Kuzu’s Legacy and the New Wave of Embedded Graph Databases

Introduction
On October 10th, 2025, Kuzu’s GitHub repository was archived without warning. Four months later, a European Commission filing confirmed what most of the community had suspected: Apple had acqui-hired the team. The Verge (and many other outlets) ran the story. We won’t speculate on the future of Kuzu under Apple, but we can reflect on the history of the project, and the landscape it helped build for embedded graph databases.
Here’s a non-exhaustive list of embedded graph databases that share some similarity with Kuzu:
| Project | Relationship to Kuzu | Standout property | Status (May 2026) |
|---|---|---|---|
| LadybugDB | Community fork; gdotv’s pick to carry Kuzu forward | Active roadmap; stewardship by Arun Sharma | Actively developed |
| Lance Graph | Spiritual heir; Prashanth Rao (ex-Kuzu) at LanceDB | Graph workloads on the Lance columnar format | Active development inside LanceDB |
| Raphtory | Pre-dates Kuzu; same embedded ethos | Temporal and persistent graph as a first-class concept | Mature, actively developed |
| TuringDB | Same embedded ethos | Versioning as a first-class concept | Active development |
| FalkorDBLite | Same embedded ethos | Multiple graphs per database, Python-first | Active development |
The rest of this post explains each entry, what it inherits from Kuzu, and where the gaps are.
What is Kuzu
In short, Kuzu is an embedded graph database that uses columnar storage (and other techniques) to deliver high-performance graph analytical workloads as scale.
It’s a university spin-out project from the Data Systems Group at the University of Waterloo, led by Semih Salihoğlu with a broader founding team drawn from the same lab.
The project was introduced at CIDR 2023, with follow-up research on graph learning applications in openreview and on join algorithms in the ACM GRADES-NDA proceedings.
Kuzu’s strong academic foundation made it a truly bleeding-edge database project.
Kuzu has published several research papers over the years that laid the foundation of their database architecture:
- Vectorized and factorized query processing. Kuzu was a vectorized and factorized query processor. Factorization lets the engine represent intermediate results in compressed form rather than materializing every row, which is the load-bearing choice for analytical workloads.
- Columnar sparse row (CSR) adjacency lists. Kuzu used columnar sparse row-based (CSR) adjacency lists for its join indices. The choice has aged well. pgGraph, a Postgres extension launched in 2025, describes its own storage as “O(1) adjacency via CSR”, with
