Building a Property Graph Pipeline from the TEG Benchmark: Part 4 – A Critical Examination of Text-Enriched Graphs

Critical Analysis, Where TEG-DB Falls Short
The preceding queries, described in Part 3, represent the benchmark at its strongest: cases where edge text reveals structure that graph topology cannot encode and where the value of the TEG-DB contribution is genuinely demonstrable. The following analysis addresses a different register of questions, not what the benchmark enables in ideal conditions, but where its design choices undermine the claims made in the accompanying paper, and where its limitations constrain the range of downstream use cases it can support. Seven concerns are raised below, ordered roughly from the most immediate to the most structural. These observations are derived directly from the data itself: word frequency analysis, edge text length distributions, empty-text rates, co-citation counts, and node text inspection across the ten datasets as loaded into AWS Neptune. None of the seven points appear in the TEG-DB paper’s own limitations discussion [1], which addresses only computational cost, nor were they raised during the paper’s peer review on OpenReview [2]. The reviewers focused primarily on experimental methodology (additional baselines, evaluation metrics, clearer writing) rather than interrogating the quality and nature of the underlying data. The critique that follows is therefore empirical rather than speculative: each claim is grounded in a specific query or measurement against the dataset, and the queries themselves are provided so that the reader can reproduce the findings.
Edge Text Homogeneity and Low Semantic Entropy
The benchmark’s most celebrated property, the presence of text on every edge, turns out to be unevenly meaningful across datasets. In the Goodreads and Amazon datasets, edge texts are user reviews. These texts are often generic, formulaic, and informationally sparse as relational descriptors. Sentences such as “Great book!”, “Fast shipping”, or “Would recommend to a friend” appear with high frequency and carry virtually no discriminative signal about the nature of the user-book or user-product relationship.
This contrasts sharply with the citation context edges in the Arxiv dataset, where edge texts frequently contain relational phrases (“contradicts,” “extends,” “was the first to show,” “provides the theoretical justification for”) that are specifically and uniquely about the relationship between the citing and cited paper. The vocabulary of citation contexts is relational vocabulary. The vocabulary of consumer reviews is largely evaluative vocabulary about a product, not about a relationship.
A word frequency analysis across 2,000 randomly sampled edge texts from each dataset makes this divergence concrete. The most frequent non-stopword terms in the Goodreads Children edge texts are “book” (1,978 occurrences), “story” (909), “read” (832), “love” (415), “great” (374), “really” (354), and “kids” (332). These are evaluative and product-referential terms. The corresponding list for the Arxiv edge texts reads “learning” (226), “network” (200), “model” (194), “proposed” (153), “neural” (152), and “methods” (131). These are domain-specific and methodological terms. Neither vocabulary is relational in the strict sense, but the Arxiv vocabulary at least operates at the level of intellectual contribution (“proposed,” “methods,” “approaches”), while the Goodreads vocabulary operates at the level of consumer sentiment (“love,” “great,” “fun”).
