A Landscape of the Emerging Graph on Relational Category

In the last 18 months, three cloud hyperscalers, two established database vendors and multiple startups shipped a graph-on-relational engine. This is the clear beginning of a new category in the database industry that challenges the concept of a graph database.
Here is what we’ve seen to date:
| Engine | Architecture | Query language | Status |
|---|---|---|---|
| PuppyGraph | Layered separate engine | Gremlin, Cypher | GA |
| Spanner Graph | In-engine | ISO GQL, GoogleSQL | GA |
| BigQuery Graph | In-engine | ISO GQL | Public preview |
| Oracle Graph (23ai) | In-engine | SQL:2023 SQL/PGQ | GA |
| Prometheux | Layered (ontology engine) | Vadalog (Datalog+/-) | GA |
| Kinetica | In-engine | SQL:2023 SQL/PGQ | GA |
| Ontop | Layered (RDF / OBDA) | SPARQL → SQL | GA |
| Microsoft Fabric Graph | In-engine | ISO GQL | Public preview |
| MemGQL (Memgraph Zero) | Layered separate engine (federated) | ISO GQL → SQL or Cypher | Early stage |
| Postgres 19 SQL/PGQ | In-engine | SQL:2023 SQL/PGQ (via recursive CTEs) | Early stage |
| DuckPGQ | In-engine extension | SQL:2023 SQL/PGQ | Early stage |
| pgGraph | In-engine extension | SQL function API | Early stage |
Join me as I attempt to paint a landscape of this expanding field. What architectural choices are being made? Which trade-offs should you expect against native graph databases?
The view is deliberately balanced. There is no winner being declared, and no thesis that native graph is dying. This is however a clear signal that graph workloads are entering mainstream appeal and accessibility.
What graph on relational actually is
A graph-on-relational engine lets you run graph queries (pattern matching, traversals, path expressions) against SQL tables, without the need to first copying or transforming them into a separate graph store.
So how exactly does it differ?
A native graph database (Neo4j, FalkorDB, LadybugDB, Amazon Neptune, etc) owns its storage engine, indexing and everything else. They are optimised specifically for graph queries and every decision, from architecture up to the algorithmic level is done specifically to serve graph workloads at an optimal level.
First of all, graph-on-relational is not to be confused with multi-modal databases. Azure Cosmos DB, ArcadeDB, SurrealDB, and ArangoDB all store data in multiple physical models inside one engine.
You write graph queries against data the multi-modal engine itself ingested and laid out. A graph-on-relational engine does not own the data. The data lives wherever the relational system put it, and the graph engine either points at it from outside or extends the relational engine from within. In short, graph and relational != graph on relational.
A graph-on-relational engine is not optimal for graph workloads by design. It has to compose with the predefined constraints of relational data systems. In terms of performance, it ultimately pays for the impedance mismatch one way or another.
The key takeaway is this: you can’t have maximum performance and convenience. Graph-on-relation technologies available today bring a new set of options to balance both to your specific use case, scale and performance requirements. There are multiple architectures available that we’ll detail shortly
Inside the category, there is one further fork worth setting up early: a layered separate engine (PuppyGraph, MemGQL, Ontop, Prometheux) sits outside the relational source and translates graph queries down to SQL or column-store scans, while an in-engine implementation (Oracle Graph, Postgres SQL/PGQ, Spanner Graph, BigQuery Graph, Fabric Graph, Kinetica, pgGraph) embeds graph pattern matching into the relational engine itself. This difference is not reflected as a separate category (yet) and I would argue that those systems are the true graph-on-relational, whereas in-engine implementations are more so graph-in-relational. For posterity, let it be known that the term has been coined here first :).
The two fundamental architectures
Today’s offerings split cleanly along one architectural axis.
Layered separate engine. A standalone graph compute engine sits in front of one or more relational sources, translating incoming graph queries (Gremlin, Cypher, GQL, SPARQL, Vadalog) into SQL or columnar scans against the source. PuppyGraph, MemGQL, Ontop, and Prometheux all live here. The selling points are flexibility (you can point at multiple data sources, including non-relational ones), language independence (you write graph queries in a language that has nothing to do with what the source database speaks), and zero ETL.
