SHACL in gdotv: Unifying Your RDF Data Model & Validation

RDF data graphs are inherently schema-less. In other words, reading, inserting, or curating data does not technically require a predefined schema. This flexibility is one of RDF’s core strengths.
However, in many real-world scenarios, having a schema is helpful or even essential. For example, when ensuring data quality and consistency in an enterprise knowledge graph or when enabling data exchange between multiple systems, a shared structural contract is required.
There are several approaches to defining schemas over RDF (Resource Description Framework) graphs. The W3C standard for validating RDF data is SHACL (Shapes Constraint Language). At a high level, a SHACL schema consists of a collection of NodeShapes, each describing and constraining a portion of the graph. The core mechanism behind this description is a set of constraints. These constraints typically define the expected class of nodes, cardinalities of relationships, datatypes of literal values, incoming and outgoing edges, and even more complex structural conditions on individual nodes or subgraphs.
SHACL is excellent for validation. It formally specifies constraints that RDF data must satisfy. But, although SHACL is designed as a validation language, its constraints inherently express a data model. When a shape specifies that instances of a class must have exactly one value for a property, or must receive at least two incoming relationships of a certain type, it is implicitly defining the intended structure of the domain, even if the original intention was only to check existing data.

Understanding a large shape graph, however, often requires directly reading RDF – which is neither intuitive nor efficient for many users. While there are tools that generate UML diagrams from SHACL schemas, these approaches are typically limited and single-purpose. Moreover, UML diagrams tend to be rigid, table-oriented, and visually uninspiring. They also rarely integrate seamlessly with other semantic layers that may coexist in the same graph, such as OWL or RDFS.
As a result, although SHACL effectively encodes modeling knowledge, that knowledge often remains expressed in a form that is optimized for machines rather than for human understanding.
Seamless SHACL Integration in gdotv
With the newly introduced capability in gdotv, SHACL is no longer treated as an isolated validation layer. Instead, it becomes a fully integrated component of the overall data modeling pipeline.
gdotv now provides seamless integration between SHACL-derived structures and previously supported extraction layers: OWL, RDFS, and instance-based schema discovery. Rather than visualizing these sources independently, the gdotv platform consolidates them into a unified data model of the graph.
SHACL definitions are automatically read from the data source. While all declared constraints are preserved and stored (to support future validation workflows), gdotv simultaneously extracts the implicit data model encoded within the shapes. In other words, the system does not merely capture validation rules, it derives the structural intent behind them.
As a result, SHACL assumes a broader role within the modeling process. In the following section, we will walk through a concrete use case and demonstrate how a data model is systematically derived from a SHACL shape schema.
Running Example: The Film Club Knowledge Graph (FCKG)
As the running use case for this blog post, we’ll adopt the Film Club Knowledge Graph (FCKG).
FCKG is an RDF knowledge graph that models award nominations across six major film award systems, defined with an ontology expressed in SHACL shapes. The FC knowledge graph dataset includes a SHACL-based schema (movieontology.ttl) that encodes classes such as Film, Person, Nomination, AwardSystem, and AwardCeremony, along with the key structural constraints that govern their relationships.
This schema, together with instance data covering tens of thousands of films, people, and nominations, provides a rich, real-world example of how a SHACL shape graph encodes implicit data modeling intent. We use this example to illustrate how gdotv reads SHACL shapes from the source, and automatically extracts an integrated data model that unifies the ontology with OWL/RDFS and instance-based schema insights.
A Look into a SHACL-Only Schema
In this first scenario, we load only the SHACL schema into a local Apache Jena Fuseki triplestore, without any instance data. The graph therefore consists purely of SHACL shapes.
In this setup, the extracted data model is derived entirely from NodeShape definitions and their associated property constraints. Classes, relationships, cardinalities, and datatypes are inferred solely from the structural intent encoded in SHACL. At the same time, the original constraints are preserved in the background and will be leveraged in future validation workflows.
This setup allows us to observe how much modeling knowledge is already embedded within the validation layer itself even in the absence of additional ontological annotations such as OWL or RDFS, and without any instance data present.
