Building a Property Graph Pipeline from the TEG Benchmark: Part 3 – Exploring with gdotv

Introduction
With the bulk load confirmed and gdotv connected to the Neptune cluster (Part 2 covers the full setup), the four loaded datasets are ready to query. This post runs four queries (two in Gremlin, two in openCypher) that each make the same point from a different angle: edge text is not decorative metadata. It encodes relationship semantics that topology alone cannot represent.
Exploring the Graph On gdotv
After ingestion, the Reddit graph contains approximately 478,000 vertices of two types, User and Subreddit, connected by 942,063 directed POSTED edges, each carrying the full text of the original Reddit comment. The Arxiv graph contains 169,343 Paper vertices and 1,166,243 CITES edges, each carrying an extracted citation sentence. The Goodreads children graph contains several hundred thousand User and Book vertices connected by REVIEWED edges with numerical ratings and review text.
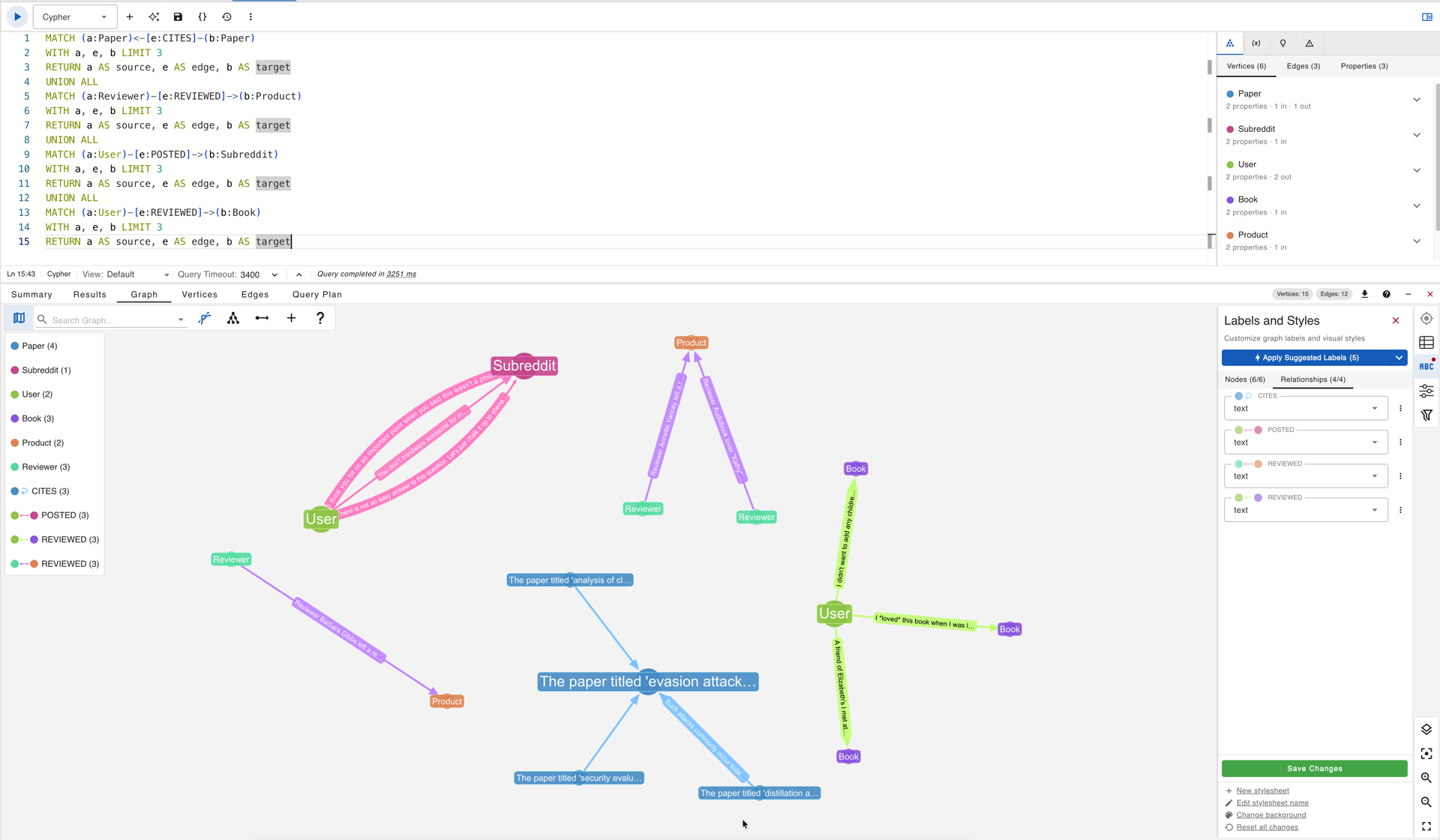
The loaded TEG datasets in gdotv: User, Subreddit, Paper, Book, and Product vertex types visible in the schema panel alongside their respective edge labels.