Graph queries native to the relational engine. Graph pattern matching is implemented inside the relational engine itself, exposed through its own query language. Oracle Graph, Postgres SQL/PGQ, Spanner Graph, BigQuery Graph, Fabric Graph, Kinetica all live here. The selling points are operational simplicity (no new infrastructure, your DBAs already know how to back it up), tight integration with the underlying optimiser, and language familiarity for SQL-first teams.
Layered engines on the other hand have language flexibility and source breadth, and the ability to perform unique optimizations of their own (e.g. an additional caching layer). On the flipside, they’re an additional system to deploy and maintain.
In-engine implementations get free leverage from a mature optimiser and consistent operational tooling, but they are bound to the host engine’s query language, its historical design decisions, and its idea of what a graph workload should look like.
There is no architectural winner in the abstract, only fit-for-purpose. Coming back to my earlier point, performance vs convenience is a choice within the graph-on-relational category itself!
PuppyGraph: a graph on relational breakthrough
PuppyGraph is widely regarded as the first productised LPG-style graph-on-relational engine to land with serious engineering and developer experience. The architectural pattern is older (OBDA systems on the RDF side have done graph over relational for over a decade, see the semantic-lineage section below), but PuppyGraph is the first to bring the layered approach into the labeled-property-graph world at production maturity, with Gremlin and Cypher as first-class query languages and a clean schema-mapping layer for vertices and edges that supports a (very) wide variety of heterogenous relational data sources.
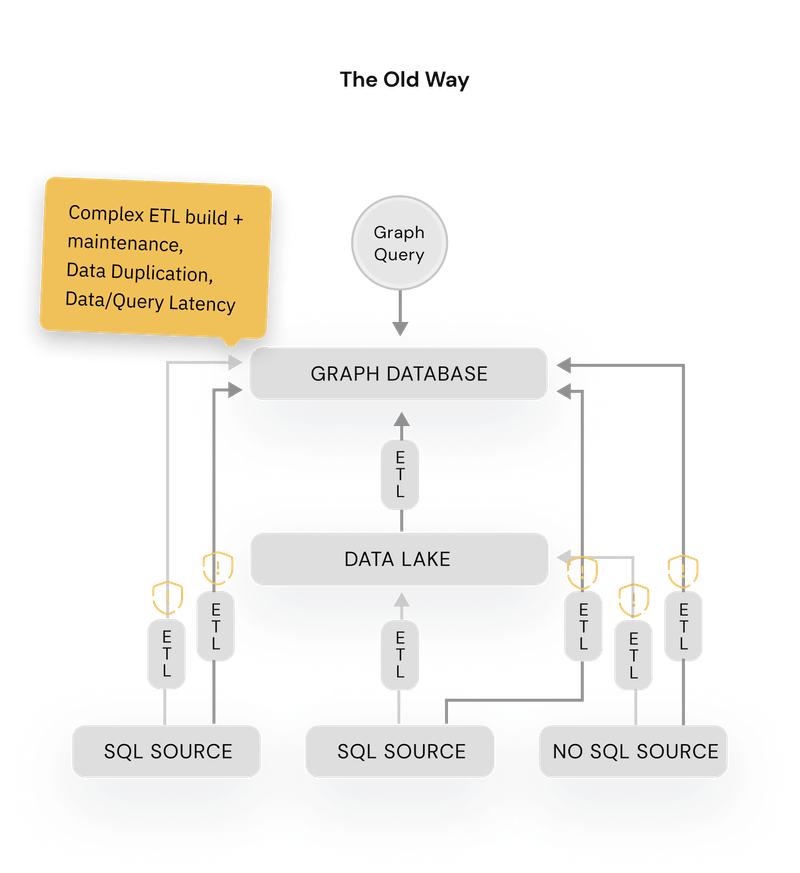
Source: puppygraph.com.
