The Weekly Edge: Knowledge Graphs Keep Heating Up, a LadybugDB Walkthrough, & Data Viz Won’t Save You (by Itself)
")
To borrow from the great sage-poet, Mugatu: “It’s those knowledge graphs, they’re so hot right now.” 🔥
This edition of the Weekly Edge is a case-in-point for why knowledge graphs are having their moment: a hands-on pipeline tutorial, a full GraphRAG walkthrough, and a knowledge engineering essay that spits fire. It’s all about those KGs.
Here are this week’s headlines:
- From docs to graph in minutes: How to pair Lettria Perseus with AWS Neptune to build knowledge graphs from all your unstructured text
- A fork worth following: LadybugDB and Icebug power on where Kuzu left off
- GraphRAG from scratch: Watch and learn as Thu Vu walks you through building a knowledge graph of an AI copyright use case
- The moat is moving: Mark Pederson argues that knowledge engineering has to go graph or get left behind
- Blue Steel meets technical debt: Pretty codebase visualization tools can totes reveal your architectural mess – they just won’t fix it
If you’re new here, the Weekly Edge is your weekly tl;dr of graph technology news curated by the team at gdotv, giving you all the reads, repos, vids, and demos worth exploring from the past week (or so).
// It’s time to level up your graph game: Query, explore, edit, and visualize your connected data with the gdotv graph IDE. Try it out with a 1-month, no-fuss free trial.
Let’s dive in.
[Walkthrough:] Building Knowledge Graphs from Unstructured Text with Lettria Perseus + AWS Neptune
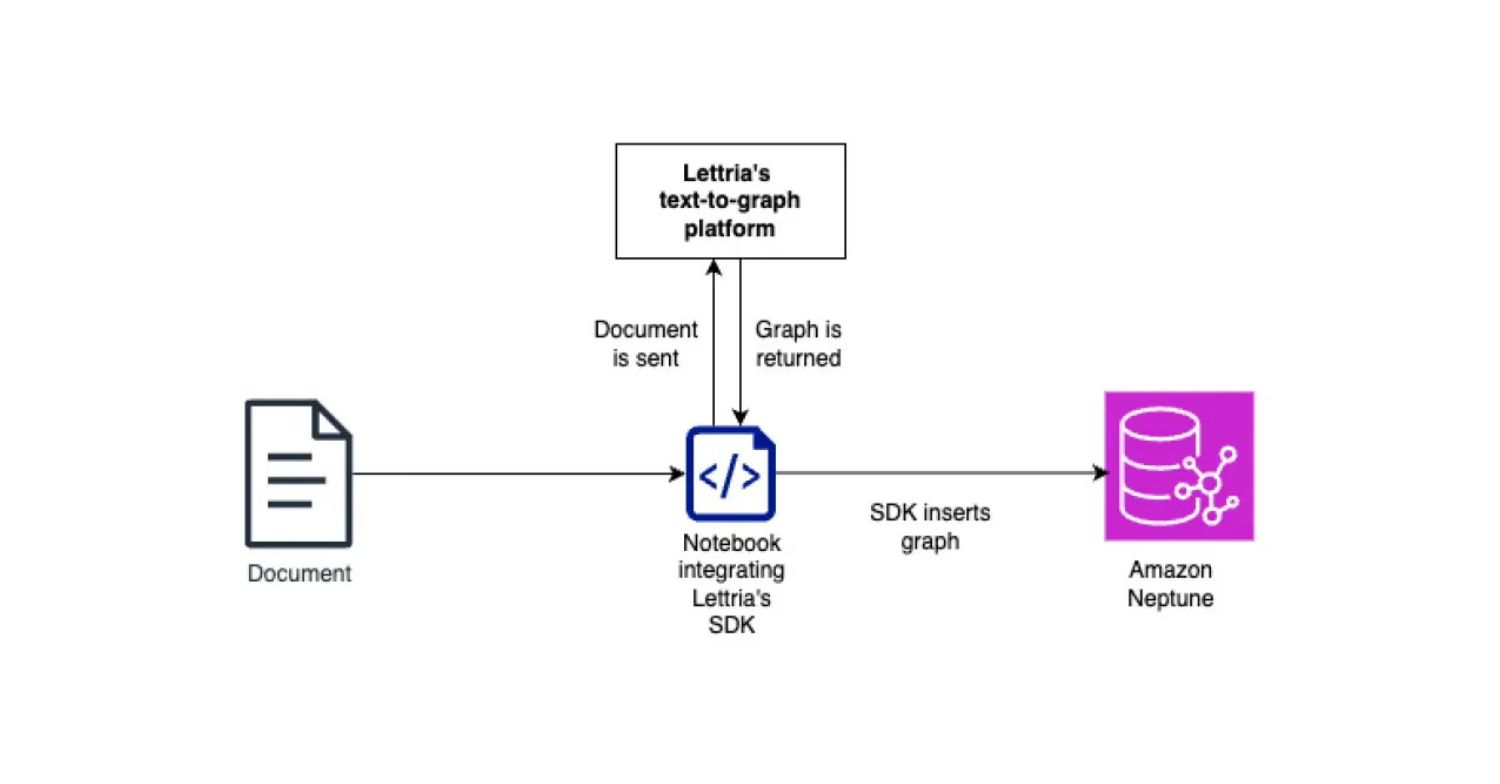
Your org has documents, lots of them: technical docs, research papers, internal reports – all stuffed with valuable relationships between entities that you can’t query because nobody has the time or expertise to extract them into a graph. Until now, hopefully.