Showcase Queries: The Cases Where Edge Text Proves Its Value
Query A – Sentiment Polarity Across a Shared Book
The most immediate argument for edge text in a recommendation graph is that two users can hold diametrically opposed opinions about the same book, and that this opposition is invisible in the graph topology but fully legible in the edge text. Both users are connected to the same Book vertex by a REVIEWED edge, and the only difference between them is the content of those edges.
The first query searches the Goodreads Children graph for Book vertices that have accumulated both strongly positive and strongly negative reviews. It is a simple property filter on the score field that returns candidates where the sentiment split is most pronounced.
MATCH (u:User)-[r:REVIEWED]->(b:Book)
WHERE r.score <= 1.0
WITH b, count(r) AS negative
WHERE negative > 10
MATCH (u2:User)-[r2:REVIEWED]->(b)
WHERE r2.score >= 5.0
WITH b, negative, count(r2) AS positive
WHERE positive > 10
RETURN b.`~id` AS book_id, negative, positive
ORDER BY negative DESC
LIMIT 5
The second query selects three one-star and three five-star edges around the chosen book and renders them in gdotv.
MATCH (u:User)-[r:REVIEWED]->(b:Book)
WHERE b.`~id` = '<BOOK_ID>' AND r.score <= 1.0
WITH u, r, b LIMIT 3
RETURN u AS user, r AS review, b AS book
UNION ALL
MATCH (u:User)-[r:REVIEWED]->(b:Book)
WHERE b.`~id` = '<BOOK_ID>' AND r.score >= 5.0
WITH u, r, b LIMIT 3
RETURN u AS user, r AS review, b AS book
gdotv edge filter toggling between score 1 and score 5 REVIEWED edges on the same Book vertex, making the two sentiment clusters visually distinct without altering the underlying graph structure.