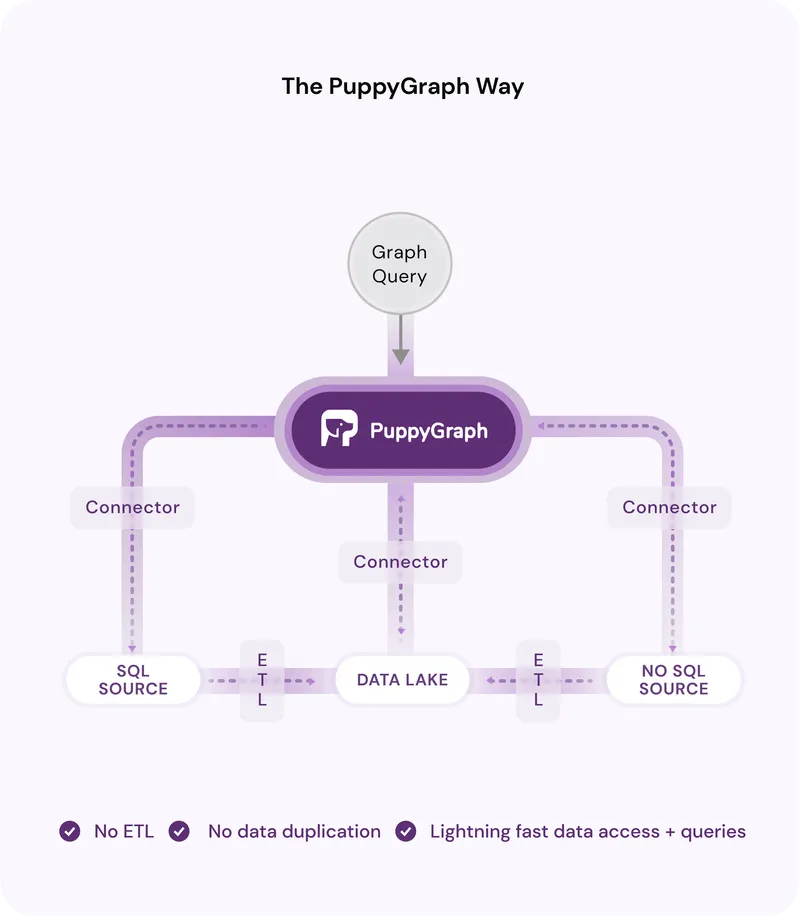
They’ve also perfected the pitch for graph-on-relational and have it best summarized in this one picture:
Source: puppygraph.com.
There are “limits” here. PuppyGraph is for analytical workloads and does not push writes to its downstream data sources. A typical downside of this is that whilst PuppyGraph can run complex, graph specific analytical workloads at scale (e.g. community detection, label propagation, etc) it cannot write those results back to the source data.
The upcoming SQL:2023 wave
The most consequential thing to happen to the in-engine side of the category is a standards document. SQL:2023 introduced SQL/PGQ (Property Graph Queries), a set of clauses that let you express graph pattern matching inside ordinary SQL against a property-graph view of your tables. The result is that any SQL engine can, in principle, add graph capability without inventing a new language or storage layer.
Oracle Database 23ai was the first commercial database to ship a serious SQL:2023 SQL/PGQ implementation, with MATCH clauses available against property-graph views built from existing tables. gdotv added Oracle Graph support via the SQL:2023 surface; you can read the announcement in our Oracle Graph release post for the integration details.
Postgres 19 is the other significant SQL/PGQ implementation and it’s still on its way, targeting release by the end of 2026. The Postgres approach is pragmatic: SQL/PGQ patterns are translated into recursive CTEs and executed by the existing planner. That is excellent for accessibility (no new index types, no storage layout changes, no operational changes), and underwhelming for performance on deep graph traversals (the planner has no idea it is looking at graph workloads). Marco Slot’s posetteconf 2026 talk (upcoming at time of writing) should provide some good details on where Postgres 19’s SQL/PGQ implementation lands on that axis.
