Building a Property Graph Pipeline from the TEG Benchmark: Part 1 – From HuggingFace to Structured CSV

Introduction
The Text-Enriched Graph (TEG) benchmark is a collection of heterogeneous graph datasets in which every vertex and every edge carries a natural-language description. Originally developed to support research at the intersection of graph neural networks and large language models, the benchmark spans ten datasets across four domains (social networks, academic citation graphs, e-commerce review graphs, and literary recommendation systems) making it an unusually rich substrate for studying how textual signals interact with graph topology. This post documents the first phase of a larger engineering effort: acquiring the TEG datasets, understanding their binary serialization format, and converting them into structured CSV files suitable for ingestion into a property graph database.
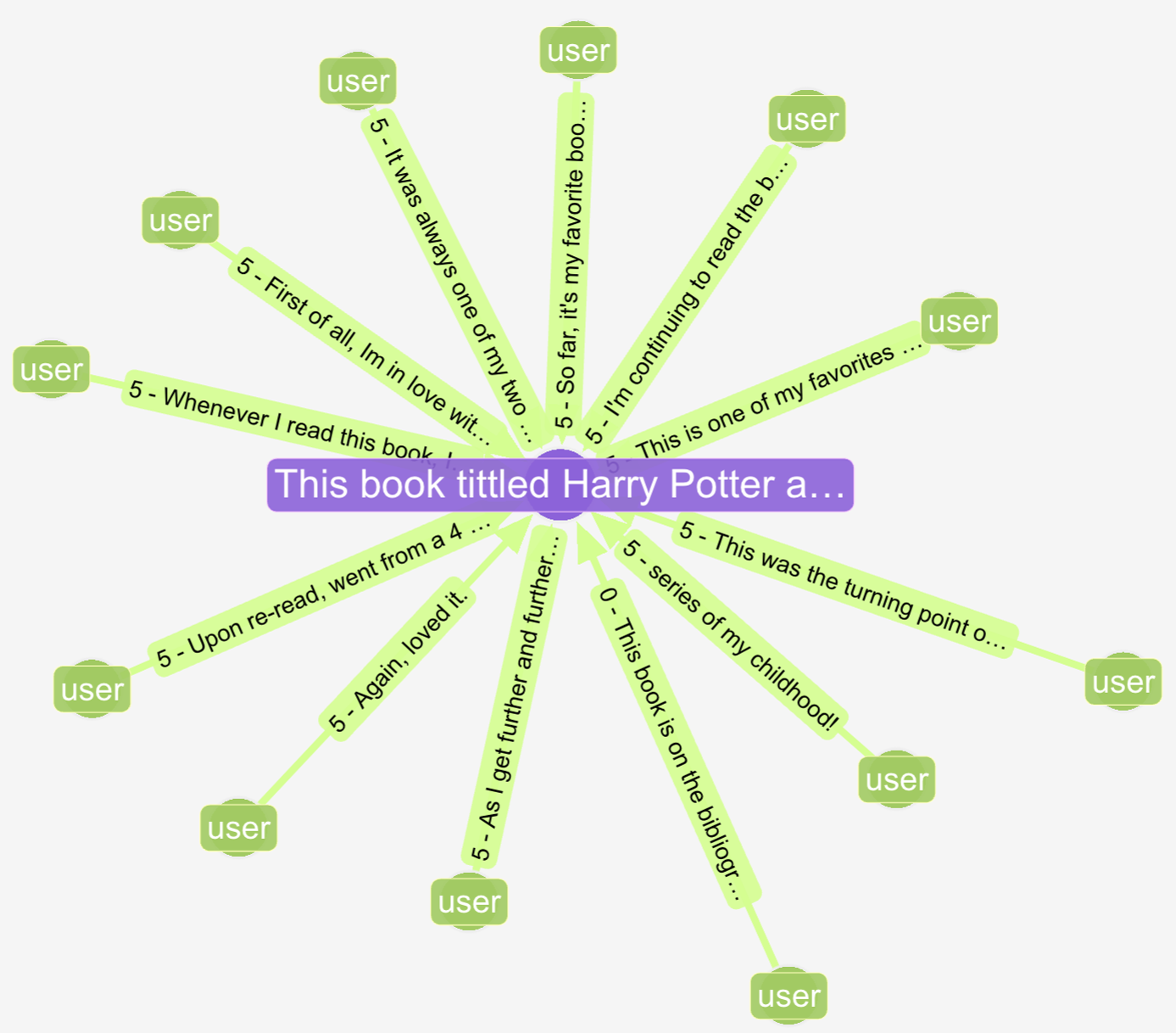
A book node from the Goodreads TEG dataset in gdotv: each edge carries the review text and star rating, making relationships semantically distinct in ways binary adjacency cannot encode.