The resulting visualisation makes the central claim of this section concrete. Six User vertices surround a single Book vertex, each connected by a REVIEWED edge. The graph structure is perfectly symmetric: six identical directed edges converging on one node. Nothing in the topology distinguishes the reader who found the novel engrossing from the reader who hated every word. The edge text itself carries the signal: one review describes a “quick but engrossing dystopian novel” while another declares “I hated every single word of this book.” In gdotv, the edge filter allows filtering by property values by toggling between edges with a score of 1 and edges with a score of 5 isolates the two sentiment clusters without altering the graph structure, making it visually evident that the same topology conceals diametrically opposed relationships. A graph without edge text would encode these six relationships as interchangeable; the TEG-format graph preserves the full semantic distance between commendation and dismissal within the structure itself.
Query B – Multi-hop Citation Influence Chains
In the Arxiv citation graph, edges carry the sentence from the citing paper that motivated the citation. A sequence of such sentences across a path in the graph describes an intellectual lineage. Three papers can form a chain in which the first paper introduces a concept, the second paper challenges it, and the third paper resolves the dispute. This narrative structure is encoded entirely in the edge texts, invisible to any method that looks only at the topology.
To construct such a chain through a graph query rather than manual inspection, the approach begins by selecting a well-connected landmark paper and exploring its citation edges in both directions. The Bahdanau attention paper, “Neural Machine Translation by Jointly Learning to Align and Translate,” serves as a natural anchor given its position at the intersection of multiple research threads. The first query retrieves its outgoing CITES edges to reveal what the paper itself builds upon:
