The Weekly Edge: Zero ETL Federated GQL, Context Graphs Beyond the Hype, Graph AI Memory & More

Howdy, partner! Your Weekly Edge correspondent is headed to New York City next week – for The Knowledge Graph Conference 2026 – and is fixin’ to show off his West Coast / Best Coast regional pride while at the event. 🤠
However, I’ve been informed, politely but firmly, that Silicon Valley does not actually count as cowboy country, and that a NorCal accent sounds less like John Wayne and more like asking the barista where the oat milk is. 😬
But there’s graph tech news to wrangle first: The Weekly Edge is your tl;dr of the most useful news, views, reads, and releases from across the world of connected data, curated by the team at gdotv. New here? Pull up a bar stool. 🍺
Here’s what we rounded up in this week’s graph tech corral:
- Zero ETL, all GQL: MemGQL brings federated Graph Query Language to your data without having to move a byte
- No more runtime surprises: Gremlinq is here to grant you type-safe .NET passage for AWS Neptune in this trail guide
- It’s those dadgum context graphs: The NODES AI keynote unpacks why graph context is so hot right now
- Even Oracle has something to say: A handy walkthrough on building a unified AI memory core for agents using Oracle Graph and more
- Gettin’ back to the basics: Have you ever read the Good Book? The one on graph databases? It’s never too late to have your come-to-O’Reilly moment
// It’s time to level up your graph game: Query, explore, edit, and visualize your connected data with the gdotv graph IDE. Try it out with a 1-month, no-fuss free trial.
Y’all ready? Let’s ride. 🤠🐴
[Release:] MemGQL: Federated GQL over Postgres, Graph Databases + Data Lakes
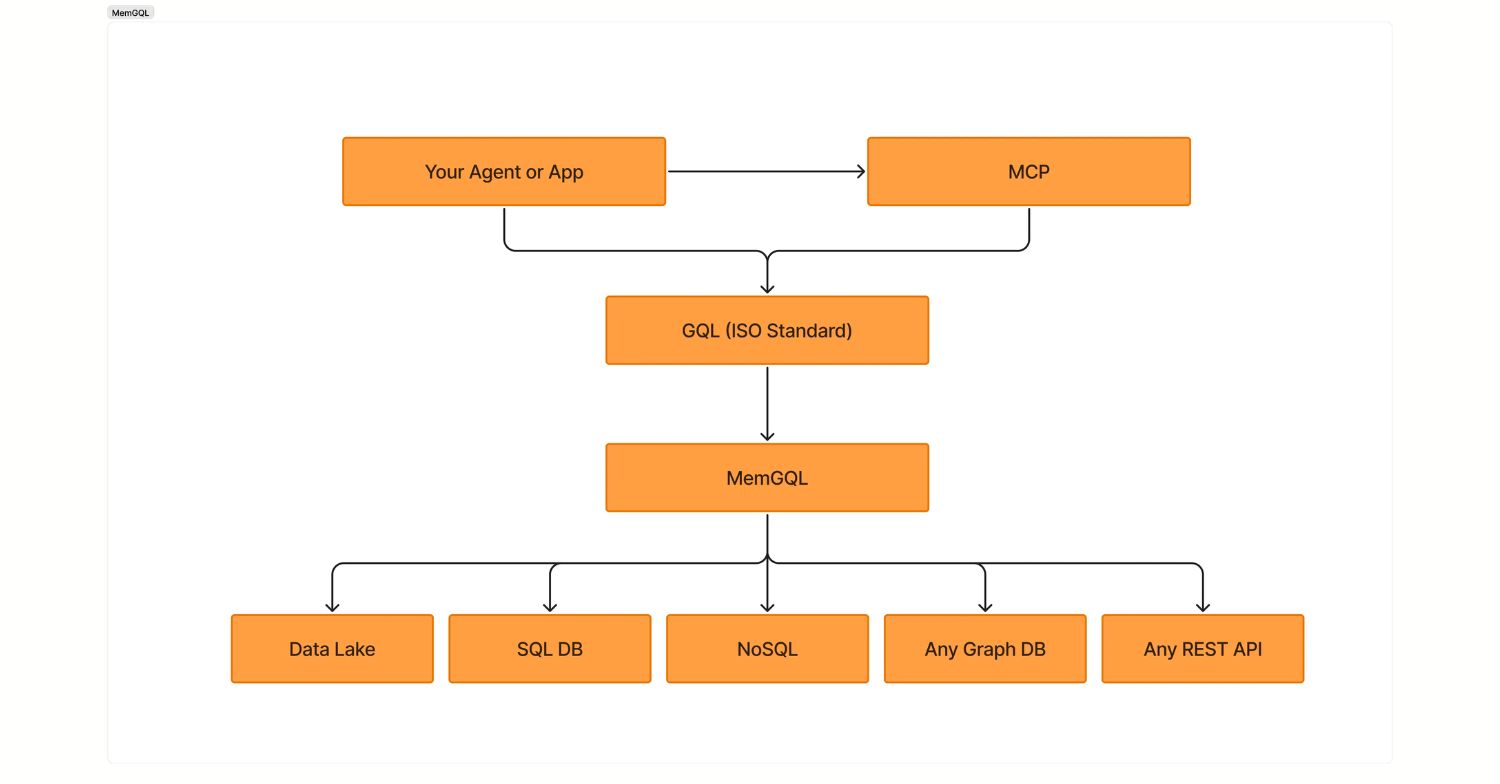
Your data is everywhere: a little Postgres here, a little graph database there, an Iceberg data lake somewhere in between, and nobody wants to build yet-another ETL pipeline just to ask a graph question across all of it. That’s precisely the problem MemGQL is built to solve.