What Is Actually Wrong with Textless Edges?
The motivating argument behind the Text-Enriched Graph benchmark rests on a claim that is straightforward but, until recently, largely unaddressed in the graph learning literature: the edges of a graph are not semantically neutral. A citation from Einstein to Planck’s 1900 paper on blackbody radiation is not the same kind of relationship as a citation from a twenty-first-century textbook author to the same paper, even though both manifest as an identical directed edge in a standard graph representation. The relationship encoded by a citation carries intellectual content (confirmation, contestation, extension, acknowledgement) and that content is precisely what binary graph topology discards.
The TAG (Text-Attributed Graph) paradigm, which has gained substantial traction in recent years through datasets such as ogbn-arxiv, Cora, Citeseer, and PubMed, addressed one dimension of this impoverishment: it attached natural language to nodes. A paper became more than a featureless vertex; it became a vertex with a title and abstract. What TAG left untouched, however, was the edge. The relationship between two papers remained a 0 or a 1, a presence or an absence, stripped of the sentence that motivated the citation in the first place. The TEG benchmark was designed to close that gap.
This post (Part 1) walks through the mechanical process of acquiring the TEG datasets from HuggingFace, unpacking their PyTorch Geometric serialization format, and converting them to structured CSV files for property graph ingestion. Part 2 turns to the Neptune Bulk Loader approach, which proved more reliable at TEG-DB scale, and walks through staging the CSV files in S3, establishing a connection from gdotv via IAM authentication, and verifying the loaded graph. Part 3 then asks what the benchmark actually enables once the data is live: four queries in gdotv demonstrate what edge text reveals that graph topology cannot. Part 4 steps back from the engineering to offer a critical reading of the benchmark itself, examining what the design choices enable and, more importantly, what they preclude.
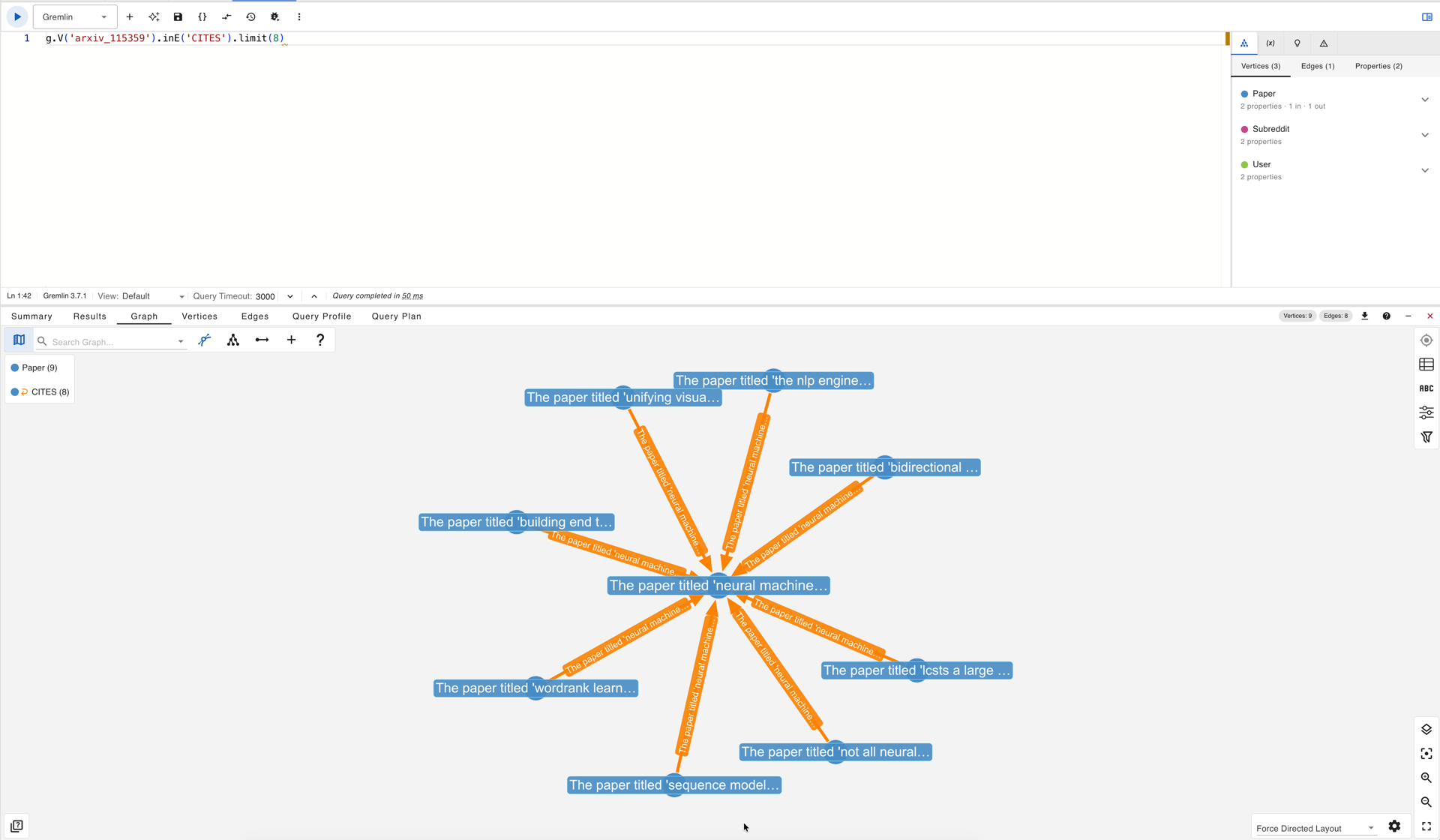
Citation neighborhood of the Bahdanau attention paper rendered in gdotv after loading the Arxiv TEG dataset into Neptune.
The figure above shows the immediate citation neighbourhood of the Bahdanau attention paper, “Neural Machine Translation by Jointly Learning to Align and Translate” (Bahdanau, Cho, and Bengio, 2014), as rendered in gdotv after loading the Arxiv graph into Neptune. Eight papers cite this vertex, and the graph topology records each of those citations as an identical directed CITES edge. What the topology cannot record, and what the edge text makes immediately legible, is that those eight relationships are qualitatively distinct.