In this week’s walkthrough, Vivien de Saint Pern shows you how to pair Lettria’s Perseus SDK with Amazon Neptune to automatically transform unstructured documents into queryable knowledge graphs – no manual annotation, no custom extraction logic required. Perseus handles the NLP heavy lifting (entity identification, relationship extraction, Cypher query generation), and Neptune stores and serves the result.
In a test with a 7KB AWS Neptune documentation file, the pipeline extracted 18 entity nodes and 24 relationship edges – from markdown to knowledge graph – in mere minutes. The full walkthrough from the AWS Builder Center includes CloudFormation templates, a Jupyter notebook, and sample code to get you started.
[Read/Demo:] From Kuzu to Ladybug: The Embedded Graph Database Powers Onward
Those of you who mourned the archiving of Kuzu back in October 2025 – we did too, for the record – will be glad to know the embedded graph database didn’t just lie down and die. Former Kuzu team member and graph sage Prashanth Rao has written a fantastic deep-dive on what comes next.
This week’s read walks you through building a graph algorithm workflow using LadybugDB – the Kuzu fork maintained by Arun Sharma and team – and Icebug, a columnar-optimized fork of the NetworKit graph analytics library.
The dataset is a Nobel laureate mentorship network tracing who mentored whom across a century of prize-winning science. The graph algorithms surface some genuinely surprising bridges: J.J. Thomson mentored 11 Nobel laureates, and the Thomson-Bohr-Rabi chain spans from early 20th-century British physics all the way to the Manhattan Project era. Worth a read.
//
[Watch:] GraphRAG Explained: Building a Smarter AI System from Scratch
AI copyright is – to understate it – a mess, but data science legend Thu Vu tackled that mess in the most interesting way possible. In this week’s watch, Thu Vu builds a full GraphRAG pipeline from scratch using AI copyright as the real-world test case. It’s a topic so sprawling, so scattered across court filings, news articles, and policy docs, that no standard RAG system could reliably reason across it.
This walkthrough covers the full end-to-end pipeline: scraping live Google News results with SerpAPI, extracting entities and relationships using an LLM with a custom ontology, running Leiden community detection to cluster related entities, and visualizing the resulting knowledge graph. The final GraphRAG system can answer natural-language questions with the kind of cross-document reasoning that standard vector RAG simply can’t handle.
If you’ve been curious about how GraphRAG actually works under the hood, this is one of the clearest walkthroughs out there. Subscribe to Thu Vu’s channel for more.
[Short Read:] The Knowledge Engineering Decade

The (tired) narrative that LLMs ate data structure is already aging badly, writes Mark Pederson in this sharp Substack post. His argument: your moat isn’t the model – it’s the typed, temporal, proprietary knowledge graph underneath it.
Models are commoditizing faster than anyone expected, but graphs compound. Knowledge engineering needs to keep up as a result.
An agent without a reliable knowledge substrate, he writes, is “a confident hallucinator on a longer leash.” But the clutch – “The graph is the product. Everything else is a detail.” – is the kind of line you’ll want to steal for your next board deck.