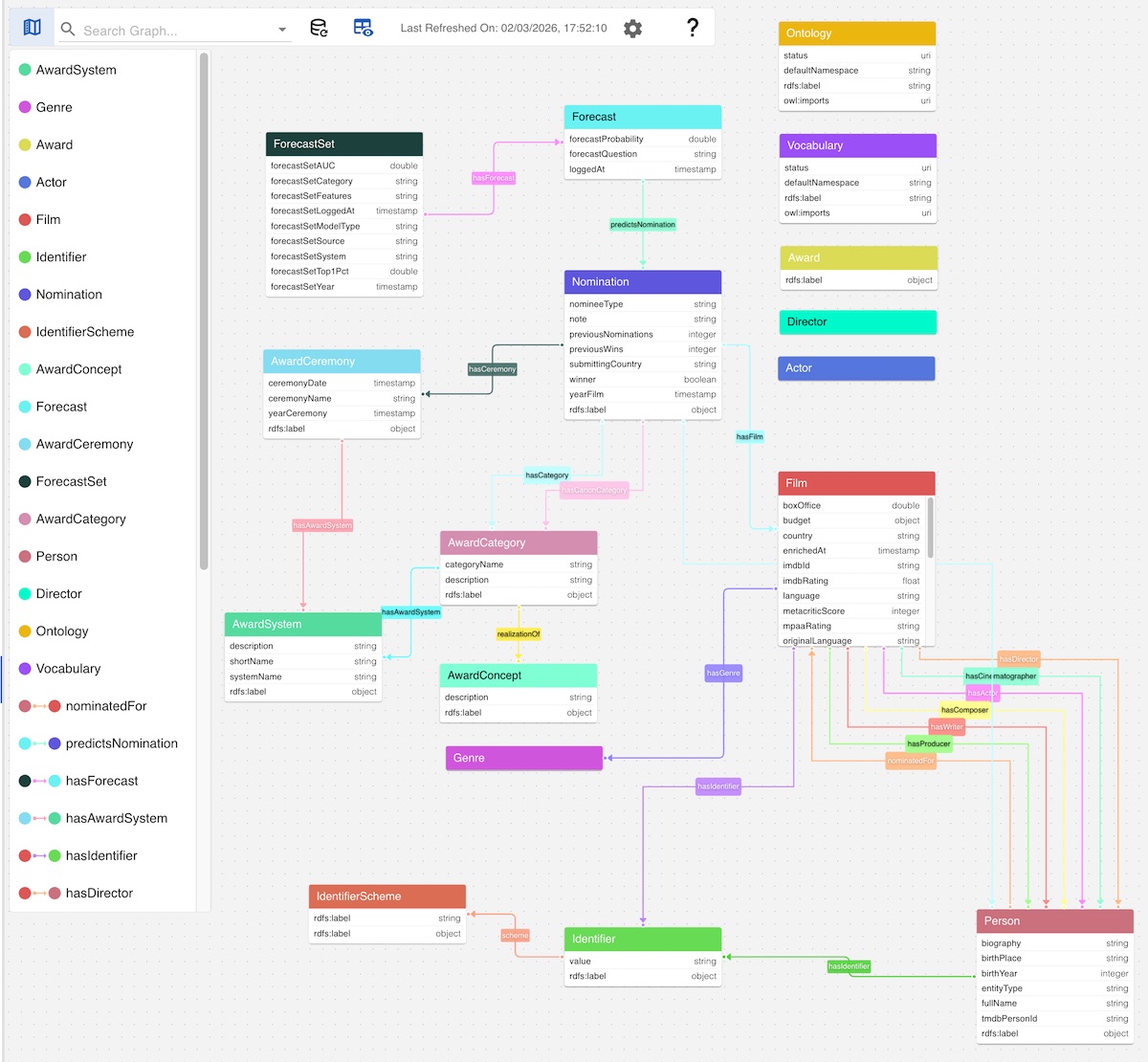
One of the most immediate and intuitive observations we can make at a glance is that this schema is strongly centered around the award system and nomination structure. There is no direct relationship between the Award class and the Person class through a property such as wonAward or similar.
Furthermore, although the schema defines classes such as Actor and Director as subclasses of Person, and while it would arguably be more semantically precise for relationships like hasActor to point from Film to Actor rather than to the more general Person class, these specialized classes remain effectively isolated at the schema level. In other words, they are defined hierarchically but are not structurally integrated into the core relationship graph, leaving them somewhat orphaned within the data schema.
A Look into an Instance-Based-Only Schema
In the second scenario, we load only instance data into Apache Jena, without the SHACL schema. Below, you can see a simple query and its results as visualized in gdotv.