The homogeneity problem becomes even starker when examined at the level of individual papers. The Adam optimizer paper (“Adam: A Method for Stochastic Optimization”), which is the most cited vertex in the Arxiv graph with 13,155 incoming CITES edges, provides a case study. Of its 9,448 edges that carry non-empty citation text, 95% contain either the word “adam” or a variant of “optimizer.” The five most common opening phrases are nearly identical: “We use the Adam optimizer (Kingma and Ba, …)” accounts for 56 edges on its own, and minor variations of the same sentence (“We used the Adam optimizer,” “We use Adam optimizer”) account for dozens more. These 9,448 citation sentences encode, in effect, a single piece of information repeated nine thousand times: the citing paper used Adam for training. A model that receives this edge text as input for link prediction or node classification gains almost nothing from it, because the text carries no discriminative signal about the relationship between the citing and cited paper. The following query retrieves a sample of these edges for inspection in gdotv:
MATCH (p:Paper)-[c:CITES]->(adam:Paper)
WHERE adam.`~id` = 'arxiv_1353'
RETURN p, c, adam
LIMIT 10
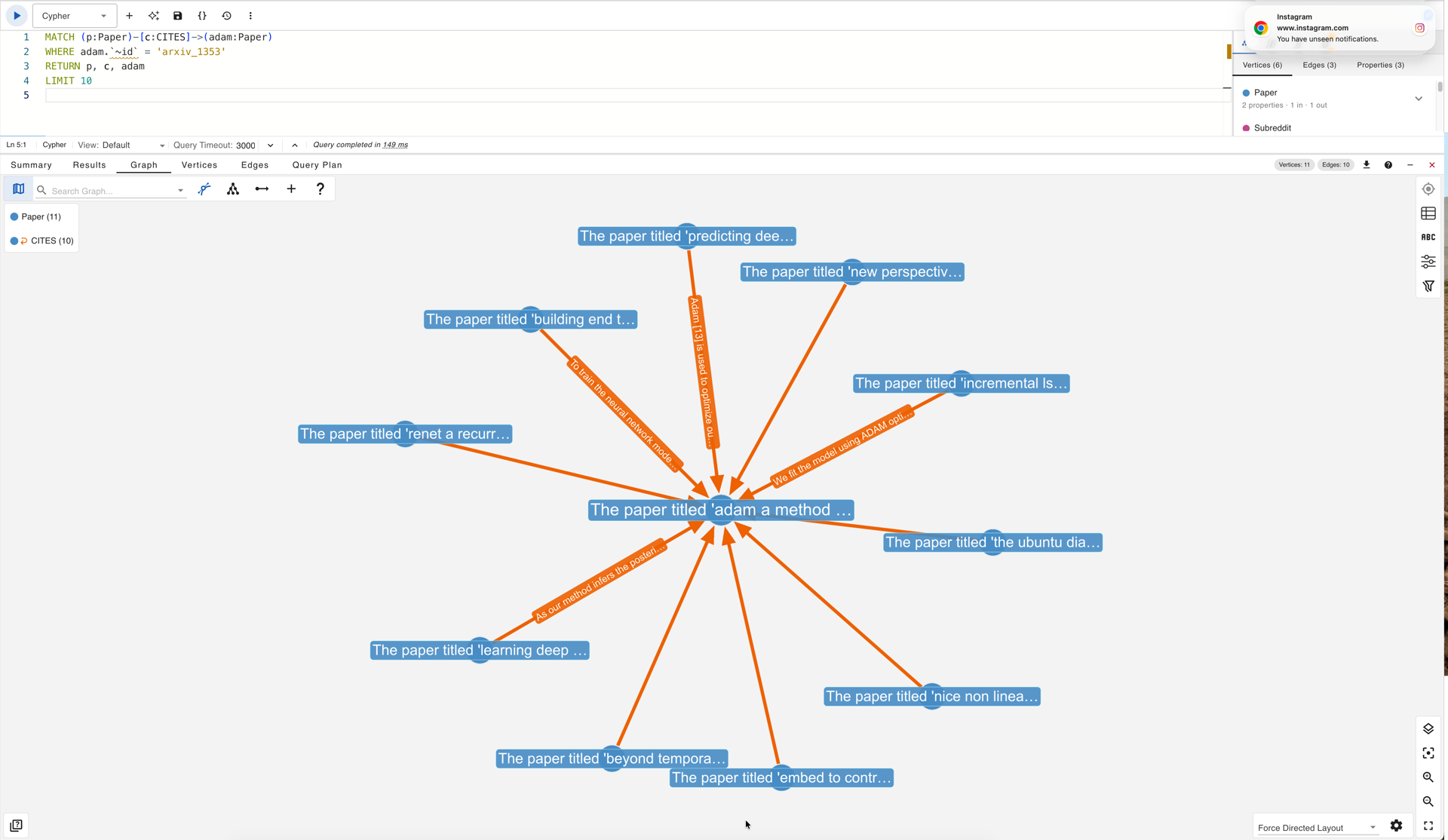
Incoming CITES edges on the Adam optimizer paper (arxiv_1353) in gdotv
The practical consequence of this homogeneity is that a model trained to exploit edge text on the Arxiv dataset is unlikely to have learned anything that transfers to the Goodreads dataset, and vice versa. The benchmark presents itself as a unified test bed for text-enriched graph methods, but the qualitative nature of the edge text is so different across domains that “edge text” is arguably a label applied to structurally different phenomena.
Edge Text as Displaced Node Text
The preceding observation leads to a more fundamental structural critique. In a recommendation graph, the edge from a user vertex to a book vertex carries a review of the book. That review describes the book, its prose quality, its plot coherence, its emotional impact. It does not describe the relationship between the user and the book except in the most indirect sense. The semantic content of the edge is about the destination vertex, not about the connection between the two vertices.
This is not a subtle distinction. If one were to detach the review texts from the edges and reattach them as additional textual properties on the book vertices (averaging or concatenating across all reviews of a given book) the information content of the graph would be essentially unchanged. The graph would still encode who reviewed what, and the book’s accumulated review text would still be accessible. What would be lost is the attribution of each review to a specific user, which is preserved in the graph topology regardless.
To observe this directly, the following query retrieves a Book vertex with ten of its review edges in the Goodreads Children graph:
MATCH (u:User)-[r:REVIEWED]->(b:Book)
WHERE b.`~id` = 'goodreads_children_71'
RETURN u, r, b
LIMIT 10