Kinetica advertises SQL:2023 SQL/PGQ support in its real-time analytical engine. DuckPGQ is a community extension bringing SQL/PGQ to DuckDB, demonstrated in a DuckDB blog post on fraud-pattern detection in late 2025; the extension is active but the project’s pace is closer to research than to a vendor release train.
The hyperscalers go all in
The three biggest cloud platforms have each shipped a graph-on-relational story in the last 18 months, and all three made the same language bet.
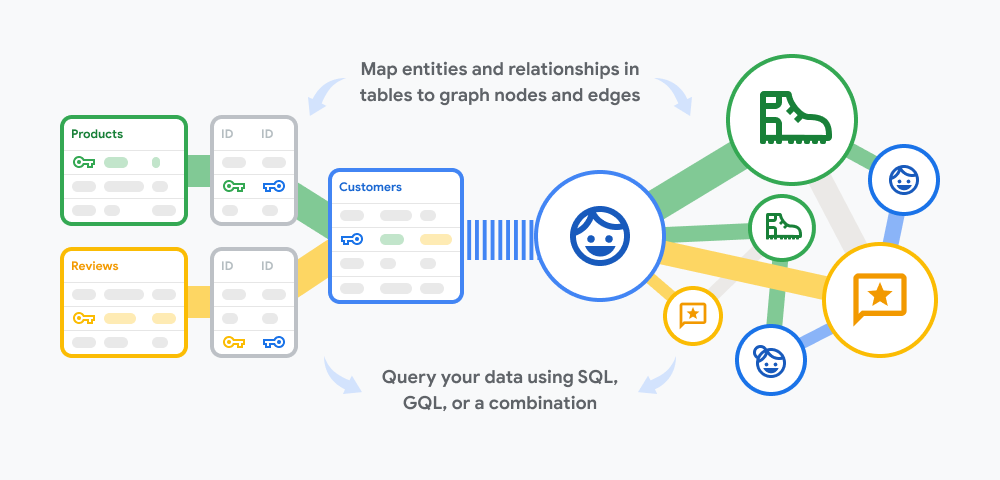
Source: cloud.google.com.
Google Cloud Spanner Graph went generally available in January 2025, bringing graph pattern matching alongside Spanner’s relational, search, and AI capabilities in one engine. BigQuery Graph is in public preview, doing the same at warehouse scale. Microsoft Fabric Graph is in public preview with general availability expected for 2026, layering graph queries onto Fabric’s lakehouse model.
gdotv is a partner with both Spanner Graph and BigQuery Graph, and you can read the Spanner Graph integration announcement for the technical detail.
Both Microsoft and Google bet on ISO GQL, rather than SQL/PGQ. That is a meaningful choice. GQL is a standalone graph query language, syntactically closer to Cypher than to SQL, and it ships with the assumption that graph is its own first-class workload rather than a feature stapled onto SQL.
For Google and Microsoft, both of whom serve teams that already mix graph-shaped and document-shaped and relational-shaped workloads daily, a standalone graph language at the API surface seems to have been the more strategic bet.
BigQuery Graph is also the strongest available demonstration that the graph-in-relational pattern can work at very large analytical scale. If the recurring industry argument is that graph-on-relational tops out before the workloads that matter, BigQuery Graph is the most credible counter-example on the public record.
Diverging query languages, briefly
The category is splitting along language lines, and it is worth being clear about who lands where.
SQL:2023 SQL/PGQ embeds graph pattern matching inside SQL itself. Oracle Graph, Postgres 19, Kinetica, and DuckPGQ all sit here. The selling point is that your SQL teams write graph queries without leaving the language they already know.
ISO GQL is a standalone graph language. Spanner Graph, BigQuery Graph, Microsoft Fabric Graph, and MemGQL all bet on it. The selling point is a first-class graph syntax with semantics built around graph workloads from the start.