graph.build()compiling relationships into “forward and reverse compressed sparse row (CSR) edge stores”. Two projects, two slightly different framings of the same data structure. Convergent evolution in graph engine design. - Novel join algorithms. Kuzu’s join algorithms drew on worst-case-optimal join research from the same Waterloo lab, documented in the papers above.
The Kuzu team turned their theories to practice, and went from an ambitious research effort to a genuine challenger in the graph database industry.
The DuckDB of graph databases
The community gave Kuzu the nickname “the DuckDB of graph databases” early on. Kuzu deliberately aligned with what made DuckDB succeed, and adapted it to the constraints of graph workloads. The parallels are clear:
| Property | DuckDB | Kuzu |
|---|---|---|
| Written in C++ | ✓ | ✓ |
| Embedded, in-process execution | ✓ | ✓ |
| Single-file storage | ✓ | ✓ (since v0.11.0) |
| Native Parquet / Arrow / CSV / JSON ingestion | ✓ | ✓ |
| Attach extensions for external databases | ✓ | ✓ |
| WebAssembly bindings | ✓ (duckdb-wasm) | ✓ (kuzu-wasm) |
The detail on each:
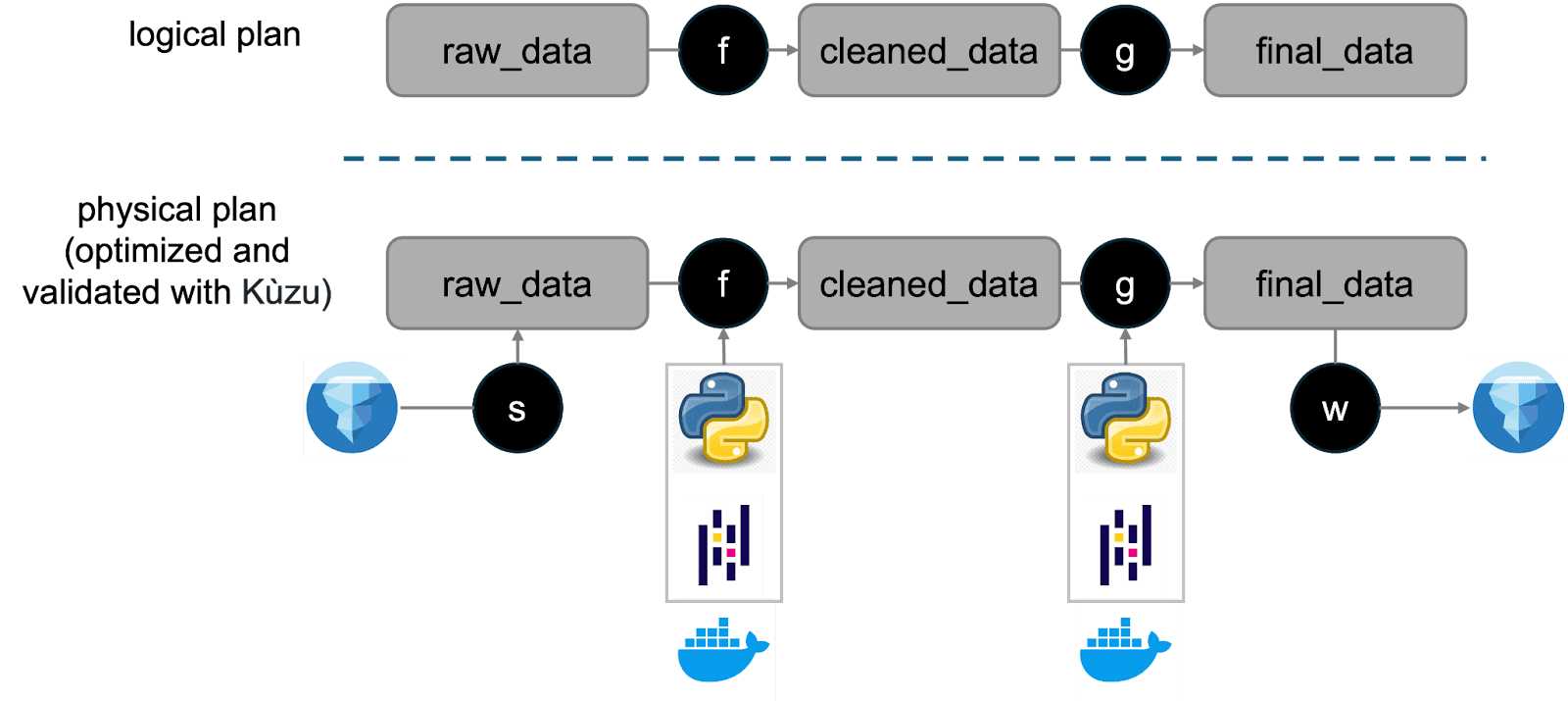
Embedded, in-process execution. DuckDB describes itself as a database that “does not run as a separate process, but completely embedded within a host process”. Kuzu took the same shape: embeddable and serverless, no service to deploy, no network hop, the database lives in the same process as your code.
Single-file storage. DuckDB’s native format is, per the same page, “a single-file database”. Kuzu moved to the same model in v0.11.0, consolidating its previous multi-file directory into a single data.kz artifact. The portability story is what you would expect: drop the file next to your code, ship it via object storage like AWS S3, mount it into a container, version it, hand it to a colleague.
Native multi-format ingestion. DuckDB reads Parquet, CSV, JSON, and Arrow data efficiently as a first-class concern. Kuzu adopted the same posture, reading Parquet, Arrow, CSV, and JSON natively without an ETL step.
Extensions for connecting to other databases. DuckDB has “a flexible extension mechanism that allows for dynamically loading extensions”, with extensions for Postgres, SQLite, and others. Kuzu adopted the same extension model: official extensions for attaching Postgres and DuckDB, plus Iceberg, Delta, HTTPFS, vector, and others in the extensions tree.