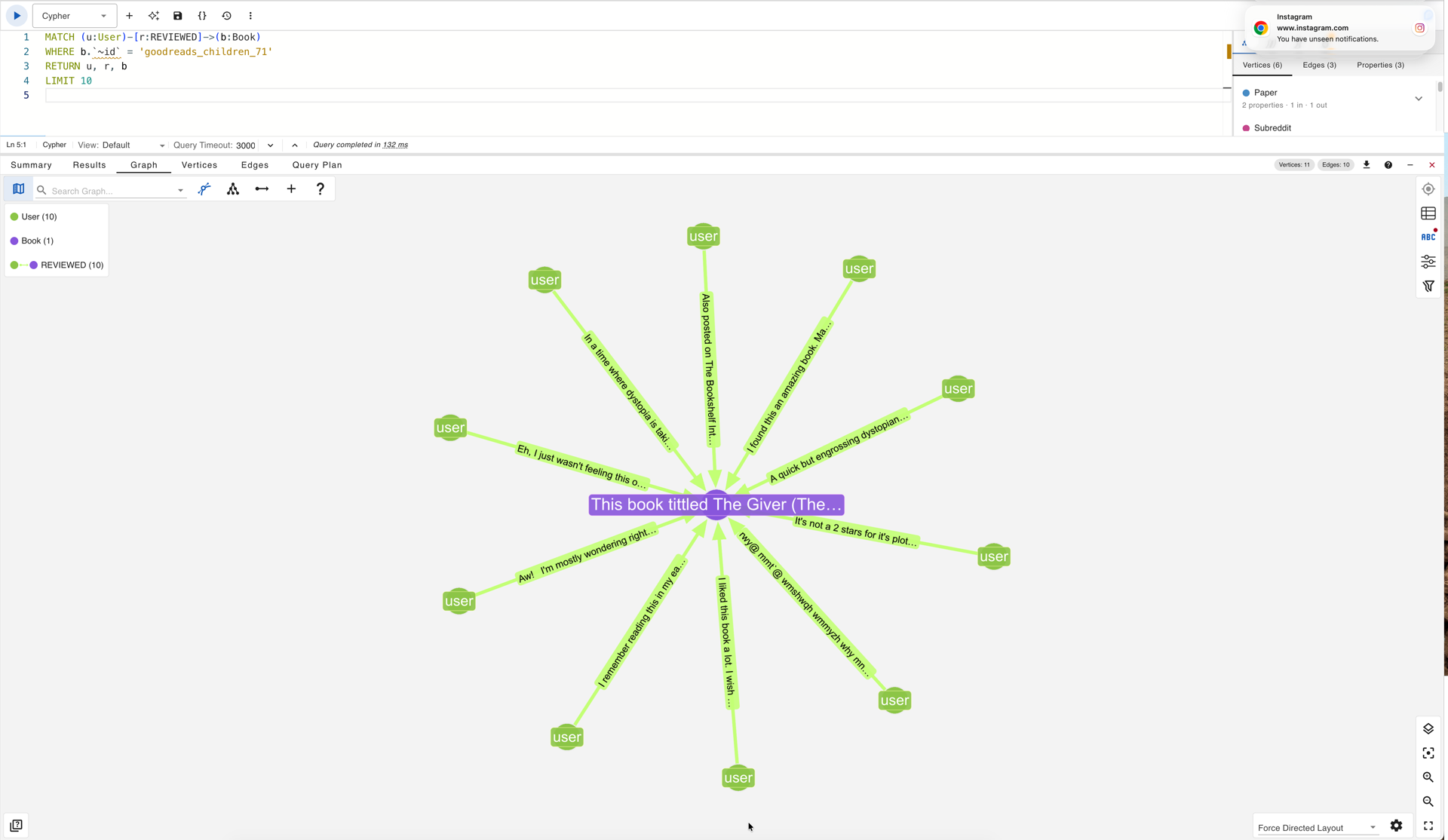
Ten REVIEWED edges on goodreads_children_71 (The Giver) in gdotv
In gdotv, displaying the edge text on each REVIEWED edge reveals that every review describes The Giver itself: its plot, its emotional impact, its prose quality. None of the review texts describe the reviewer’s relationship to the book in any way that could not equally well be stored as a property on the Book vertex. The reviewer’s identity is preserved by the graph structure (the edge connects a specific User to a specific Book), but the text on that edge is about the book, not about the connection.
The contrast with the Arxiv citation graph is again instructive. A citation context sentence is specifically about the act of citing: it is the sentence in which Paper A invokes Paper B to support a particular claim. That text cannot be moved to Paper B without losing the citing paper’s perspective entirely. The semantics are inherently relational. For eight of the ten TEG-DB datasets, this property does not hold.
Absence of Edge Text Quality Validation
The TEG-DB paper does not include any human annotation study, automated consistency check, or semantic relevance evaluation on the edge texts. Three dimensions of quality are left unmeasured: factual accuracy, semantic relevance to the annotated edge, and textual uniqueness.
Factual accuracy is a concern primarily in the Reddit and Twitter datasets, where edge text is drawn from social media posts that may contain misinformation, sarcasm, or deliberate provocation. Semantic relevance is a concern across all review datasets, where a review may discuss a product’s packaging when the edge connects a user to a software application. Textual uniqueness is a concern in the Amazon datasets, where sellers sometimes seed their products with near-duplicate reviews, and where users may submit nearly identical reviews to multiple products.
A basic quality audit across five datasets reveals significant structural variation in edge text completeness and length:
| Dataset | Total Edges | Empty Text | Empty % | Avg Length (chars) | Median Length (chars) |
|---|---|---|---|---|---|
| Arxiv | 1,166,243 | 362,059 | 31.0% | 188 | 168 |
| 942,063 | 0 | 0.0% | 166 | 84 | |
| 150,000 | 0 | 0.0% | 91 | 88 | |
| Goodreads Children | 734,640 | 158 | 0.0% | 422 | 215 |
| Amazon Apps | 752,937 | 0 | 0.0% | 374 | 305 |
The Arxiv dataset stands out for its high empty-text rate: nearly one in three citation edges carries no text at all. These are edges where the citation context extraction pipeline failed to recover a sentence, leaving the edge structurally present but textually hollow. A model that treats edge text as a reliable signal will encounter a 31% missing-data rate on this dataset alone, and the benchmark does not flag or account for this gap. The Reddit dataset has no missing text, but 3.1% of its edges are shorter than 20 characters, a threshold below which most text carries negligible semantic content. The Amazon Apps dataset, by contrast, has no empty edges and no edges under 20 characters, making it the most consistently populated of the five. The following query samples edges from any dataset and allows visual inspection of text quality in gdotv:
MATCH (a:Paper)-[e:CITES]->(b:Paper)
WHERE e.text IS NULL
RETURN a, e, b
LIMIT 5