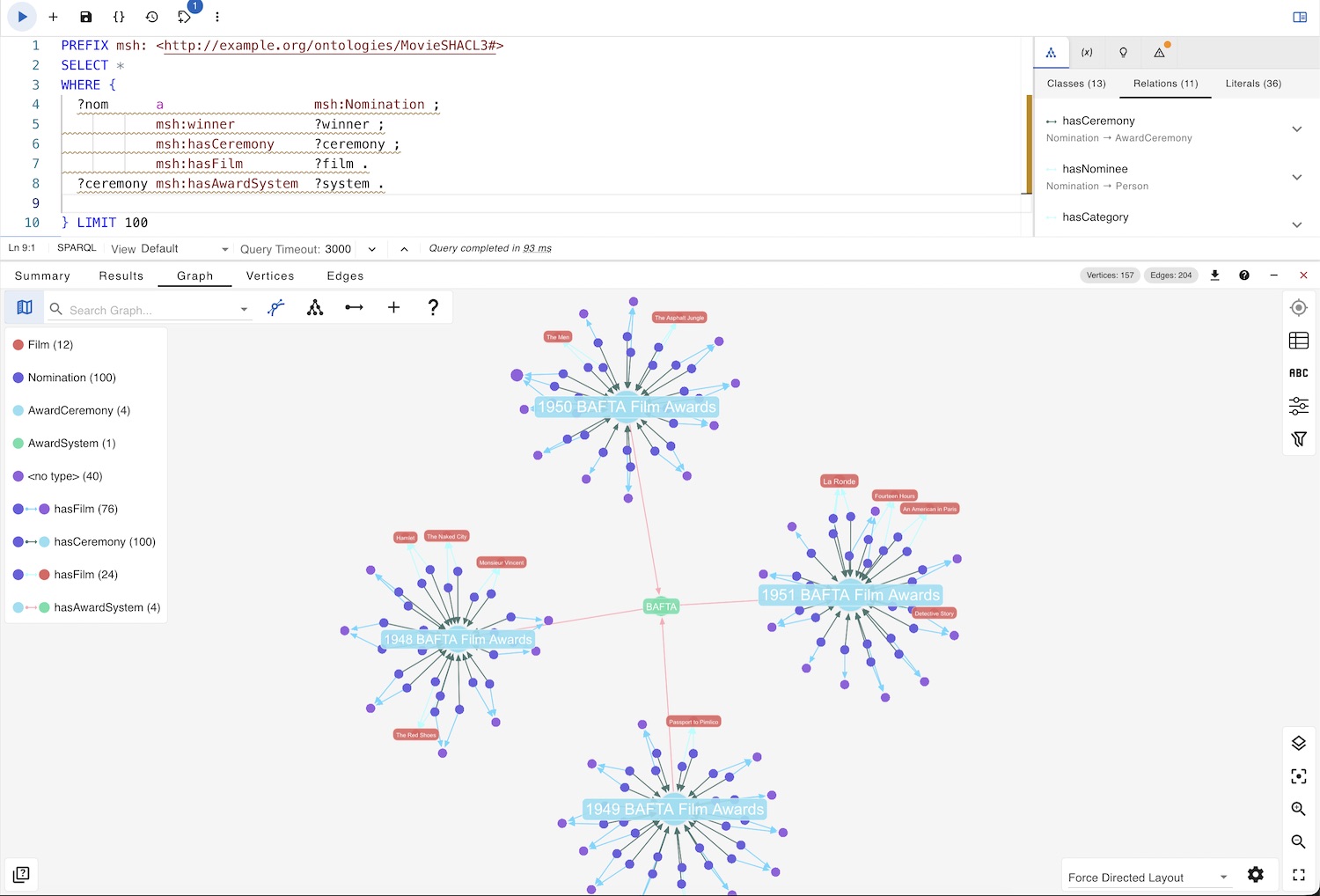
Here, the data model is derived purely from empirical graph structure.
Classes are inferred from rdf:type assertions, and properties and literals emerge from observed predicates based on existing data patterns. This reflects the data-driven schema discovery approach that gdotv has previously supported. The resulting model represents what exists in the data, rather than what should exist.
