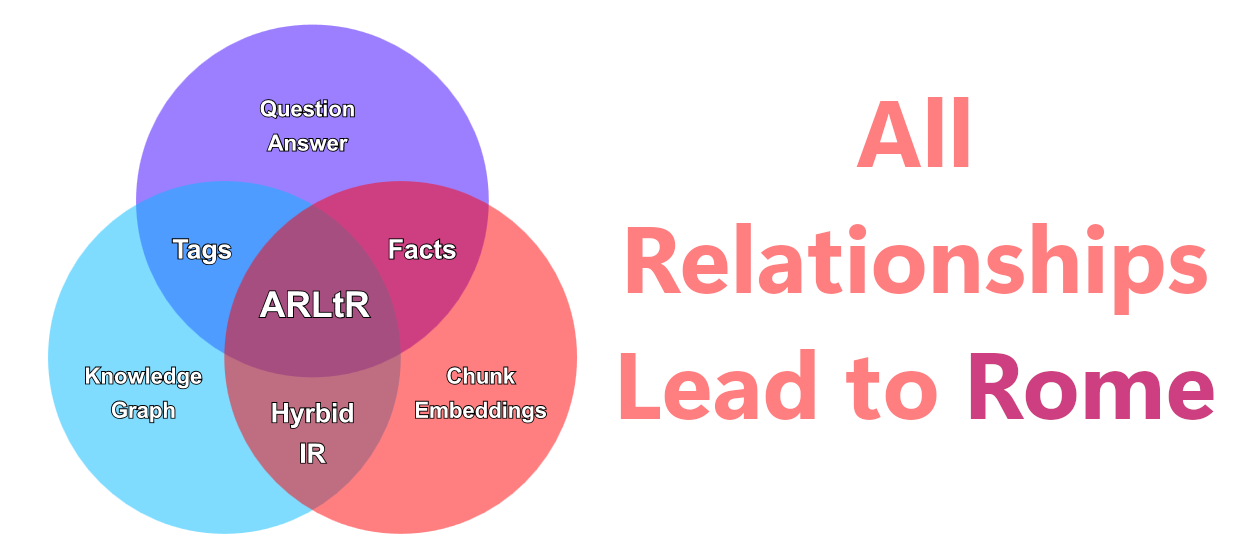
All Relations Lead to Rome (ARLtR), from Matthijs Jansen op de Haar (Twente), Tobias Stähle (ETH Zürich) and Lorenzo Gatti (Twente), is a new release aiming to serve as a new benchmark for information retrieval.
The researchers claim that existing datasets exist largely in two exclusive types: (1) vector-based retrieval over unstructured text or (2) reasoning over a knowledge graph. They argue that there are few existing benchmarks that combine both in one place.
Their work, ARLtR, aims to be just such a unified dataset. It offers everything in one: knowledge graph, embeddings, and question and answer pairs explicitly grounded in the entities, relations, and supporting text sourced from a central corpus of documents. The name isn’t just metaphorical, the benchmark (comprising 19,000 entities, 16,000 chunks, and 8,400 question/answer pairs) is literally a collection of data concerning the Roman Empire.
The idea is that coupling the symbolic graph with the dense vectors can give a single coherent resource for evaluating and developing hybrid retrieval systems and “semantic steering” approaches. This is a dataset that might be useful to those building GraphRAG-style systems, and it’s on Hugging Face if you want to check it out.