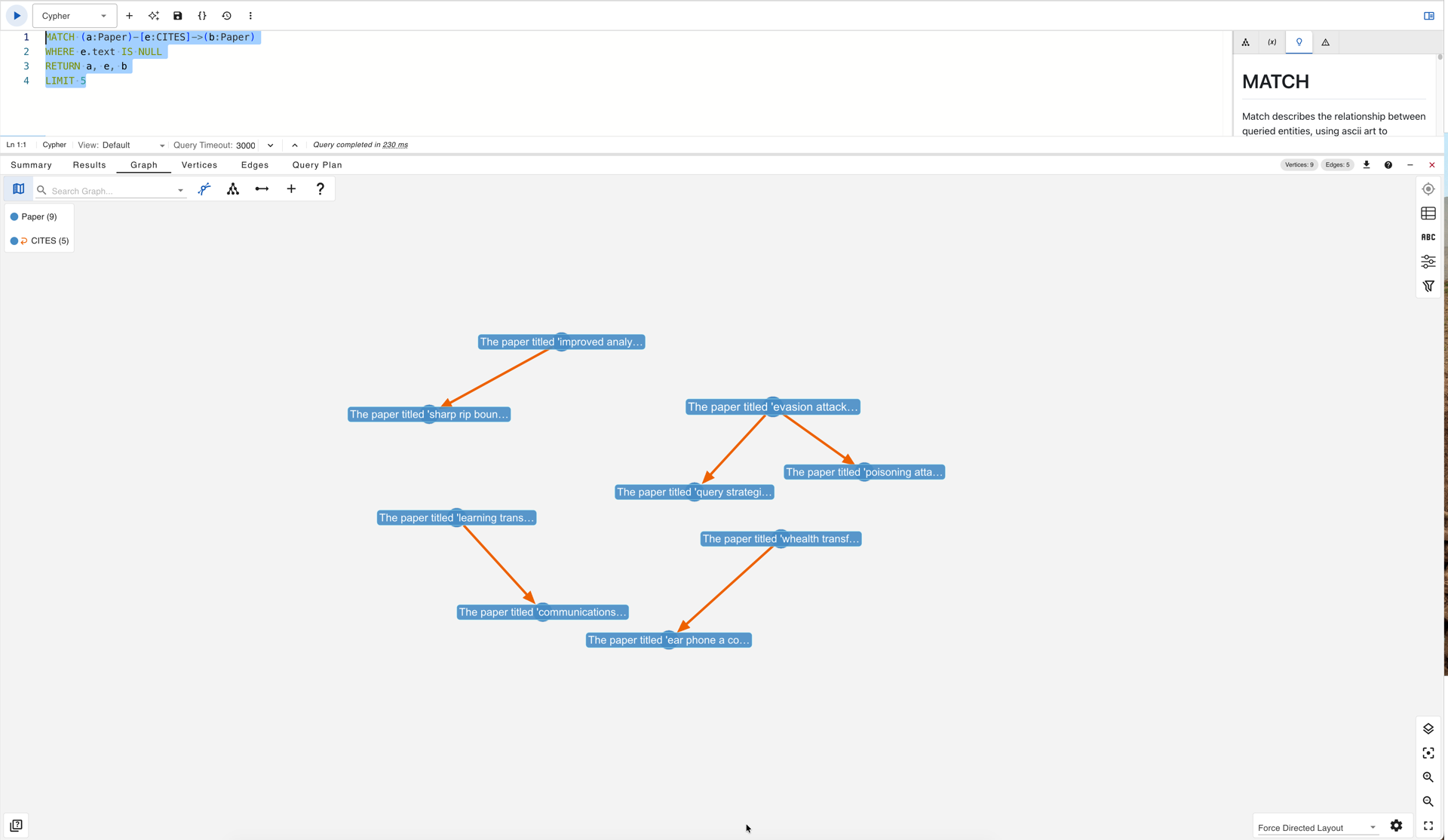
CITES edges with null text in gdotv
Asymmetric Task Coverage, Edge Text Used Only as a Feature, Never as a Target
The benchmark evaluates models on two tasks: link prediction and node classification. Neither task requires a model to produce, retrieve, or directly reason about edge text. In link prediction, the model predicts whether an edge exists; edge text is available as input but the output is a binary decision. In node classification, the model predicts a vertex label; edge text is again a potential input feature, but not the target.
The consequence is that a model could achieve competitive benchmark scores by learning to ignore edge text entirely and relying on the graph topology and node features alone. Whether models actually exploit edge text, and to what degree, is an empirical question the benchmark does not answer by design. The paper reports ablation results showing modest performance drops when edge text is removed, but the magnitude of these drops does not constitute strong evidence that the models have acquired genuinely relational understanding of the edge text.
The following matrix summarises the gap between what TEG-DB evaluates and what a complete textual-edge benchmark would need to cover:
| Link Prediction / Node Classification | Edge Text Retrieval / Generation | |
|---|---|---|
| Topology only | Baseline (benchmarked) | Not applicable |
| Topology + Edge Text | TEG-DB evaluated | Not evaluated (critical gap) |
The critical gap is in the bottom-right cell. A benchmark that purports to test text-enriched graph understanding but includes no task that requires text understanding is, in a strict sense, not testing what it claims to test. The DTGB benchmark [3] includes edge text retrieval as a task, filling exactly this gap and providing a reference design for future work.
This is the benchmark’s most consequential design limitation. A well-motivated benchmark for textual edge understanding would include at least one task in which removing the edge text renders the task unsolvable, for instance, retrieving the edge text given only the two endpoints, or predicting the sentiment of a review given the reviewer’s history and the book’s properties but not the review itself. Neither task appears in TEG-DB.
Temporal and Contextual Flattening
In the Arxiv citation graph, citation contexts are extracted sentences, but an academic paper can cite another paper in multiple locations with different purposes: once in the introduction to establish lineage, once in the related work section to draw a contrast, once in the methodology to justify a technical choice. TEG-DB flattens this multiplicity to a single edge text per pair of papers. When a paper pair has multiple citations in different contexts, the multi-edge nature is collapsed, and the extracted sentence is likely the first one encountered during processing.
This flattening is not merely a data engineering convenience. It introduces a systematic misrepresentation of the citation graph’s structure. Two papers that have a complex, multi-dimensional intellectual relationship are represented as a single directed edge with a single short sentence, which may capture only one facet of that relationship and may be the least informative of the available sentences.