PuppyGraph supports Gremlin and Cypher, predating both standards. pgGraph exposes graph operations as plain SQL functions (graph.search, graph.shortest_path) rather than committing to either standard yet. Prometheux sidesteps the question entirely with Vadalog, a Datalog+/- reasoning language we will look at in the semantic-lineage section below.
For users, this is another decision factor. Most workloads stay inside a single engine, so portability matters less in practice than it does on the standards-body whiteboard. But portable graph code across these engines is not here yet, and the engines that have made the most public effort toward portability (notably MemGQL, which bets specifically on GQL as the common surface across both relational and native graph backends) are still early-stage offerings rather than mature defaults.
The longer-arc effort to bridge the two standards (and to unify RDF and labeled property graph models on top of that) is the LEX project under the Graph Data Council, which the GraphGeeks team wrote up in detail in 2025. Worth tracking standards evolve slowly. One thing is clear: GQL is here to stay and we’ll be seeing a lot more of it in the future.
The semantic lineage, and the systems breaking from it
The RDF and ontology-based side of the field has been doing graph-on-relational longer than the LPG side has, and sits in a meaningfully different problem domain. Two positions are worth distinguishing.
Pure RDF and OBDA. Ontop is the textbook case. Originating as academic work at the Free University of Bozen-Bolzano, Ontop translates SPARQL queries into SQL against the source relational database via R2RML and OBDA mappings. Ontopic, the company behind Ontop, was acquired by Digital Science in March 2026 and is being integrated with the metaphactory platform. The acquisition framing leans explicitly into AI reasoning workloads: “enable AI agents to reason over real-time, distributed data with full context and zero duplication.” Read in industry-trend terms, that is a meaningful signal that virtual knowledge graphs are crossing from niche academic and enterprise tooling into mainstream semantic-layer infrastructure.
Virtuoso and GraphDB have related virtualisation capabilities, but they sit in a different posture (full triplestore plus virtualisation rather than virtualisation-first).
Breaking from the graph DB paradigm entirely. Prometheux is the most interesting case in this section, because it explicitly rejects graph database categorisation while doing the same architectural thing: an ontology engine over arbitrary data sources without ETL.