g.V('arxiv_115359').outE('CITES').limit(10)
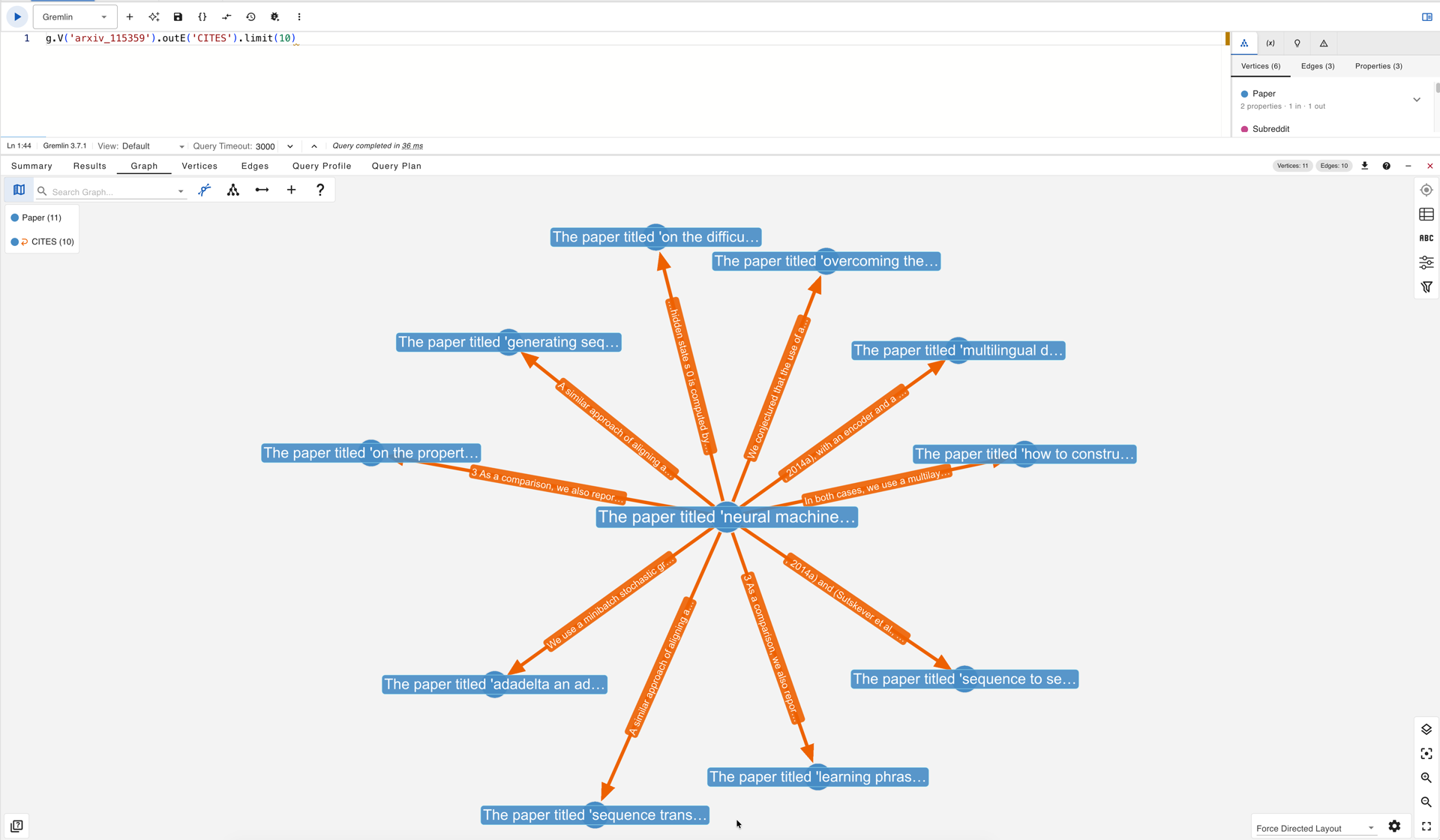
Outgoing CITES edges from the Bahdanau attention paper (arxiv_115359) in gdotv: each edge carries the citation sentence explaining what the paper builds upon.
The second query retrieves its incoming CITES edges to reveal the papers that later drew from it:
g.V('arxiv_115359').inE('CITES').limit(10)
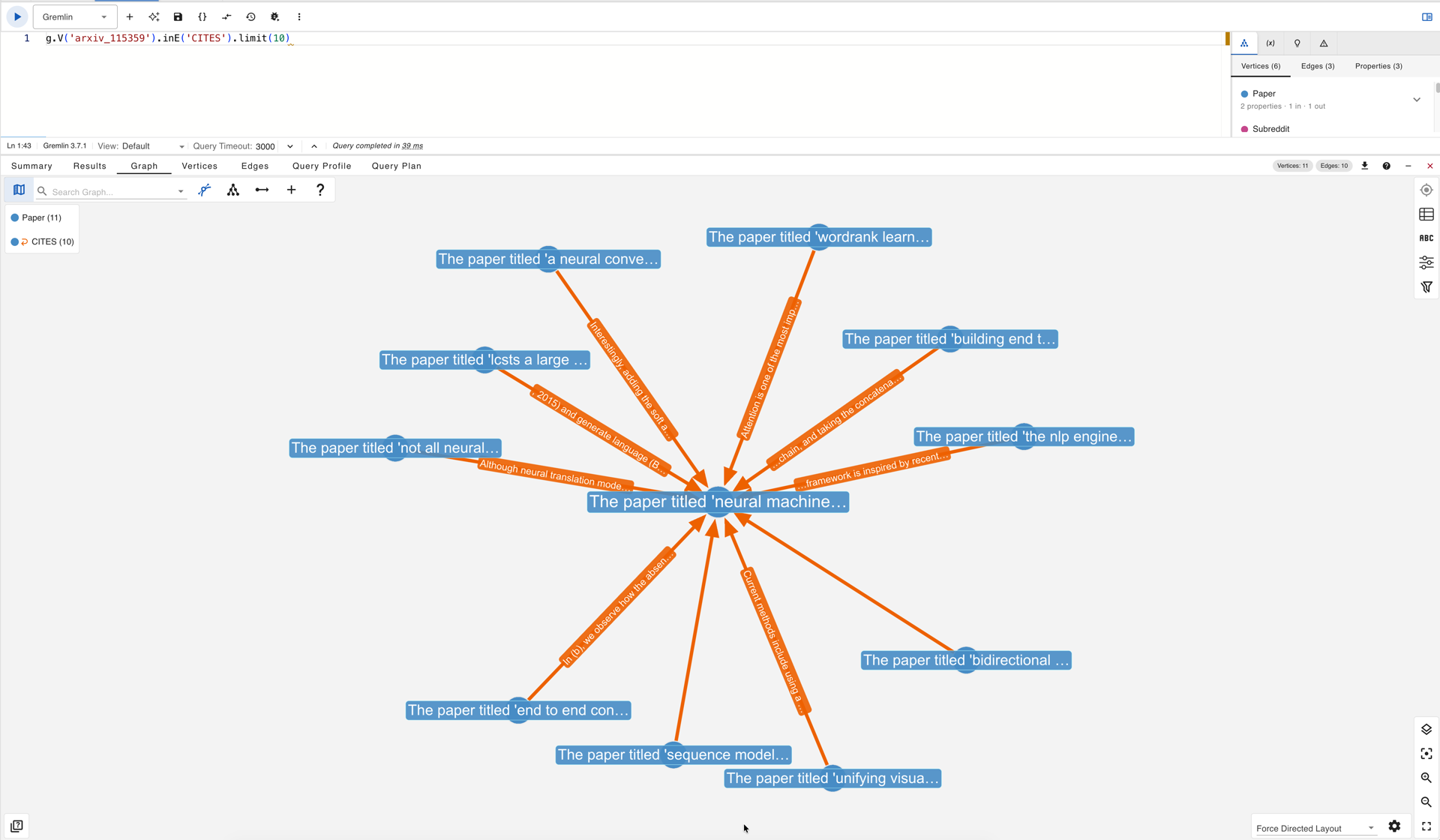
Incoming CITES edges to the Bahdanau attention paper in gdotv: papers that later cited it, each edge carrying the sentence that motivated the citation.
By inspecting the edge text on the results of both queries, a chain becomes visible. One outgoing edge points to the Seq2Seq paper by Sutskever et al. and carries the sentence describing the encoding of “a variable-length source sentence into a fixed-length vector,” the architectural constraint that the attention mechanism was designed to overcome. One incoming edge arrives from a reinforcement learning paper whose citation sentence reads: “Inspired by the recent success of attention mechanisms, we here bias the reinforcement learning’s attention to explore the sequence portions which are difficult to be decoded.” The two edges together trace a three-step intellectual progression. A third query renders this chain as a single subgraph:
g.V('arxiv_115359').bothE('CITES').where(
otherV().hasId(within('arxiv_92772', 'arxiv_154342'))
)
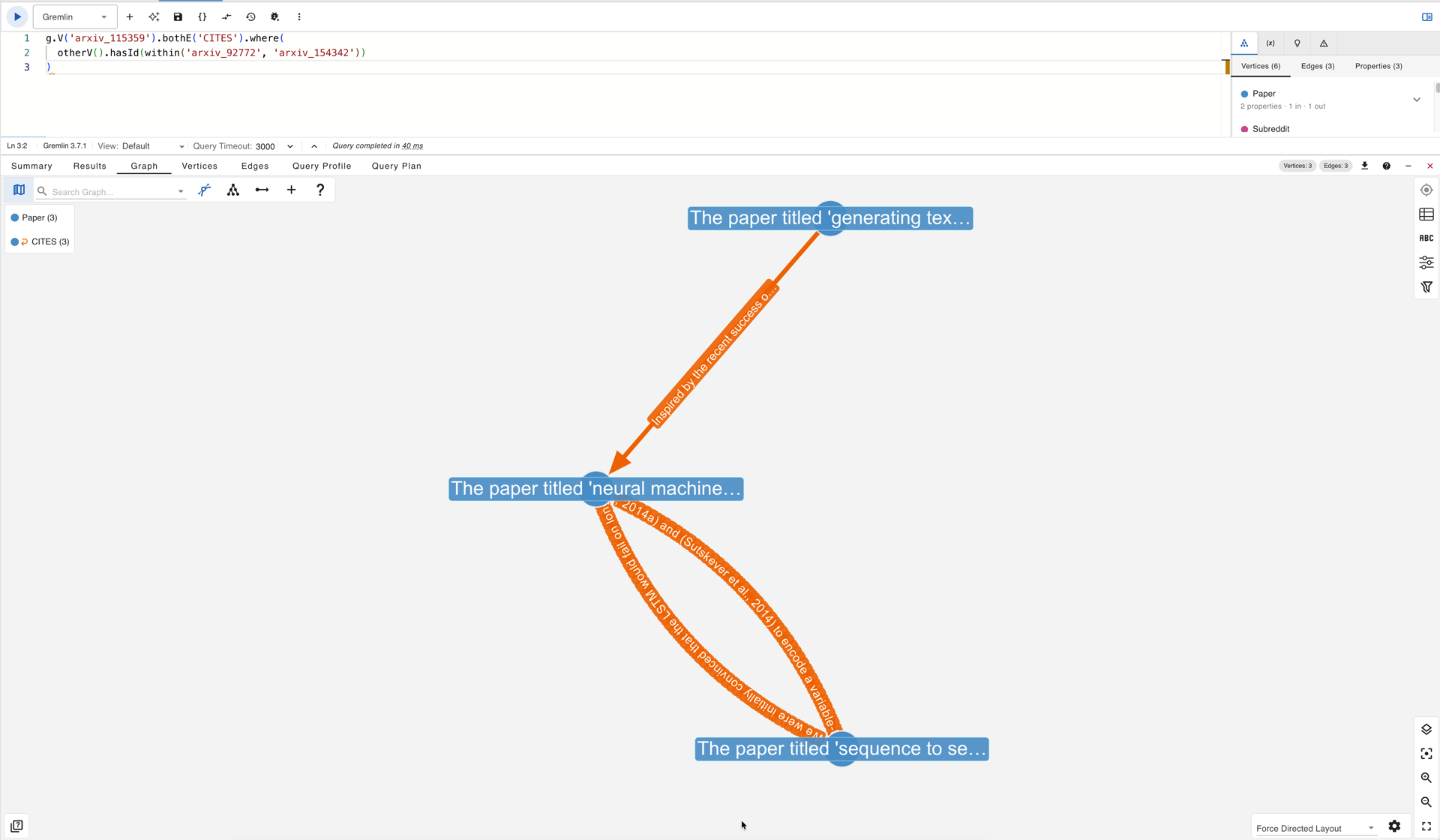
The three-paper citation chain in gdotv: the Bahdanau attention paper (center) connected to the Seq2Seq paper it builds on and the RL paper that later adopted attention, with the citation sentence visible on each CITES edge.