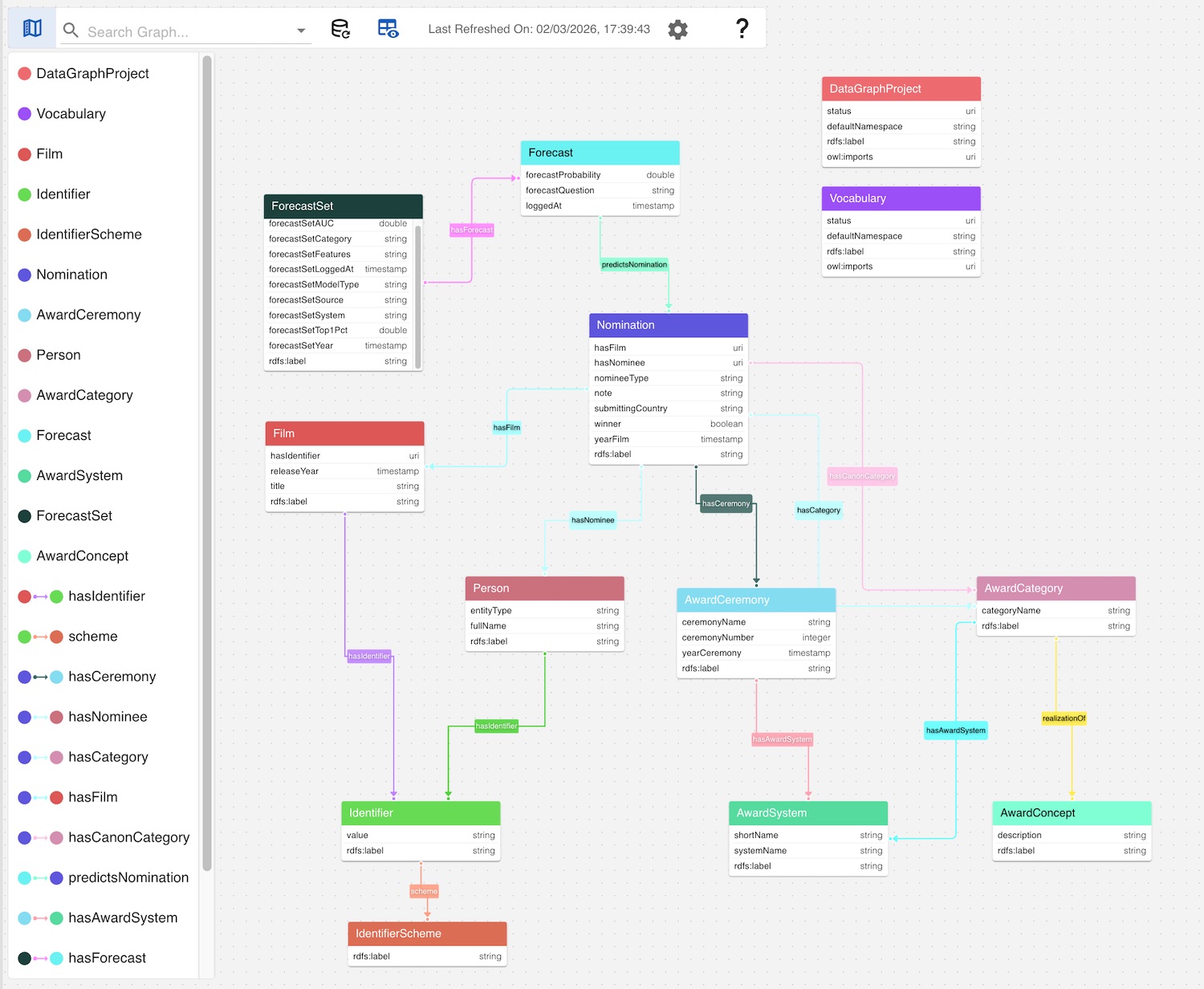
In this purely instance-based data model, we observe that there is virtually no relationship between the Person class and the Movie class, which was one of the richest parts of the schema. The reason for this is simply the lack of corresponding data in the instance layer. The Actor and Director classes also have no instance data at all. Also, many definable literals in the schema are absent from the data samples.
In the instance-based data model, we also encounter a class named DataGraphProject, which does not appear anywhere in the SHACL shape schema. This class is introduced at the data level, as the datasets that are serialized as files films.ttl, oscar_nominations.ttl, and people.ttl, are typed as instances of DataGraphProject.