The severity of this flattening can be estimated by examining co-citation patterns. Two papers that are frequently cited together by the same third-party papers are likely to have a rich, multi-faceted intellectual relationship, yet TEG-DB represents each such pair with at most one directed edge and one citation sentence. The following query retrieves the neighbourhood of two heavily co-cited papers, VGGNet and ResNet, whose shared citation count (4,789 papers cite both) suggests a deep and varied intellectual connection:
MATCH (a:Paper)-[e:CITES]->(b:Paper)
WHERE (a.`~id` = 'arxiv_67166' AND b.`~id` = 'arxiv_25208')
OR (a.`~id` = 'arxiv_25208' AND b.`~id` = 'arxiv_67166')
RETURN a, e, b
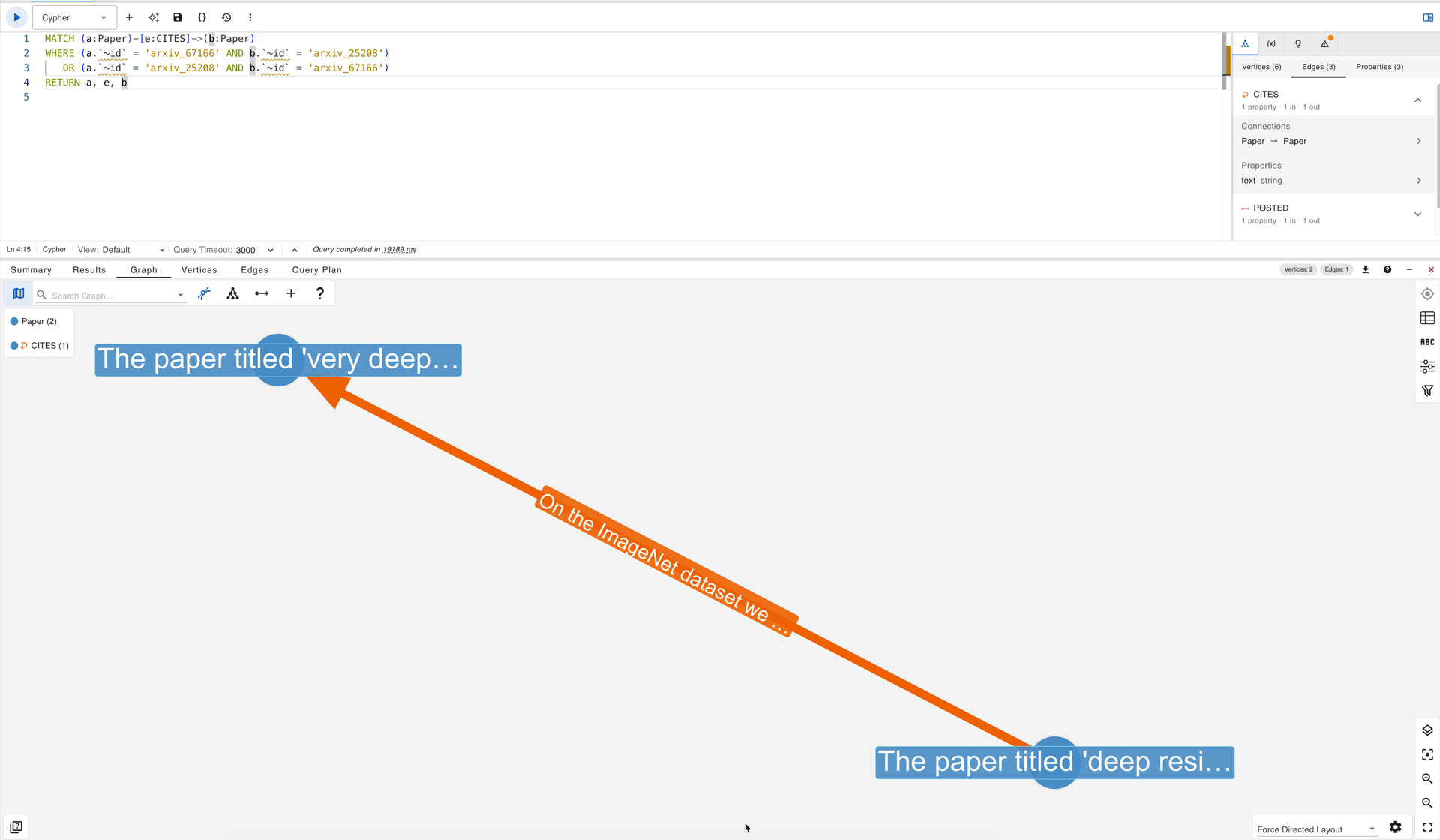
The single direct CITES edge between VGGNet (arxiv_67166) and ResNet (arxiv_25208) in gdotv
The query returns exactly one edge. Its citation text reads: “On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers, 8x deeper than VGG nets but still having lower complexity.” This single sentence captures one dimension of the relationship (a depth-and-complexity comparison), but omits the architectural lineage, the shared reliance on batch normalisation, and the numerous papers that use both as backbone feature extractors. The table below shows the most heavily co-cited paper pairs among the top 20 most-cited papers in the Arxiv graph, along with the number of direct edges that TEG-DB provides for each pair:
| Paper A | Paper B | Co-citing Papers | Direct Edges in TEG |
|---|---|---|---|
| VGGNet | ResNet | 4,789 | 1 |
| Adam | ResNet | 3,452 | 0 |
| ResNet | BatchNorm | 2,429 | 1 |
| GoogLeNet | ResNet | 2,353 | 1 |
| GoogLeNet | VGGNet | 2,295 | 1 |
| ResNet | ImageNet | 2,290 | 1 |
| Faster R-CNN | ResNet | 2,151 | 1 |
| Adam | VGGNet | 2,118 | 0 |
| Bahdanau Attention | Seq2Seq | 1,528 | 1 |
Adam and ResNet are co-cited by 3,452 papers, yet have zero direct edges between them in the TEG graph, meaning the benchmark contains no textual record of their relationship at all. Adam and VGGNet (2,118 co-citations, zero edges) present the same gap. For the pairs that do have a single edge, a relationship that 4,789 third-party papers considered worth mentioning is compressed to a single sentence. Temporal graph benchmarks such as DTGB approach this problem differently through timestamped multi-edges, allowing the same pair of nodes to carry multiple edges with distinct texts and timestamps.