Read from right to left, the edge texts narrate an intellectual lineage: a foundational architecture introduces a fixed-length bottleneck, a second paper addresses that bottleneck through attention, and a third paper carries the attention mechanism into an entirely different domain. None of this progression is visible in the graph topology, where both edges are identical directed CITES links. The narrative lives exclusively in the edge text, and it is recoverable only because the TEG benchmark preserved the citation sentences rather than discarding them in favour of a binary adjacency.
Query C – Relationship Type Discrimination in Amazon
The Amazon review graph is topologically uniform: every edge is a REVIEWED relationship from a Reviewer vertex to a Product vertex. However, the text of those reviews is not uniform. Some reviews describe firsthand product experience; others are written by users who received the product as a gift; others are corrections of prior reviews. Edge text discriminates between these relationship types where graph topology cannot.
To locate a product vertex with enough reviews to show the diversity, the first query ranks products by incoming edge count:
g.V().hasLabel('Product')
.order().by(__.inE('REVIEWED').count(), Order.desc)
.limit(5)
.project('id', 'review_count')
.by(id())
.by(__.inE('REVIEWED').count())
The top result carries over six thousand REVIEWED edges:
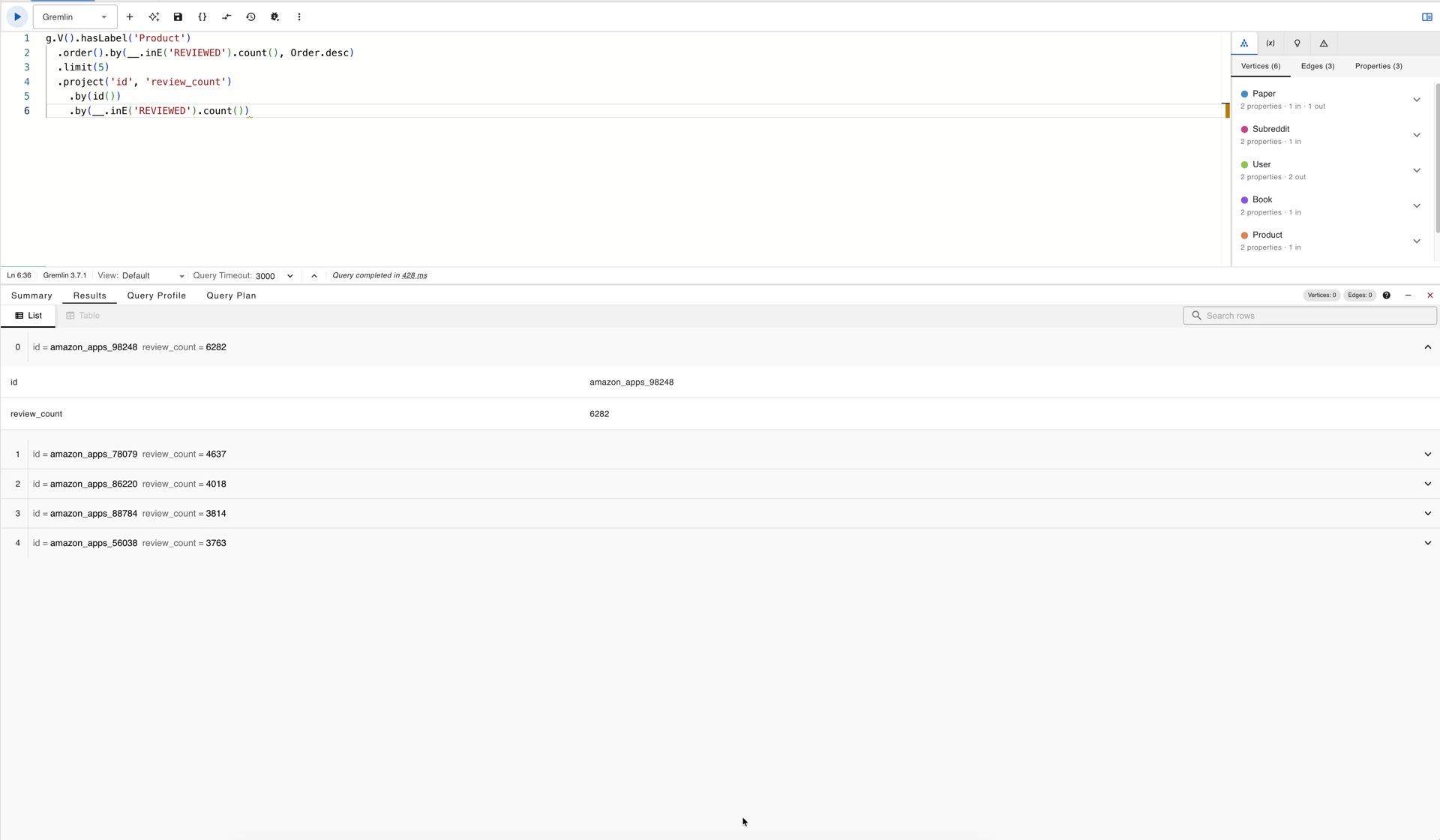
Gremlin query results in gdotv listing the top five Amazon Product vertices by incoming REVIEWED edge count; amazon_apps_98248 leads with 6,282 reviews and is selected as the target for the next query.
Now in the second query, we retrieve a sample of those edges and their source vertices for the top ranked amazon_apps_98248:
g.V('amazon_apps_98248').inE('REVIEWED').limit(12)