The paper “WordRank: Learning Word Embeddings via Robust Ranking” cites the attention paper to position it as a field-level achievement: its citation sentence reads that attention is “one of the most important advancements in deep learning in recent years” and “is now widely used in state-of-the-art image recognition and machine translation systems.” This is an evaluative citation as it invokes Bahdanau not to use the mechanism but to establish the significance of a class of methods. By contrast, “A Neural Conversational Model” uses the same edge to record a negative result: “adding the soft attention mechanism of (Bahdanau et al., 2014) did not significantly improve the perplexity on neither training or validation sets.” Two directed edges from two papers to the same vertex; one a tribute, one a refutation. In a standard graph, these relationships are indistinguishable. In a TEG-format graph, they are separated by the full semantic distance between a commendation and a null result.
A third edge, from “End-to-End Continuous Speech Recognition Using Attention-Based Recurrent Neural Networks,” cites the paper for a very specific technical claim about phoneme alignment, noting how the absence of a learned monotonicity preference causes the model to fail on repeated phoneme sequences. This is a usage that has nothing to do with machine translation but borrows a theoretical property of the attention mechanism for a different domain. This kind of cross-domain appropriation of a mechanism, visible only in the citation sentence, is precisely the phenomenon that motivates the TEG benchmark and precisely what binary graph topology cannot encode.
Across this series, you’ll transform the TEG dataset into CSV files formatted for Amazon Neptune, import those files into Neptune, then connect gdotv to Neptune to run queries in Gremlin and openCypher. The graph visualizations shown throughout these posts come from that pipeline.
The TEG-DB Benchmark: What Is in the Box?
![]()
TEG-DB benchmark logo. Source: Li et al. 2024, used with attribution.
The TEG-DB benchmark comprises ten datasets drawn from four broad domains. In the academic domain, the Arxiv dataset is constructed from the Open Graph Benchmark’s ogbn-arxiv corpus, with citation context sentences extracted to serve as edge text and paper titles with abstracts constituting node text. In the e-commerce domain, three Amazon review datasets spanning Android applications, baby products, and movies and television which represent bipartite reviewer-to-product graphs in which each review serves as an edge. In the literary recommendation domain, four Goodreads datasets cover the children, comics, crime, and history genres, again as bipartite user-to-book graphs with review text on edges. The social network domain contributes two datasets: a Reddit comment graph and a Twitter mention-and-retweet graph.