Social Network Edge Text as Conversational Noise
The Reddit and Twitter datasets occupy a qualitatively different position in the benchmark from the review and citation datasets. Their edge texts are social media posts and replies, often extremely short, heavily context-dependent, frequently referential to external content such as URLs, images, or memes that are not captured in the dataset, and inconsistently structured. A reply of “lol” or “this” carries no semantic content that a model can exploit. A reply that consists of “@username agreed” is meaningful only in the context of the thread that precedes it, which the graph structure does not encode.
This creates a situation in which the benchmark label “edge text” encompasses phenomena as different as a carefully extracted citation sentence and a two-character social media reply. Treating them as instances of the same modality in a unified benchmark conflates very different levels of textual richness and informativeness.
The token count distribution (whitespace-delimited) across four datasets quantifies this divergence:
| Dataset | P5 | P25 | Median | P75 | P95 |
|---|---|---|---|---|---|
| Arxiv | 10 | 19 | 26 | 37 | 62 |
| 2 | 7 | 15 | 33 | 100 | |
| 5 | 9 | 13 | 18 | 22 | |
| Goodreads Children | 4 | 16 | 39 | 90 | 270 |
The Reddit dataset is the most revealing. Its 5th-percentile edge text contains just 2 tokens, and 20,139 of its 942,063 edges (2.1%) are shorter than 15 characters. Samples from this tail include “Yep,” “Thanks!,” “gtfo giannis,” and “#PICK IS IN,” texts that are intelligible only within the conversational thread from which they were extracted and carry no standalone semantic content. The Twitter dataset is more compact but consistently short: its median edge text is 13 tokens and its 95th percentile is only 22 tokens, leaving little room for relational expression. The Arxiv dataset, by contrast, shows a narrow and consistent distribution (median 26 tokens, P95 of 62), reflecting the relatively uniform structure of citation context sentences. The Goodreads dataset has the highest variance (P5 of 4 tokens, P95 of 270 tokens), encompassing both one-word ratings and multi-paragraph literary essays.