WebAssembly bindings. Both engines are written in C++, which makes compiling the database to WebAssembly straightforward. DuckDB ships duckdb-wasm and Kuzu shipped kuzu-wasm, letting you run the database in-process inside a browser. That unlocks client-side analytics: ship the database file alongside a static site, query it from JavaScript, never round-trip to a server.
The nickname described an alignment of philosophy, not a brand association, and LadybugDB has retained the positioning since the fork. On performance: thirty-hop path queries finishing in milliseconds, on real datasets we worked with at length. The nickname feels justified!
What Kuzu was used for in the wild
The above properties unlocked use cases that server-based graph databases were not built for. Three are worth highlighting.
Ephemeral graphs in data pipelines. Bauplan, the data-pipeline platform, published Ephemeral Graphs for Data DAGs in November 2024, co-authored with Semih Salihoğlu and Prashanth Rao from the Kuzu team. The framing in the post: “As every Bauplan run is an isolated end-to-end execution, planning graphs need to be instantiated only for the span of our checks … our ideal tool would allow ephemeral, in-memory graphs to be built, queried, and destroyed quickly.” The headline result, in Bauplan’s own words: “Leveraging Kùzu’s in-memory mode, creating a database with the relevant objects is a seamless operation; after its introduction, our planning became 20x faster.” Real-world DAGs in their environment routinely involved “more than 500 Cypher statements … executed by Kùzu in ~1.5 seconds”. That is what an embedded graph engine inside a data pipeline buys you.
A sample Bauplan workflow with ephemeral Kuzu graphs. Source: Bauplan Labs, used with attribution.
Agent and LLM context layers. Cognee was one of the early adopters of Kuzu for graph-based agent memory. The Cognee blog post that detailed the integration is no longer available, which is its own commentary on the cost of building on a vendor that has since archived. Our broader coverage of Cognee’s approach lives at Cognee: graphs that learn, and the pattern is now widespread enough that “embedded graph database for agent context” is a category in its own right.
Embedded graph databases as a context layer in agentic RAG systems. Source: Kuzu, used with attribution.
Portable shared context. A “Kuzu style” database is, operationally, an artifact you can ship next to your code, a directory pre-v0.11.0 and a single file thereafter. You can version it, hash it, hand it to someone over Slack, mount it into a container, attach it to a notebook. For inter-agent context exchange, or for an analyst handing a model to a colleague, that property does more work than its simplicity suggests.
LadybugDB: gdotv’s pick to carry Kuzu forward
In wake of Kuzu’s archival, gdotv is proud to pick up and ship support for successors like LadybugDB. The case for it rests on three things: stewardship, momentum, and direction.
LadybugDB is a community-driven fork of Kuzu under a permissive license, retaining the Cypher dialect, columnar storage, and the full-text plus vector indices that defined Kuzu’s last release. The shape is intentionally the same as Kuzu, because the goal is continuity for existing users, not a re-imagining.
What is new since the fork is more interesting. Three changes stand out, each one loosening a specific Kuzu-era constraint:
- Multiple labels per node. Kuzu’s node-table-per-label model bound each node to exactly one label, the most-cited gap when porting Neo4j models. LadybugDB now supports multi label patterns like
CREATE (p:Person:Employee:Manager {name: "Alice", id: 123}), which lets practitioners express type hierarchies (:Animal:Mammal:Dog), role combinations (:User:Premium:Admin), and state-plus-type modeling without flattening their data into separate tables. - No Copy External database support. Documented in Ladybug Spreading Its Wings (March 2026): “Full support for seamlessly integrating Arrow, DuckDB, and Parquet datasets is here. Rather than migrating or converting your external data into native Ladybug tables, you can simply attach these databases and query them directly”. This is the first concrete step toward the no-ingest architecture Arun has been describing publicly.
- Subgraph support. Same blog post: “Creating and querying multiple graph namespaces just got a whole lot easier with true subgraph support. You can now define isolated graphs and switch contexts natively” via
CREATE GRAPH my_graph ANYandUSE. Subgraphs are the operational complement to external sources: once you can attach external data and slice your graph cleanly, you have the primitives for the analytical workloads Kuzu was best at, without the migrate-everything-in step.