The table below summarises the ten datasets. Node and edge counts are from the paper’s Table 1 (Li et al., arXiv:2406.10310, submitted 14 June 2024). TEG-DB’s claim to novelty rests almost entirely in the rightmost column.
| Dataset | Domain | Nodes | Edges | Node Text (Prior) | Edge Text (TEG, new) |
|---|---|---|---|---|---|
| Arxiv | Academic / Citation | 169,343 | 1,166,243 | Yes (ogbn-arxiv: title + abstract) | Yes |
| Social Network | 478,022 | 676,684 | Partial (subreddit name only) | Yes | |
| Social Network | 18,761 | 23,764 | No | Yes | |
| Amazon Apps | E-Commerce | 31,949 | 62,036 | Partial (item title) | Yes |
| Amazon Baby | E-Commerce | 186,790† | 1,241,083† | Partial (item title) | Yes |
| Amazon Movie | E-Commerce | 137,411 | 2,724,028 | Partial (item title) | Yes |
| Goodreads Children | Literary Rec. | 216,624 | 858,586 | Partial (book title) | Yes |
| Goodreads Comics | Literary Rec. | 148,669 | 631,649 | Partial (book title) | Yes |
| Goodreads Crime | Literary Rec. | 422,653 | 2,068,223 | Partial (book title) | Yes |
| Goodreads History | Literary Rec. | 540,807 | 2,368,539 | Partial (book title) | Yes |
† Amazon Baby did not surface in our extraction of the paper’s Table 1 HTML; these figures are from the benchmark repository README.
The Goodreads Crime and History datasets are the largest in the collection, at 422k and 540k nodes respectively and around 2M edges each, substantially larger than the Arxiv citation graph that receives most attention in the paper. The edge text on those Goodreads History edges is almost entirely formulaic reviews, which feeds directly into the semantic entropy argument in Part 4. The Twitter graph is conspicuously small at 18,761 nodes and 23,764 edges, a striking size for a social network dataset and a sign of significant filtering or a narrow sampling window during construction.
Acquiring the Datasets
The TEG datasets are hosted on the Hugging Face Hub under the repository identifier ZhuofengLi/TEG-Datasets. Rather than cloning the repository through Git, which would require Git Large File Storage support and result in downloading several gigabytes of pre-computed embedding files that are irrelevant to the graph import task, the acquisition was performed using the snapshot_download function from the huggingface_hub library. The invocation below fetches only the structural data while excluding the large .pt embedding tensors.
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="ZhuofengLi/TEG-Datasets",
repo_type="dataset",
local_dir="./Dataset",
ignore_patterns="*.pt"
)
After the download completes, the Dataset directory contains ten subdirectories, one per domain, and each following the same internal layout: a processed/ folder holding a serialized PyTorch Geometric Data object, a raw/ folder that is either empty or contains a processing notebook, and in some cases an emb/ folder containing pre-computed JSONL embedding requests. The raw source files for the Amazon and Goodreads datasets, which are large JSON corpora from separate academic repositories, are tracked as LFS pointers in the upstream repository but are not automatically resolved during a snapshot_download. Those datasets therefore require separate acquisition from the McAuley Group data servers at UCSD, a process addressed in a companion download utility.
The Serialized Data Format
Every dataset in the TEG benchmark is stored as a Python pickle file containing a PyTorch Geometric Data object. This class is a flexible attribute container built on top of PyTorch tensors; it imposes no fixed schema, and the TEG authors use it to store four primary attributes across all ten datasets.
The edge_index attribute is a torch.long tensor of shape [2, num_edges] in COO (coordinate) format, where row zero holds the source node identifiers and row one holds the destination node identifiers for each directed edge. The text_nodes attribute is a Python list of length num_nodes, intended to hold a natural-language description for each vertex. The text_edges attribute is a list of length num_edges carrying a textual description for each relationship: a review, a citation context, or a social post. Finally, the node_labels attribute is a list of length num_nodes containing category labels for supervised learning, with the integer -1 used as a sentinel to mark vertices that carry no label.
This schema is consistent in principle, but the implementation reveals several per-dataset deviations that must be handled explicitly during conversion. Three such deviations were significant enough to require bespoke logic.