The following query retrieves a sample of short Reddit edges for visual inspection:
MATCH (u:User)-[p:POSTED]->(s:Subreddit)
RETURN u, p, s
LIMIT 15
Fifteen POSTED edges from the Reddit graph in gdotv
Impoverished Node Text in Review Graphs
An additional limitation concerns the asymmetric treatment of node text across datasets. The Arxiv dataset provides rich node text for every vertex: the full title and abstract of each paper. The review-based datasets provide, by contrast, either a minimal placeholder or a templated sentence assembled from metadata fields.
A direct inspection of the node text confirms this. In the Goodreads Children graph, all 92,667 User vertices carry the identical text string “user,” with no individuating information. In the Amazon Apps graph, all 87,271 Reviewer vertices carry the string “reviewer” and all 13,209 Product vertices carry the string “item.” The following query makes this visible:
MATCH (u:User)-[:REVIEWED]->(:Book)
RETURN DISTINCT u.`~id` AS id, u.text AS node_text
LIMIT 5
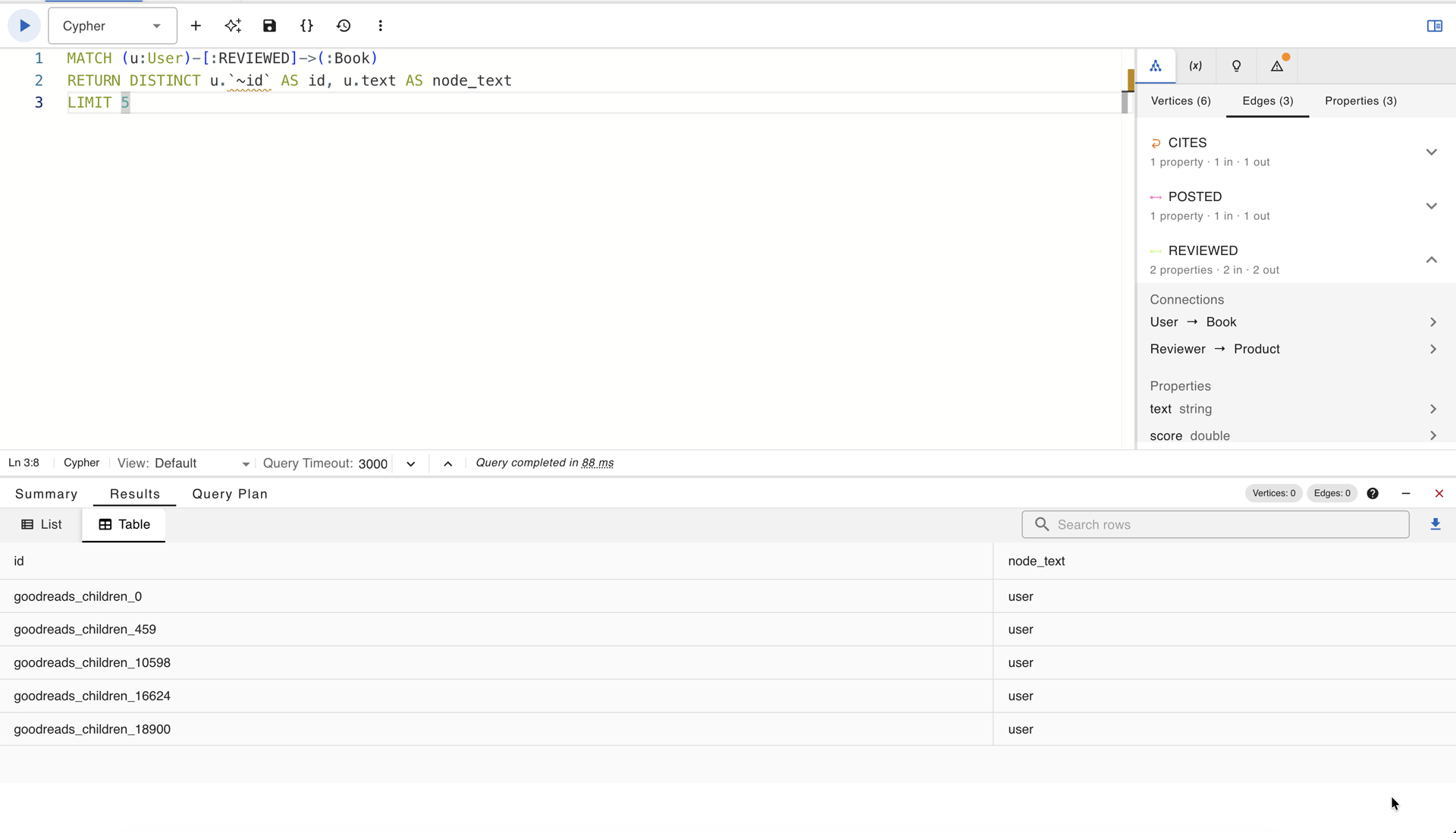
User vertices from the Goodreads Children graph in gdotv: every node text returns the identical string “user”, making all 92,667 User vertices textually indistinguishable from one another.
MATCH (r:Reviewer)
RETURN r.`~id` AS id, r.text AS node_text
LIMIT 5
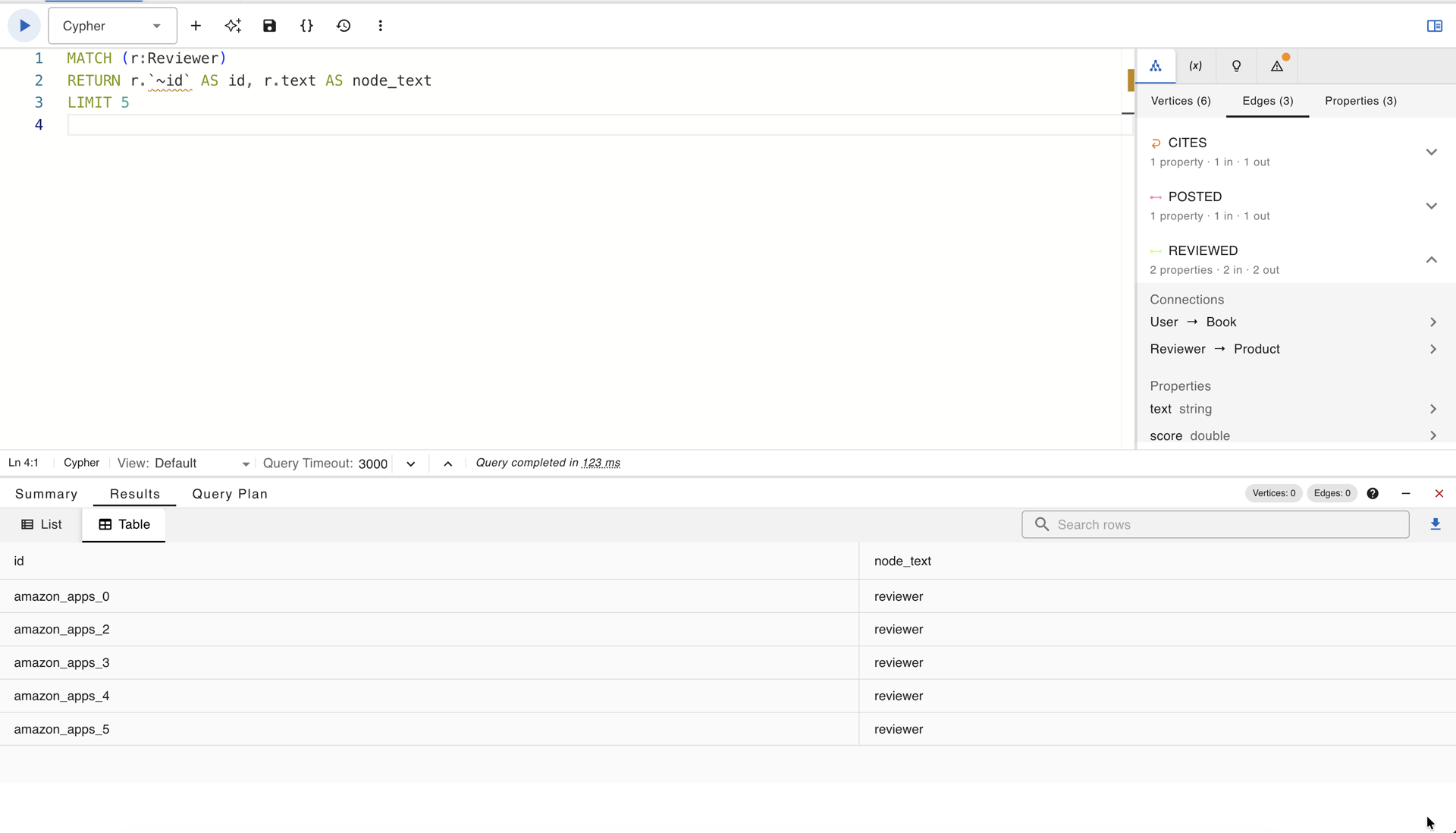
Reviewer vertices from the Amazon Apps graph in gdotv
Every row returns the same string. A “user” node is indistinguishable from any other “user” node by its node text alone, and a “reviewer” node is indistinguishable from any other “reviewer” node. This undercuts the benchmark’s claim to be a text-enriched graph dataset in a holistic sense. For eight of the ten datasets, node text is either vestigial or entirely absent for one class of vertices, and edge text is the only textual signal. The benchmark is therefore more accurately described as an edge-text-enriched graph benchmark, which is a narrower and less general claim than its title suggests.