The newest addition to the Memgraph Zero product line, MemGQL is a federated ISO GQL query engine that translates standard graph queries into the native language of all of your connected backends – whether that’s Postgres, ClickHouse, DuckDB, Apache Iceberg, Neo4j, or Memgraph itself – and returns unified results without moving a single byte of data. It’s a similar “query the data where it lives” philosophy to PuppyGraph, but extended across a wider ecosystem of backends and grounded in the ISO Graph Query Language standard.
Curious to learn more? Join the Memgraph community call happening 7 May 2026 (usually recorded for later too) and hear all about MemGQL straight from CTO Marko Budiselić.
[Walkthrough:] Type-Safe .NET Development for AWS Neptune with Gremlinq

If you’ve ever shipped a Gremlin query only to have it explode at runtime because of a misspelled property name, Gremlinq was built to save you that pain. The open source .NET OGM – previously covered by the Weekly Edge – brings compile-time type checking, IntelliSense-guided development, and LINQ-style query syntax to Gremlin traversals, so your IDE catches mistakes instead of your production logs. (Wait, did you need a Gremlin IDE?)
In this week’s developer walkthrough, Gremlin Overlord Stephen Mallette and Gremlinq creator Daniel Weber take you through setting up an AWS Neptune project using Gremlinq’s .NET templates, complete with domain modeling, relationship traversals, subqueries, projections, aggregations, and more. It’s a great intro to Gremlinq, of course, but also a great first-time project for folks curious to get started with Neptune. (And y’all, that Gremlinq mascot! 😍 )
//
[Watch:] NODES AI Opening Keynote: Exploring Context Graphs from Data to Decisions
2025 was supposed to be the year of agents in the enterprise. So why did so many fail in production? That’s the question at the heart of this opening keynote from NODES AI 2026, where Neo4j CTO Philip Rathle moderates a sharp panel with Emil Eifrem (CEO, Neo4j), William Lyon (Product, Neo4j), Lasse Andresen (CEO, IndyKite), and Animesh Koratana (CEO, PlayerZero) on context graphs.
The central idea: Every AI decision leaves a “decision trace,” or the why behind an outcome that traditional systems of record never capture. Context graphs are a fabric of those traces, giving AI agents institutional memory they can actually learn from. The panel covers real-world implementation challenges, governance, the bottom-up vs. top-down ontology debate, and what’s coming next from Neo4j.
(And this is just one of the many talks from NODES AI 2026 now on YouTube.)