Discovering and Resolving Dataset-Level Anomalies
The Reddit Text Index Inversion
The Reddit dataset was processed by a loop that iterates over every row in the source CSV and appends node texts unconditionally on each iteration, regardless of whether the node has already been seen. For each row, the subreddit text is appended first and the user text second, meaning that text_nodes grows at twice the rate of the edge list and ultimately contains two entries per edge rather than one entry per unique node. The edge_index, by contrast, correctly tracks unique node identifiers through a deduplication dictionary that assigns each new node a monotonically increasing integer. The consequence is that text_nodes[i] does not correspond to the text for node i; the list is indexed by edge-iteration position, not by node identity.
Correcting this required a reconstruction pass. By iterating over edge_index and reading text_nodes with the formula text_nodes[2*i] for the destination node of edge i and text_nodes[2*i+1] for the source node, the correct node-to-text mapping can be recovered. This reconstruction is performed once and the result is stored in a dictionary keyed by node identifier, which is then used normally during CSV writing.
Inconsistent Label Attribute Naming
The four Amazon datasets and the four Goodreads datasets store per-node labels under the attribute name text_node_labels, whereas the Reddit, Twitter, and Arxiv datasets use the attribute name node_labels. This inconsistency is not documented anywhere in the benchmark repository and was discovered by inspecting the processing notebooks for each dataset family. The conversion pipeline handles this by storing the correct attribute name for each dataset in a registry and using getattr with the appropriate key at runtime.
Edge Scores and Tensor Types
The review-based datasets, Amazon and Goodreads, attach a numerical star rating to each edge through an edge_score attribute that is absent from the social-network and citation datasets. In the Amazon datasets this attribute is stored as a plain Python list, while in the Goodreads datasets it is stored as a torch.long tensor. Both representations must be normalized to a plain Python float before being written to CSV. This is handled by a to_scalar utility function that calls .item() on tensor values and passes Python primitives through unchanged.
Designing the Node-Type Inference
Because the Data object does not explicitly label nodes by type, the conversion pipeline must infer vertex labels from the content of the text_nodes entries. The TEG authors followed a consistent convention when constructing these strings: subreddit nodes begin with the word "subreddit", user nodes begin with the word "user", tweet nodes contain exactly the string "tweet", reviewer nodes contain exactly the string "reviewer", and all other nodes (i.e., book descriptions, product descriptions, paper abstracts) belong to the destination type of their respective graph. For the Arxiv citation graph, which is homogeneous, both endpoints of every edge carry the label "Paper" without any inference being necessary.
This inference is encoded as a pure function that takes the node’s text string, the source type, and the destination type for the dataset in question, and returns the appropriate vertex label. The logic runs in constant time and adds negligible overhead to the conversion process.
Producing Neptune-Compatible CSV Files
The output format targets the Amazon Neptune Bulk Loader, which expects two CSV files per graph: a vertex file and an edge file. Neptune uses a header-driven convention in which column roles are declared by prefixing column names with a tilde (~) for structural fields (i.e., ~id, ~label, ~from, ~to) and by appending a type annotation for property fields (text:String, score:Double). This typed header allows Neptune to build the appropriate internal indices without requiring a separate schema declaration.
The vertex file for each dataset contains one row per unique node, with its integer identifier, inferred label, natural-language text, and category label. The edge file contains one row per directed relationship, with a sequential edge identifier, the source and destination node identifiers resolved from edge_index, the relationship type, the associated text, and where available, the numerical rating stored as a Double. Both files are written with full quoting to handle embedded newlines, commas, and quotation marks that appear frequently in the review and post text fields.
Results
Running the conversion pipeline against the local dataset files produces counts that differ from both the paper’s Table 1 and the benchmark repository README. The table below shows all three sources side by side for the two social-network datasets converted for this post.
| Dataset | Paper Table 1¹ | Repository README² | This conversion |
|---|---|---|---|
| 478,022 nodes / 676,684 edges | 512,776 nodes / 256,388 edges | 478,000 nodes / 942,063 edges | |
| 18,761 nodes / 23,764 edges | 60,785 nodes / 74,666 edges | ~160,000 nodes / ~150,000 edges |
¹ Li et al. (2024), arXiv:2406.10310, Table 1, submitted 14 June 2024.
² TEG-Benchmark repository README (github.com/Zhuofeng-Li/TEG-Benchmark), accessed May 2026.