gdotv graph view of amazon_apps_98248 (Candy Crush Saga) with twelve Reviewer vertices: topologically identical REVIEWED edges, edge text revealing distinct review categories from firsthand usage accounts to business-model criticism.
The resulting graph shows a single Product vertex with most reviews, amazon_apps_98248 (Candy Crush Saga, identifiable from the review content) at the centre surrounded by twelve Reviewer vertices, each connected by a REVIEWED edge. Topologically, the twelve edges are identical: same label, same direction, same structural role. Yet the edge texts reveal at least four distinct categories of review. In gdotv, the edge text can be displayed alongside the numerical score using the template string creator, which allows combining multiple edge properties into a single label. With this configuration, the variety across reviews becomes immediately legible: some edges carry detailed firsthand accounts of product usage, others focus on business model criticism, others report secondhand experience, and others raise concerns unrelated to the product itself. A graph topology that encodes all of these relationships as interchangeable REVIEWED edges collapses that variety into a single undifferentiated link. The edge text is the only structure that preserves these differences, and it is the only structure from which a downstream model could, in principle, learn to distinguish them.
Query D – Contradiction Detection Across Edges
If two edges connecting the same pair of vertices carry texts that contradict each other (or if two edges from different users to the same product carry texts that contradict each other in stance) this constitutes a form of knowledge conflict that standard graph models cannot represent. TEG-DB makes such conflicts queryable.