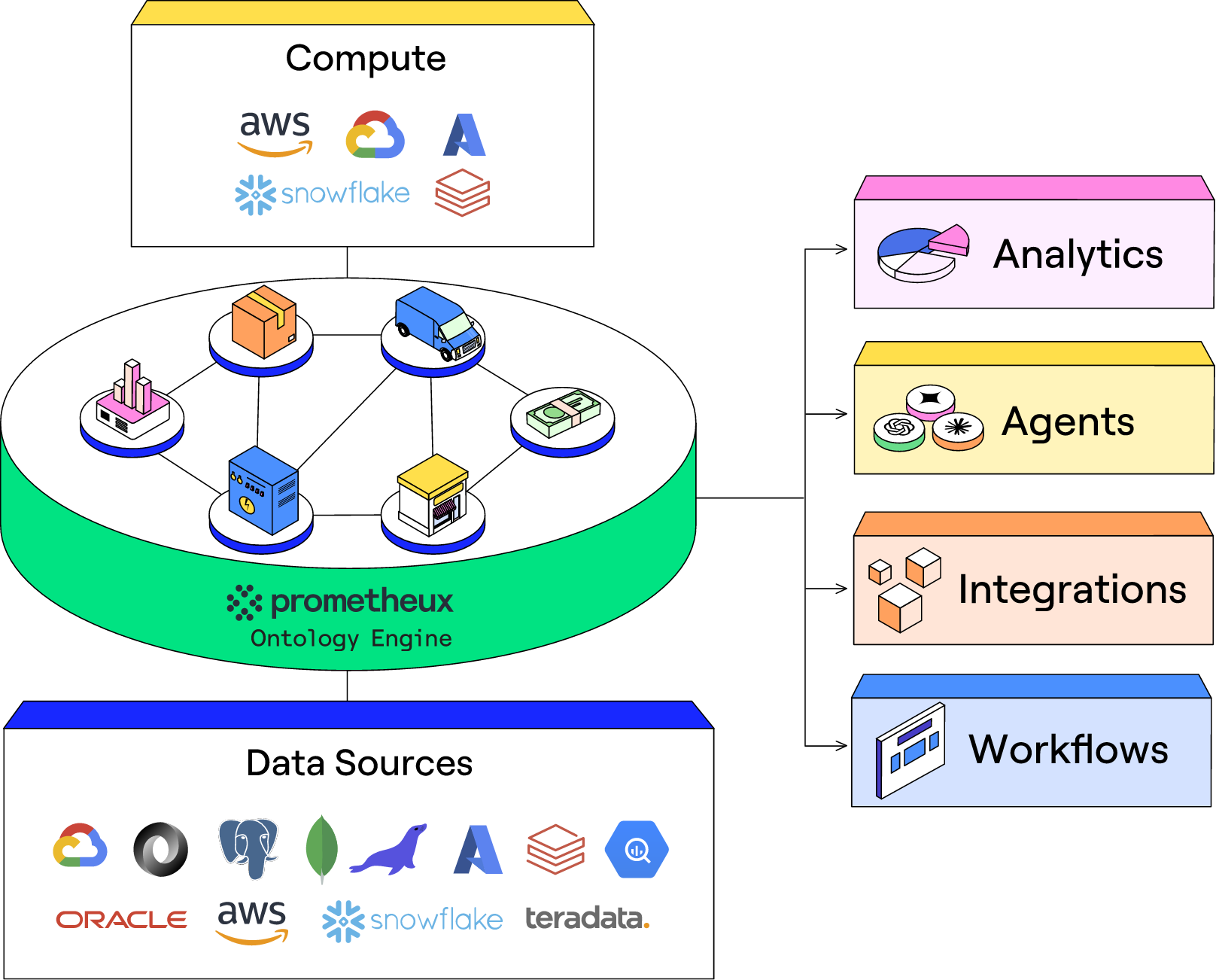
Source: onpx.ai.
Prometheux’s query language is Vadalog, a member of the Datalog+/- family. Per their docs, Vadalog is “declarative and highly expressive” and capable of expressing “all SQL and Cypher queries” within a single language. That is a genuinely different angle from both RDF and LPG. Instead of starting from “what is the right graph data model” the system starts from “what is the right reasoning language for ontology-driven data access”, and graph traversal falls out as a subset of what is expressible. Prometheux is generally available, with named enterprise customers in production including Banca Sella, Dompé, and AstraZeneca.
RDF’s primary purpose in this space is semantic unification and federated reasoning across sparse data. This is a different problem domain from LPG-style traversal even though the architectural shape (graph queries over relational sources) is the same. Prometheux is the proof that you can occupy this architectural shape without inheriting either the RDF stack or the LPG-versus-relational rivalry.
Emerging and on the fringe
The category is still expanding. Two very recent entrants are worth flagging without overpromising on their maturity.
pgGraph is a Postgres extension that exposes graph search, traversal, shortest-path, and relationship queries against ordinary Postgres tables, surfaced as SQL functions in a graph schema (graph.search, graph.shortest_path). The project is in alpha, with a small commit count and a clear “avoid production use” note from the maintainer. Worth watching as a potential better alternative to Apache AGE and SQL/PGQ for Postgres.
MemGQL, from the Memgraph team, ships as a federated GQL query engine: it translates ISO GQL into the native language of whatever backend holds your data, executes in place, and returns unified results. The launch connectors cover Postgres, MySQL, DuckDB, Apache Iceberg, ClickHouse, Apache Pinot, plus Memgraph and Neo4j on the graph-native side. MemGQL Community shipped at launch; Enterprise is available on request; Cloud is “coming soon”. It is the most explicit cross-engine portability bet in the category to date, and if it succeeds it makes the diverging-language story above a much smaller problem.
Why graph matters in the first place
It is worth stepping back from the architectural taxonomy and asking the obvious question. None of this matters unless graph thinking is the right model for a workload in the first place. Four use cases, vendor-neutral, where it consistently is.