Reddit. The converter’s node count (478,000) matches the paper’s figure of 478,022 to within rounding; the build_node_map_reddit reconstruction walk across edge_index correctly recovers the full node set. The edge count is a different story: the PKL yields 942,063 edges, against the paper’s 676,684 and the README’s 256,388. The README figure is anomalous in its own right: 256,388 edges across 512,776 nodes is unusually sparse for a social posting graph, and inconsistent with both other sources. The converter reads edge_index.shape[1] directly and reports exactly what is in the file, so 942,063 is the ground truth for the HuggingFace distribution. The most likely explanation is that the dataset was expanded after the paper’s benchmarks were completed: the node population is stable across the paper and this conversion, but the edge set in the distributed PKL is substantially larger.
Twitter. The discrepancy here is more substantial. The converter produces approximately 160,000 nodes and 150,000 edges, roughly 8× more nodes and 6× more edges than the paper’s 18,761 / 23,764. The README’s 60,785 / 74,666 falls between the two, suggesting the dataset has been expanded at least twice since the paper was submitted. For Twitter, build_node_map_indexed simply enumerates data.text_nodes, so the PKL contains approximately 160,000 node entries. The infer_node_type function maps both author users and mentioned users to the single label User, and tweet nodes to Tweet, producing two node types in the output, not three. The PKL’s edge_index contains approximately 150,000 edge records; the current converter labels all of them POSTED, though the underlying data contains two relationship types (author-to-tweet posts and mentioned-user-to-tweet links). If the paper counted only one edge type and excluded mention nodes from its node count, that alone would account for a large share of the divergence; the remainder reflects the dataset growing between paper submission and the current HuggingFace release.
Each converted dataset produces two CSV files under a per-dataset subdirectory, named {dataset}_nodes.csv and {dataset}_edges.csv. The remaining eight datasets (Arxiv, the three Amazon variants, and the four Goodreads genres) pass through the same pipeline.
Converted TEG datasets viewed in gdotv after Neptune bulk load.
Code and Data
Four of the TEG-DB datasets used across this series have been converted to Neptune-compatible CSV files and uploaded to S3, where they are staged and ready for direct bulk import. The S3 paths and bucket configuration are linked below.
Arxiv:https://neptune-graph-import.s3.eu-west-2.amazonaws.com/datasets/arxiv/arxiv_edges.csvhttps://neptune-graph-import.s3.eu-west-2.amazonaws.com/datasets/arxiv/arxiv_nodes.csv
Amazon-Apps:https://neptune-graph-import.s3.eu-west-2.amazonaws.com/datasets/amazon-apps/amazon_apps_edges.csvhttps://neptune-graph-import.s3.eu-west-2.amazonaws.com/datasets/amazon-apps/amazon_apps_nodes.csv
Reddit:https://neptune-graph-import.s3.eu-west-2.amazonaws.com/datasets/reddit/reddit_edges.csvhttps://neptune-graph-import.s3.eu-west-2.amazonaws.com/datasets/reddit/reddit_nodes.csv
Goodreads-children:https://neptune-graph-import.s3.eu-west-2.amazonaws.com/datasets/goodreads-children/goodreads_children_edges.csvhttps://neptune-graph-import.s3.eu-west-2.amazonaws.com/datasets/goodreads-children/goodreads_children_nodes.csv
You can turn these into S3 URIs by replacing https://neptune-graph-import.s3.eu-west-2.amazonaws.com/ with s3://neptune-graph-import/
The code for acquiring the datasets from HuggingFace and for the PKL-to-CSV transformation pipeline described in Part 1 is available in the accompanying repository: https://github.com/gdotv/tutorial-teg-db
What Comes Next
Part 2 turns to the Neptune Bulk Loader, which proved more reliable at scale: it walks through the full load configuration, IAM setup, and verifying the loaded graph. Part 3 runs four queries in gdotv that make the central argument for edge text concrete: sentiment polarity, citation chains, and contradictions invisible to graph topology alone. Part 4 steps back from the engineering to offer a critical reading of the benchmark itself, examining what the design choices enable and what they preclude.
References
[1] Li, Z., Gou, Z., Zhang, X., Liu, Z., Li, S., Hu, Y., Ling, C., Zhang, Z., & Zhao, L. (2024). TEG-DB: A Comprehensive Dataset and Benchmark of Textual-Edge Graphs. arXiv preprint arXiv:2406.10310. NeurIPS 2024 Datasets and Benchmarks Track.