The approach begins by locating a book with a large number of reviews, increasing the likelihood that the edge texts will contain directly opposing claims. The first query ranks Book vertices by incoming edge count:
MATCH (u:User)-[r:REVIEWED]->(b:Book)
WITH b, count(r) AS review_count
ORDER BY review_count DESC
LIMIT 5
RETURN b.`~id` AS id, review_count
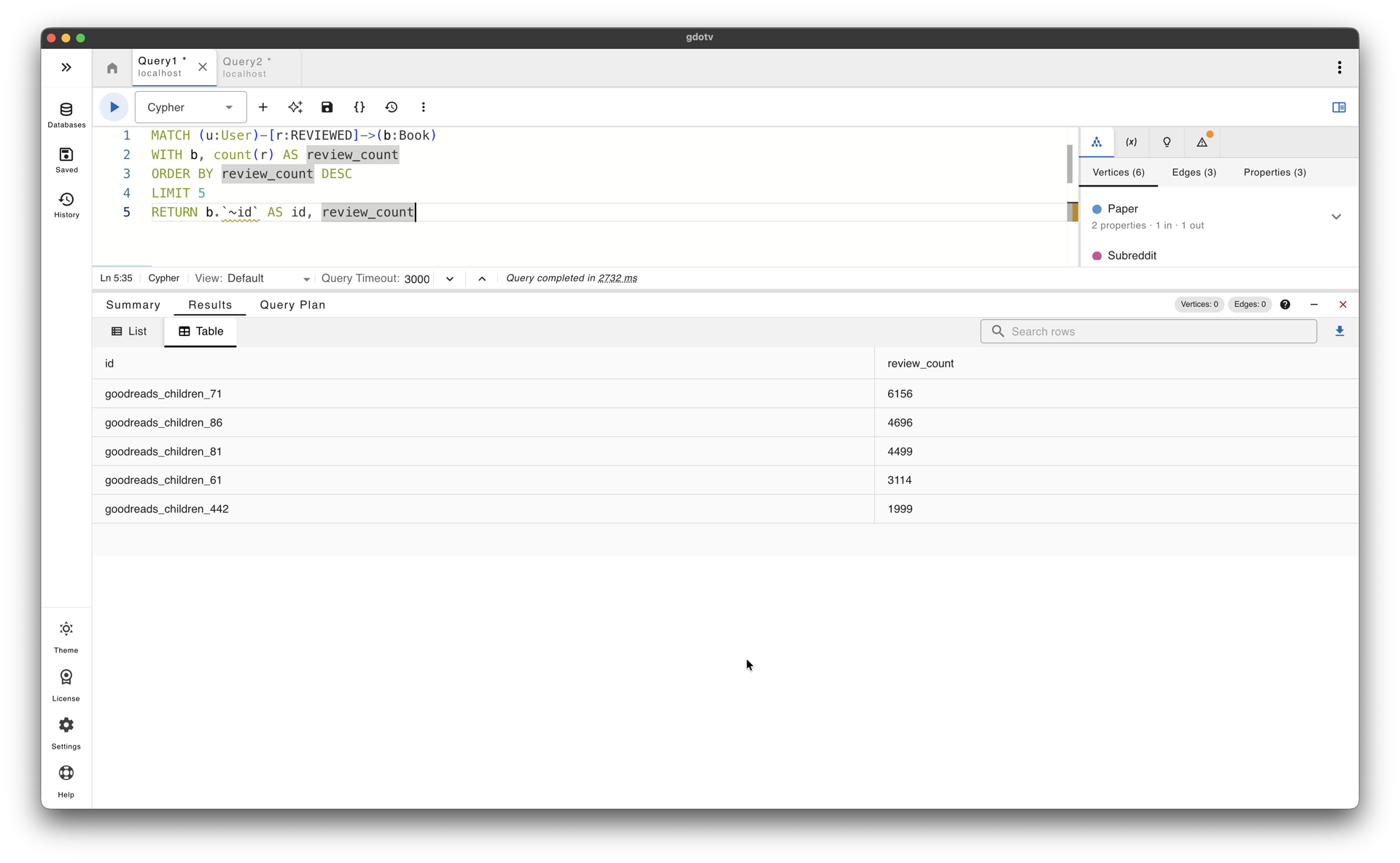
Top five Goodreads Children Book vertices by incoming REVIEWED edge count in gdotv; goodreads_children_86 with 4,696 reviews is selected as the target for the contradiction query.
From the results, we select a book with several hundred reviews. The second query retrieves edges at both extremes of the score range, where contradictions are most likely to surface:
MATCH (u:User)-[r:REVIEWED]->(b:Book)
WHERE b.`~id` = 'goodreads_children_86'
AND (r.score <= 1.0 OR r.score >= 5.0)
RETURN u, r, b
LIMIT 12
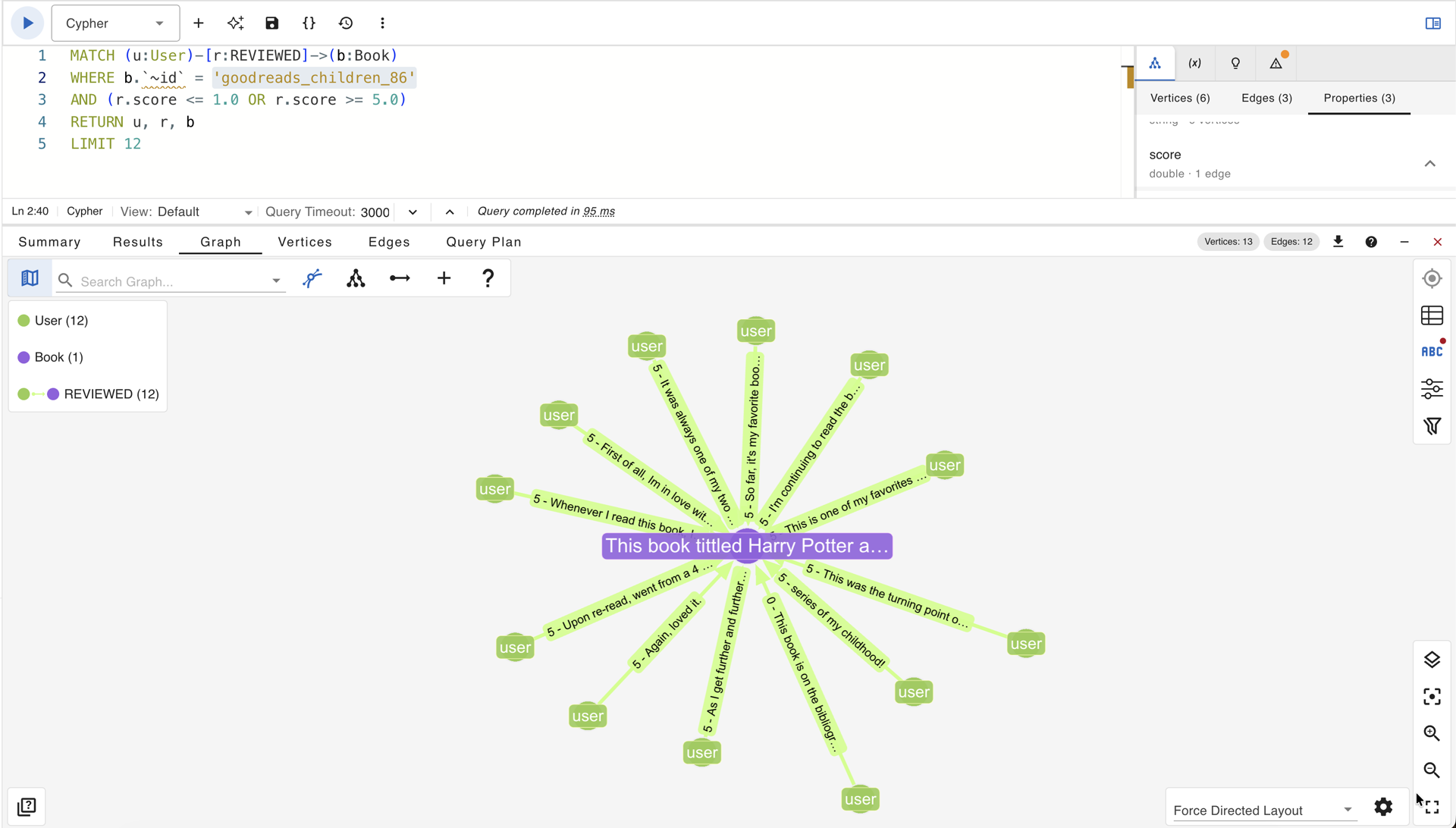
gdotv graph of goodreads_children_86 (Harry Potter) with 12 User vertices connected by REVIEWED edges at score extremes; the edge text makes the contradiction between commendation and dismissal legible without leaving the graph view.
The resulting graph shows a single Book vertex surrounded by User vertices whose edges carry scores of either 5 or 0 and 1. Topologically, the structure is again a uniform star: every edge is a REVIEWED relationship pointing at the same node. In gdotv, the edge text can be displayed using the template string creator to combine the score and the review content into a single label, making the contradictions visible without switching between property panels.
These are not subtle differences in emphasis. They are direct contradictions in stance, attached to the same vertex, encoded in edges that the graph topology treats as interchangeable. No structural analysis of the graph, however sophisticated, can recover the fact that one edge expresses enthusiasm and another expresses frustration, because that distinction exists only in the text. This is the strongest version of the argument for edge text in recommendation graphs: not merely that it adds information, but that it encodes a form of knowledge conflict that is structurally invisible without it.