Fraud and AML pattern detection. When the signal you are trying to find is a pattern across multiple entities and their relationships (a ring of accounts moving funds in a circular path, a merchant whose chargeback graph looks structurally identical to a known scam network, a borrower whose phone number, address, and employer all link to other flagged borrowers), graph traversal is the right shape of computation. This use case lands cleanly in the graph-on-relational column because the source data is almost always already in a SQL warehouse or operational database, and the queries are analytical rather than transactional.
Supply chain impact analysis. When a supplier fails or a material is recalled, what you need to know is “which products, which orders, which customers, which markets are downstream of this fact.” That is a multi-hop reachability query over data that already lives in ERP and warehouse-management systems. Same posture as fraud: relational source, analytical workload, graph-on-relational fits naturally.
Knowledge graphs and GraphRAG. Retrieval-augmented generation systems built on top of LLMs increasingly benefit from a graph layer that captures explicit relationships between entities mentioned across a corpus. Whether to back that graph with a graph-on-relational engine or a native graph store depends mostly on scale, write-frequency, and whether you need semantic reasoning on top. The Ontop and Prometheux end of the field is doing the most interesting work here, because semantic reasoning was their original problem.
Identity, access, and network graphs. Modelling who has access to what, or which devices talk to which services, is graph-native by definition. These workloads often have deeper traversal patterns, higher write rates, and stricter latency requirements, which is exactly the territory where native graph databases continue to earn their keep. The wider point: graph-on-relational and native graph each have a natural home, and identity and access workloads tend to live closer to the native end.
In conclusion
Choosing a database is hard. At first glance, graph-on-relational technology introduces new variables in your decision making and therefore an even harder decision to make. In effect, it provides a better decision tree.
If your data lives in a SQL system and you want graph capability without any new infrastructure or operational change: graph in relational fits (the in-engine implementations described in the two-architectures section above). SQL:2023 SQL/PGQ in Oracle, Postgres, or Kinetica, and ISO GQL in Spanner, BigQuery, or Fabric, all give you graph queries inside the database you already run. Maximum convenience, with a performance ceiling to consider. Whether it’s a glass ceiling or a hard ceiling remains to be seen.
If you need to support more than two distinct workload types against the same data and infrastructure (graph plus document plus full-text search, say, or graph plus relational plus vector and key-value): multi-modal databases are worth a look. The hyperscaler in-engine offerings (Spanner Graph, BigQuery Graph, Microsoft Fabric Graph) also carry strong multi-modal attributes of their own, putting graph capability alongside relational, search, vector, and (in Spanner’s case) key-value within a single engine. The convenience compounds as workload variety grows.
If you want better performance on graph workloads but still do not want to copy your data into a separate graph store: true to form graph on relational fits (the layered separate-engine architecture). PuppyGraph and MemGQL put a dedicated graph compute engine in front of your existing source databases, owning the plan rather than leaving it to a relational optimiser. Mid convenience (one new piece of infrastructure to run), markedly better performance ceiling on deep traversals and multi-hop analytics.
If your data is fundamentally connected and graph thinking is on the critical path for your application’s design: this is what graph databases exist to solve.
If your problem is semantic unification, reasoning across sparse or heterogeneous sources, or grounding an AI agent in a knowledge graph: semantic on relational fits. Ontop, Prometheux, and the wider ontology-engine family are purpose-built for this. The architectural shape is the same as graph on relational, but the surface and intent are different. You are asking the engine to reason, not just to traverse.
What is genuinely new is that the middle ground exists. Five years ago, every graph workload demanded ETL, a separate engine, and a separate operational story. Today, depending on which corner of the map you sit in, you can run graph queries against your existing data with no new infrastructure at all. That is the real story this post has been mapping, and it is one worth tracking through 2026 and beyond.
Just one final thing: if you’re considering picking up a graph-on-relational engine, or already deep in the works with one, you should try gdotv out. We’re already compatible with most of the engines listed in this article and our graph visualization client will give you lots of great tools to work with these technologies better and faster!