[ICYMI:] Pretty Galaxies Won’t Fix Your Monolith: The Brutal Truth about Code Visualization Tools
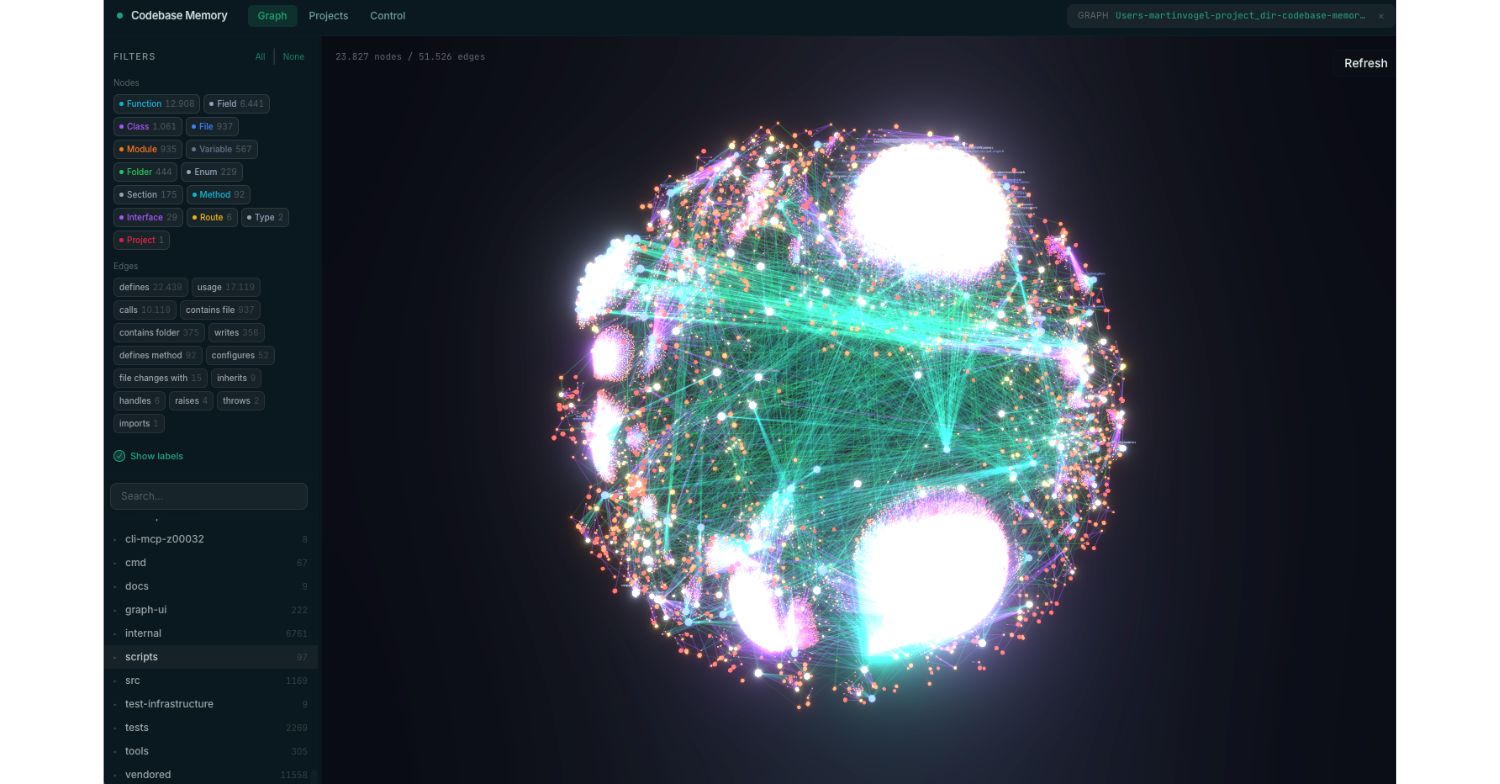
You’ve seen the demo a hundred times: render your massive codebase as a stunning graph visualization, watch dependencies light up like constellations, and suddenly understand everything.
Andrii Fedorenko’s article from earlier this month offers a refreshingly blunt review of codebase visualization tools like GitGalaxy, Codebase Memory MCP, and Understand Anything. He argues that these tools are excellent at revealing complexity but useless at fixing it.
In other words, data visualization is only the first step: helping you admit where you have a problem. As Andrii puts it: “Lenses don’t fix broken eyes. They just help you see the damage more clearly.” Harsh, but true. 😬
P.S. The Knowledge Graph Conference is less than 2 weeks away! Here is my highly personal take on the don’t-miss sessions at this year’s conference. Hit me up if you’ll be there! 👋
P.P.S. And be sure to join the KGC Ask Me Anything (AMA) happening today (23 April) with semantic web legends James Hendler and Deborah McGuinness and hosted by Larry Swanson. 🕸️
P.P.P.S. Got an item to nominate for the next edition of the Weekly Edge? Hit me up at weeklyedge@gdotv.com. ✍🏽