Whether downstream models trained on the TEG benchmark actually learn to detect and exploit such conflicts is a separate question, and one that Part 4 addresses in its discussion of the benchmark’s task coverage.
What Comes Next
The four queries above represent the strongest case for edge text in a property graph: scenarios where the text on a relationship is the only structure that separates diametrically opposed relationships. The next installment steps back from these showcase examples to ask harder questions about the benchmark itself.
Part 4 covers the critical analysis of TEG-DB: what the design choices actually enable, and what they preclude. The central issue is semantic entropy. The review-heavy datasets (Amazon and Goodreads) contain millions of edges whose text is largely formulaic, high in length but low in discriminative signal. A star rating of 5 and a three-sentence review that says “my kid loved it” carries far less information than the citation sentences in the Arxiv graph, yet the benchmark treats both as equivalent instances of “edge text.” That asymmetry has downstream consequences for any model trained or evaluated on the full collection. Part 4 also examines the gap between the benchmark’s stated claims and its actual evaluation tasks, and revisits the structural inconsistencies documented in Part 1 and Part 2 to ask what they reveal about the dataset’s maturity.
References
[1] Li, Z., Gou, Z., Zhang, X., Liu, Z., Li, S., Hu, Y., Ling, C., Zhang, Z., & Zhao, L. (2024). TEG-DB: A Comprehensive Dataset and Benchmark of Textual-Edge Graphs. arXiv preprint arXiv:2406.10310. NeurIPS 2024 Datasets and Benchmarks Track.