[News]: Neo4j Reveal Enterprise Studio for Self-Managed Graphs
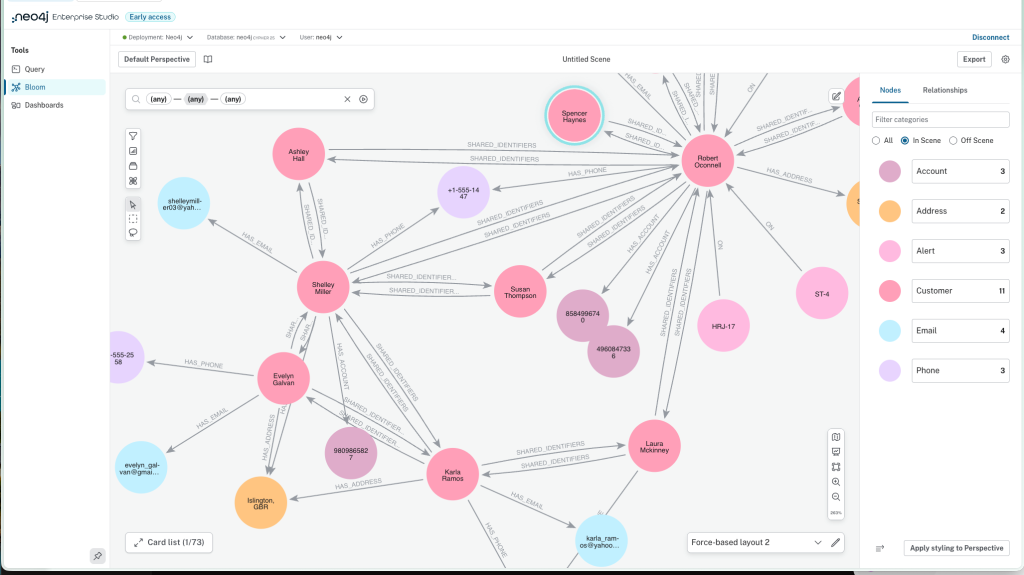
Neo4j has been a frequent appearance in the last few issues of the Weekly Edge. Previously we mentioned that Neo4j had recently acquired GraphAware, and released Virtual Graphs, a new graph-on-relational functionality. This week, yet another Neo4j update is the release of Neo4j Enterprise Studio.
What’s Enterprise Studio? Essentially, it’s a workbench for self-hosted graphs. This is targeted at users for whom strict control is a must, and cloud-based tooling simply won’t work. The workbench comes with three primary components: Query, Bloom, and Dashboards. Query is, well, querying your data with Cypher. Bloom is a no-code exploration functionality. Dashboards construct interactive visualizations of your data.
As they point out in a recent LinkedIn announcement, these functionalities already exist in Neo4j AuraDB, but now they’re available for self-managed environments as well.
It’s obligatory for us to mention that you can also leverage a whole host of querying, no-code, and dashboarding functionality with Neo4j and Neo4j AuraDB environments (along with just about every other graph database on the market) using gdotv, read more about that here.
[Paper]: Rosetta Statements Bridge the Communication Gap to RDF
The principles of “FAIR” data is that said data should be Findable, Accessible, Interoperable, andReusable. But what challenges are there in implementing FAIR graphs, and (specifically!) FAIR RDF? A recent paper “Rosetta Statements: simplifying FAIR knowledge graph construction with a user-centred approach” from Lars Vogt and other researchers in Germany aims to tackle this problem.
Lars’s own framing on LinkedIn outlines the motivation: building FAIR knowledge graphs is hard, too hard, and this paper is for everyone who’s ever watched a domain expert give up twenty minutes into RDF and SPARQL. They point out that modelling even a single statement the “proper” ontological way is a specialist skill. Even if you do it right, the RDF knot on the other side is rarely fun for humans to read.