[Long Read:] How to Build a Unified Memory Core for AI Agents Using Oracle
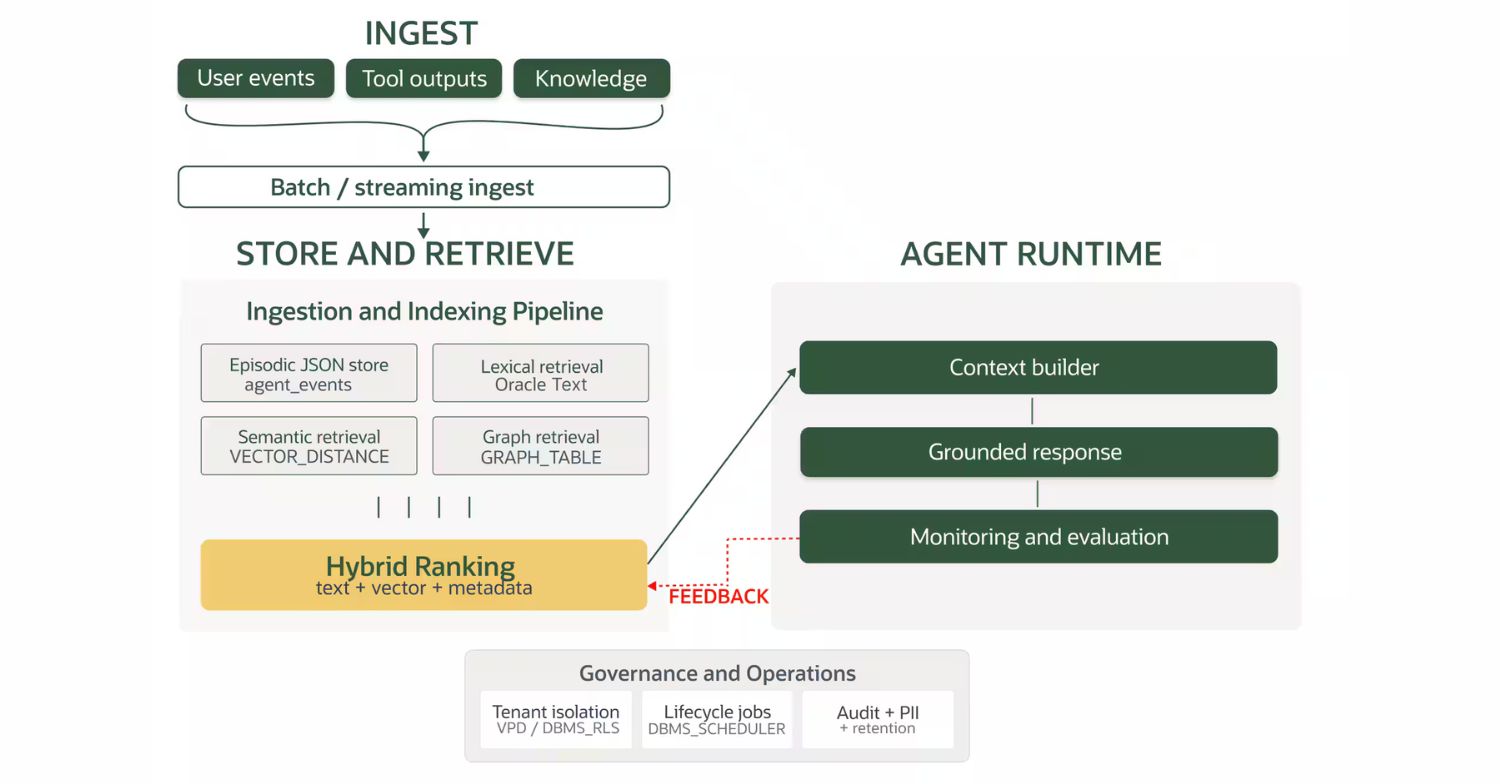
Not every good idea comes from a hot startup. Sometimes it comes from the company whose invoice once made your CFO cry. Set aside your Oracle feelings for a moment, because Daniela Pavlenco has written a solid long read – backed by a companion notebook – on building a unified memory layer for AI agents with ideas worth stealing regardless of your database religion.
Daniela’s core argument: agent memory isn’t one thing; it’s four. AI memory is made up of episodic (event history), lexical (keyword retrieval), semantic (vector search), and relationship-aware (graph traversal) memory, and most architectures fragment these across too many disconnected systems.
In this walkthrough, Daniela shows you how to use Oracle AI Database’s GRAPH_TABLE function, Oracle Text, vector indexes, and tenant-aware row-level security to unify all four types of AI memory into one governed platform. The graph traversal piece in particular surfaces connected context (user → ticket → document) that pure vector search quietly misses.
[ICYMI:] The OG, O’Reilly Graph Databases Book

If you’ve ever wondered where to start with labeled property graph databases Jim Webber, Ian Robinson, and Emil Eifrem wrote the book on it – literally.
The O’Reilly Graph Databases book covers the fundamentals of the labeled property graph model, Cypher query language basics, graph data modeling, and real-world use cases from social networks to recommendation engines and access control.
Is it old? Sure. Is it still one of the clearest introductions to why graphs make you think differently than relational databases? You can bet your boots on it. And since it’s completely free, there’s really no excuse not to grab your copy. Of course, if you’d prefer a non-technical intro to graphs, your correspondent also wrote a book on graph tech for ultra-beginners – just sayin’.
P.S. Psst! Did you know gdotv turns your SHACL validation shapes into a unified RDF data model? The more you know! 🦚
P.P.S. There’s a new edition of Practical Gremlin roaming the hills, so we made you a new getting-started guide to graph databases to match it. 🐃
P.P.P.S. Got an item to nominate for the next edition of the Weekly Edge? Hit me up at weeklyedge@gdotv.com. ✍🏽