From an analytical perspective, this is not unusual in practice. Instance data often includes technical, organizational, or provenance-related classes that are not part of the domain-focused validation schema. SHACL shapes typically concentrate on validating core domain entities (e.g., films, persons, nominations), while operational or project-level constructs may exist purely for data management purposes.
However, this example highlights an important point: an instance-driven model can surface structural elements that are invisible in the validation schema, reinforcing the value of integrating both perspectives into a unified data model.
A Look into the Integrated Data Schema
In the final scenario, we load both the SHACL schema and the instance data into the same RDF triplestore.
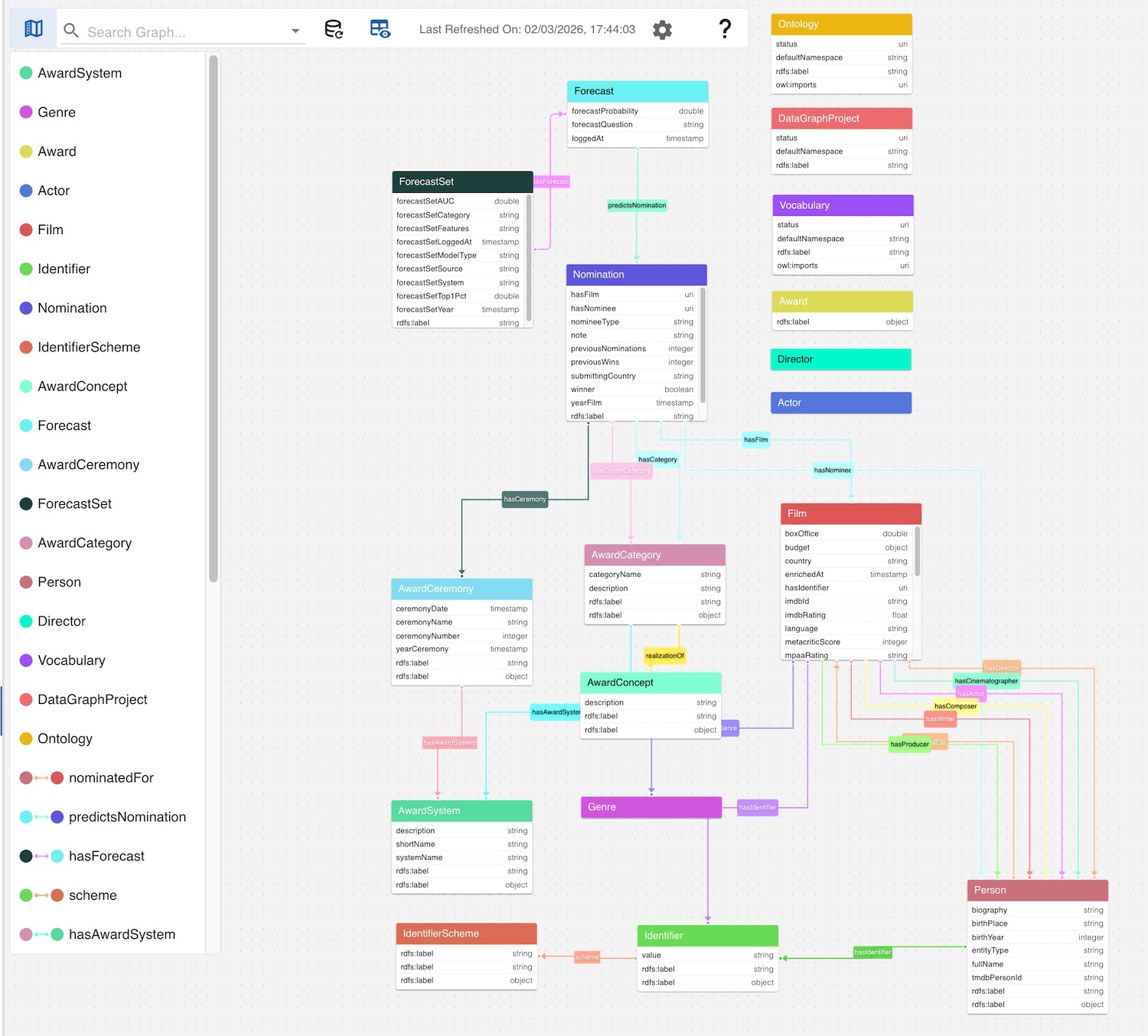
Here, gdotv integrates constraint-based knowledge from SHACL with structure observed in the instance graph. The resulting model combines prescriptive definitions (from shapes) with empirical evidence (from data), producing a richer and more complete representation of the domain.