The broader vision behind these changes is on record in our Graph Chat interview with Arun Sharma, where he describes LadybugDB as the basis for a graph-specialized data lake, a “Snowflake for graphs”, with the elimination of ETL ingestion as a stated goal. External-database and subgraph support are the down-payment on that vision. Arun has the background for it: he led the Dragon distributed graph query system at Facebook before founding LadybugDB.
We were the first graph visualization tool to support LadybugDB. The integration is live today, and you can point gdotv at a LadybugDB file the same way you used to point it at a Kuzu file.
Spiritual successors and adjacent ideas
LadybugDB is the direct continuation. A separate group of projects carries Kuzu’s ideas, embedded execution, columnar-friendly storage, Cypher or an equivalent, portable single-file or single-directory artifacts, into adjacent design spaces. None of them replaces Kuzu, but each pushes the category somewhere worth knowing about.
Raphtory
![]()
Source: Raphtory, used with attribution.
Raphtory pre-dates Kuzu’s heyday and is sometimes overlooked. Its distinctive contribution is treating time as a first-class concept: a Graph exposes a stream-of-events view, a PersistentGraph exposes the same data “as persistent state over a duration of time”, and you switch between representations with .event_graph() or .persistent_graph(). If time-evolving graphs are your primary workload, Raphtory is the embedded option built for it.
Lance Graph
![]()
Source: LanceDB, used with attribution.
Lance Graph is active development inside LanceDB. There is no shipped product page yet, but the signal worth watching is that Prashanth Rao, formerly of Kuzu, joined the LanceDB team after the archival, and early experimentation lives in his graph-benchmark repo. The premise is graph workloads on the Lance columnar format. The benchmark itself is exactly what it says it is, a personal benchmark, not a vendor product page. Treat the numbers as indicative; workload shape, write patterns, and operational fit usually matter more than micro-benchmarks for a “which engine should I use” decision.
TuringDB
![]()
Source: TuringDB, used with attribution.
TuringDB describes itself as “a blazing-fast, in-memory graph database engine purpose-built for analytics and AI” with a distinctive versioning model: “Versioning should be native … commit, branch, merge, and time-travel your data … every change is an immutable commit, like Git for your graphs”. For analytical workloads where reproducibility matters, branch-per-experiment is a useful primitive that Kuzu did not natively offer.
FalkorDBLite
![]()
Source: FalkorDB, used with attribution.
FalkorDBLite is the embeddable, Python-friendly variant of FalkorDB, with the distinctive property of supporting multiple separate graphs inside one database. If you need the embedded property plus multi-graph isolation in the same artifact, FalkorDBLite is the option built for it.
There are other projects in this category that this post does not cover. A fuller embedded-graph-database roundup is on our list for a future piece.
Where can Kuzu users go to next
No single project is a drop-in for Kuzu. LadybugDB is definitely the closest match on shape, license posture, and ongoing direction. The migration is also pretty straightforward – just run EXPORT from Kuzu, and IMPORT from LadybugDB. The other projects we’ve discussed above carry similar tones and ideas to Kuzu. If you are evaluating “what next” from a working Kuzu codebase, that is the order to look in.
Kuzu’s exit raises a difficult question: how can successful open source databases achieve durable governance and commercial sustainability? This applies to open source in general, and it’s a known challenge that Kuzu gave a reminder of.
Kuzu’s commercial strategy was opaque enough that the archival caught most of its users by surprise. The successor projects are aware of this, and the open governance and permissive licensing posture they have adopted is a direct response. Whether that posture survives contact with the same commercial pressures remains to be seen.
Independent of where the team ended up, Kuzu changed what people expected from a graph database. The combination of embedded execution, columnar storage, Cypher, and single-file portability is no longer just a nice to have. Kuzu raised the bar for the industry, and that is their true legacy. The successors above are not Kuzu, but they exist because Kuzu showed what was possible, and that is more than most projects manage in the time they get.
If you are working with LadybugDB and want a graph IDE alongside it, gdotv is ready.