What Would a Better Textual-Edge Benchmark Look Like?
The limitations raised above concern the data and evaluation design of a benchmark whose core contribution, assembling the first large-scale collection of text-annotated edges across multiple domains, remains both novel and genuinely useful to the community. It provides a genuine service to the community by assembling multiple large-scale text-annotated graphs in a uniform format, and its construction of citation context edges for the Arxiv dataset in particular is a contribution that goes beyond what was previously available. The critique is aimed at the gap between what the benchmark claims to test and what it actually tests, and at the design choices that limit its applicability to downstream use cases beyond link prediction.
A more rigorous benchmark for textual-edge graph understanding would incorporate at minimum the following four properties. First, at least one evaluation task should require edge text to be solved, a task for which removing edge text demonstrably reduces performance to chance. Edge text retrieval, given endpoints and topology, is one such task; edge text generation or completion is another. Second, datasets should be stratified by the relational specificity of their edge text, so that researchers can distinguish progress on truly relational text from progress on node-descriptive text attached to edges. Third, the benchmark should include temporal multi-edges with distinct timestamps and contexts; the treatment in DTGB (Dynamic Text-Attributed Graph Benchmark, 2024) offers a reference design. Fourth, ground-truth ablations (performance with versus without edge text, reported for every model across every dataset) should be a mandatory component of benchmark submission, not an optional supplement.
Summary Assessment by Dataset
The table below provides a synthetic critical assessment of each dataset across five dimensions: the relational specificity of edge text (how well the text describes the relationship rather than the endpoints), the estimated text quality (uniqueness and factual reliability), the task coverage provided for that dataset in the benchmark, the structural noise level, and the faithfulness of the graph representation to the underlying data source. Scores are qualitative and informed by the empirical findings reported in the preceding sections.
| Dataset | Relational Specificity | Text Quality | Task Coverage | Noise Level | Structural Faithfulness |
|---|---|---|---|---|---|
| Arxiv | High | Medium (31% empty) | Moderate | Low | Moderate (flattening) |
| Low | Low (2.1% under 15 chars) | Moderate | High | Moderate | |
| Low | Low (median 13 tokens) | Moderate | High | Moderate | |
| Amazon Apps | Low | Medium (no empty, templated) | Low | Medium | High |
| Amazon Baby | Low | Medium | Low | Medium | High |
| Amazon Movie | Low | Medium | Low | Medium | High |
| Goodreads Children | Low-Medium | Medium (high variance) | Low | Low | High |
| Goodreads Comics | Low-Medium | Medium | Low | Low | High |
| Goodreads Crime | Low-Medium | Medium | Low | Low | High |
| Goodreads History | Low-Medium | Medium | Low | Low | High |
The Arxiv dataset receives the highest relational specificity score but only medium text quality, reflecting its 31% empty-text rate and the severe homogeneity demonstrated by the Adam case study (9,448 edges carrying functionally identical text). The Reddit and Twitter datasets receive the lowest quality scores due to their short-text tails and context-dependent content. The Amazon datasets receive medium quality but low relational specificity: their reviews are consistently present and reasonably long, but they describe products rather than relationships. The Goodreads datasets sit between these extremes, with some reviews exhibiting genuine relational content (as demonstrated by the sentiment polarity showcase in Part 3) but the majority functioning as displaced node text.
Conclusion
The Text-Enriched Graph benchmark represents a meaningful step toward a richer representation of graph-structured knowledge. Its core insight, that relationships like entities can carry language, is correct and important. The Arxiv citation graph, in particular, is a convincing demonstration of what edge text can enable: a queryable, navigable intellectual network in which the reasons for connections are as visible as the connections themselves.
What the benchmark has not yet achieved is a unified, rigorous, and self-consistent test bed for methods that genuinely understand relational language. The review-based datasets, which constitute eight of the ten entries, treat edge text in a way that conflates relational description with node description. The evaluation tasks do not require models to understand edge text in order to succeed. The text quality across social network datasets is too variable and too noise-heavy to support reliable conclusions. And the absence of a multi-edge, temporally ordered representation in the citation graph understates the complexity of the phenomenon the benchmark claims to model.
These are not reasons to set the benchmark aside. They are reasons to use it with clear eyes: to understand what experimental results on TEG-DB do and do not tell us about a model’s ability to reason over text-enriched graphs, and to treat the empirical limitations documented here as the starting point for more targeted evaluation work rather than as a verdict on the benchmark’s usefulness.
References
[1] Li, Z., Gou, Z., Zhang, X., Liu, Z., Li, S., Hu, Y., Ling, C., Zhang, Z., & Zhao, L. (2024). TEG-DB: A Comprehensive Dataset and Benchmark of Textual-Edge Graphs. arXiv:2406.10310. NeurIPS 2024 Datasets and Benchmarks Track.
[2] OpenReview discussion for TEG-DB: peer review thread, Ogw1sSo9FP.
[3] Zhang, J., Chen, J., Yang, M., Feng, A., Liang, S., Shao, J., & Ying, R. (2024). DTGB: A Comprehensive Benchmark for Dynamic Text-Attributed Graphs. arXiv:2406.12072.