This integrated view demonstrates the real power of the approach: validation rules, ontology definitions, and instance-level data converge into a unified, explorable, and operational data model.
How gdotv Derives a Data Model from SHACL Shapes
Let us now look more closely at how gdotv constructs a data model from a SHACL schema.
The first question is how a SHACL shape can be associated with classes in the data model. Typically, SHACL shapes define their validation scope explicitly through a target declaration. In other cases, such as in the FCKG schema, shapes are defined more generically, leaving the specification of targets to the validation engine at runtime. During validation, the evaluator decides which class or node should be assessed against which shape.
In the first and most common case, sh:targetClass is used to declare that a specific RDF class is the validation target. This means that all instances of that class must satisfy the constraints defined in the shape. For example:
MovieSHACL3:Person a sh:NodeShape ; sh:targetClass MovieSHACL3:Person .
From this declaration, we can directly infer that the data model must contain a class named Person.
If a shape does not declare any explicit target, gdotv interprets the identifier of the sh:NodeShape itself as representing a class in the data model, which is the case for the shapes defined in the FCKG database schema.
Extracting Structure from Property Constraints
The next step involves analyzing the sh:property constraints defined for each shape. These property shapes contain crucial structural information.
Consider the following example from FCKG:
MovieSHACL3:Person a sh:NodeShape ; sh:property MovieSHACL3:Person-nominatedFilms . MovieSHACL3:Person-nominatedFilms a sh:PropertyShape ; sh:nodeKind sh:IRI ; sh:class MovieSHACL3:Film ; sh:name "nominatedFilms" ; sh:path MovieSHACL3:nominatedFor .
This constraint tells us that the Person class is connected via the property nominatedFor to the Film class. From a data modeling perspective, this becomes a relationship between Person and Film in the derived data model.
Now consider a datatype constraint:
MovieSHACL3:Person sh:property MovieSHACL3:Person-fullName . MovieSHACL3:Person-fullName a sh:PropertyShape ; sh:name "fullName" ; sh:path MovieSHACL3:fullName ; sh:maxCount 1 ; sh:datatype xsd:string ; sh:minCount 1 .
This indicates that the Person class has a literal attribute fullName, with cardinality exactly one (minCount 1, maxCount 1) and datatype xsd:string. In the extracted data model, this becomes a mandatory single-valued attribute of type string.
SHACL also allows inverse paths, for example:
MovieSHACL3:Person-hasNomination a sh:PropertyShape ; sh:nodeKind sh:IRI ; sh:class MovieSHACL3:Nomination ; sh:name "nominations" ; sh:path [ sh:inversePath MovieSHACL3:hasNominee ] .
This expresses that a Person may be the object of the property hasNominee, effectively defining an incoming relationship from Nomination. However, to avoid redundancy and potential conflicts with already serialized forward relations, gdotv does not add inverse paths separately into the derived data model.
Other Target Types
It is also important to consider other SHACL target mechanisms, particularly sh:targetSubjectsOf and sh:targetObjectsOf.
In both cases, what is being targeted is not a class, but a specific property in the graph. So, sh:targetSubjectsOf ex:someProperty means that all subjects participating in that property must satisfy the shape and sh:targetObjectsOf ex:someProperty means that all objects of that property are subject to validation.
In these scenarios, gdotv records the defined constraints for all affected edges or literals and preserves them for future validation processes. At the same time, the structural implications of these constraints are incorporated into the unified data model.
Conclusion
SHACL alone already carries a surprising amount of modeling knowledge. Even without instance data, it defines structure, intent, and constraints that clearly describe the domain. Instance data alone, on the other hand, reflects reality as it happens, sometimes incomplete, sometimes noisy, sometimes richer in unexpected ways.
But the real insight emerges when both perspectives are combined.
By integrating SHACL, OWL/RDFS, and instance-driven discovery into a single unified view, gdotv makes the implicit explicit. Structural intent becomes visible, and therefore, data patterns and schema definitions can be compared, aligned, and analyzed together.
The result is then beyond a data visualization-only approach and provides a living data model which is explorable, operational, and usable as a reference point for validation, analysis, and future extensions.
Curious to try it out for yourself? Give gdotv a test drive and discover what’s possible with the world’s first graph technology IDE.