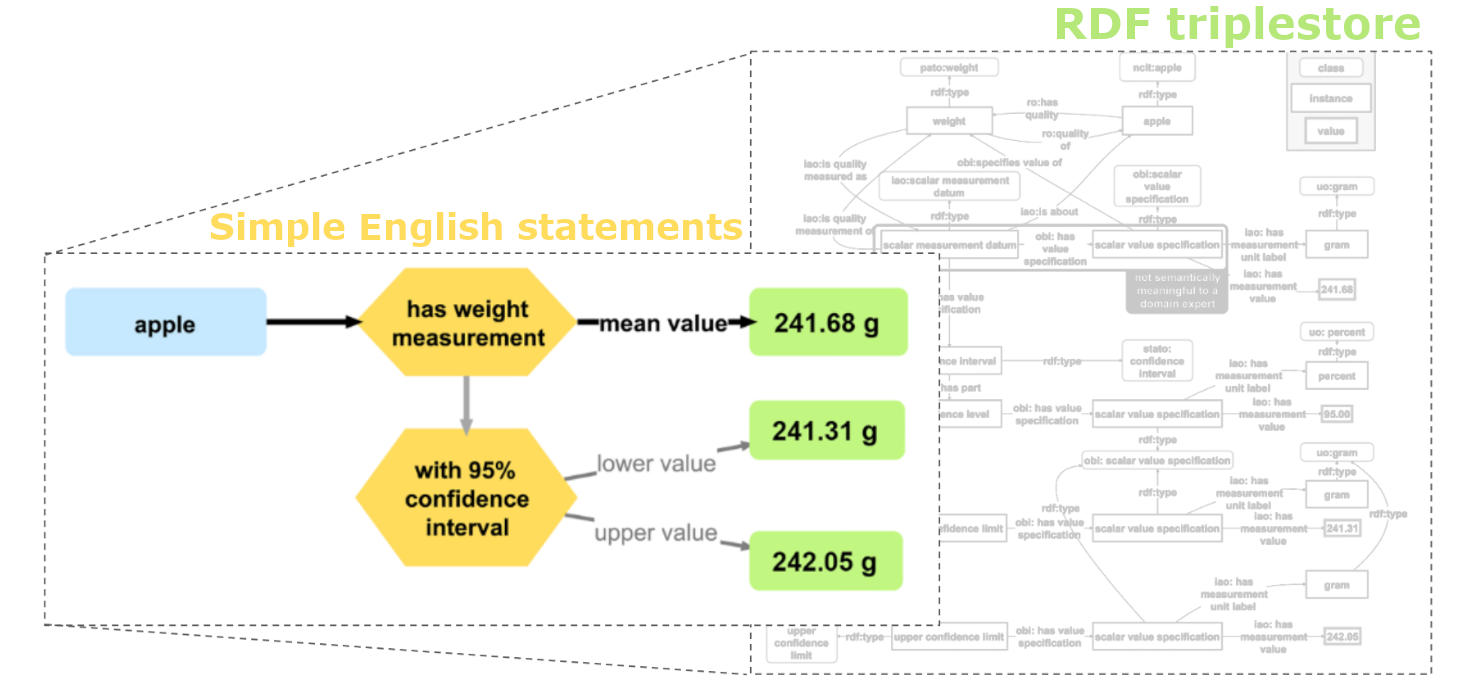
Their framework, Rosetta Statements, aims to lower the barrier to entry. It’s framework for people to interface with knowledge graphs through simple English sentences (and no, not just by trusting an LLM to take the wheel). Of course, English language statements just aren’t bound by the neat three-entity structure of RDF triples and you need a slightly more sophisticated conversion scheme to get the translation right. That’s what they claim Rosetta Statements are the foundation for: an RDF-native metamodel for “n-ary statements.” (The name sounds intimidating, but an n-ary statement is just an English sentence with multiple objects, such as “Sarah met Bob on the 4th of July 2021 in New York City”.) In essence, it’s method of encoding of some general English syntax principles into RDF, or a sort of “RDF reification for natural language” if you prefer.
There’s a light version and a full version, and it’s already running in the Open Research Knowledge Graph. The idea is that researchers will build their initial graphs using Rosetta Statements and generic Wikidata terms, on top of which semantic search and ontological reasoning can be introduced. It leans on the CLEAR principle and “cognitive interoperability,”, and since the ORKG is RDF/SPARQL, exactly the sort of thing you can point gdotv at.
/*
*/
P.S. Looking for more knowledge graphs and love mathematics? Check out TheoremGraph, a KG for mathematical theorems.
P.P.S. In this week’s Graph Pulse, we checked in with Hugues Seureau at GenHax to discuss knowledge graph integration and the role of learning in the post-LLM world.
P.P.P.S. Got an item to nominate for the next edition of the Weekly Edge? Hit me up at weeklyedge@gdotv.com or hit reply! ✍🏽

